AAAI2021 | 学习预训练图神经网络

题目:Learning to Pre-train Graph Neural Networks
会议:AAAI 2021
论文代码:https://github.com/rootlu/L2P-GNN
1 概览
图神经网络(GNN)已经成为图表示学习的事实标准,它通过递归地聚集图邻域的信息来获得有效的节点表示。尽管 GNN 可以从头开始训练,但近来一些研究表明:对 GNN 进行预训练以学习可用于下游任务的可迁移知识能够提升 SOTA 性能。但是,传统的 GNN 预训练方法遵循以下两个步骤:
-
在大量未标注数据上进行预训练; -
在下游标注数据上进行模型微调。
由于这两个步骤的优化目标不同,因此二者存在很大的差距。
在本文中,我们分析了预训练和微调之间的差异,并为了缓解这种分歧,我们提出了一种用于GNNs的自监督预训练策略L2P-GNN。方法的关键是L2P-GNN试图以可转移的先验知识的形式学习如何在预训练过程中进行微调。为了将局部信息和全局信息都编码到先验信息中,我们在节点级和图级设计了一种双重自适应机制。最后,我们对不同GNN模型的预训练进行了系统的实证研究,使用了一个蛋白质数据集和一个文献引用数据集进行了预训练。实验结果表明,L2P-GNN能够学习有效且可转移的先验知识,为后续任务提供好的表示信息。我们在https://github.com/rootlu/L2P-GNN公开了模型代码,同时开源了一个大规模图数据集,可用于GNN预训练或图分类等。
总体来说,本文的贡献如下:
-
首次探索学习预训练 GNNs,缓解了预训练与微调目标之间的差异,并为预训练 GNN 提供了新的研究思路。 -
针对节点与图级表示,该研究提出完全自监督的 GNN 预训练策略。 -
针对预训练 GNN,该研究建立了一个新型大规模书目图数据,并且在两个不同领域的数据集上进行了大量实验。实验表明,该研究提出的方法显著优于 SOTA 方法。
2 模型
2.1 自监督模型
L2P-GNN的核心是学习预训练 GNN 以缓解预训练与微调过程之间的差距。具体地说,我们的方法可以表述为元学习MAML的一种形式。为此,我们将任务定义为从局部和全局的角度捕获图中的结构和属性。然后,元学习得到的先验可以适应于新的任务/图。
任务构建. 将一组图作为训练前的数据 ,一个任务 涉及一个图 ,由支持集 和查询集 组成。我们通过梯度下降更新之后(与支持集上的损失有关),优化查询集上的性能,从而模拟了微调中的训练和测试,以此学习可迁移的先验知识。
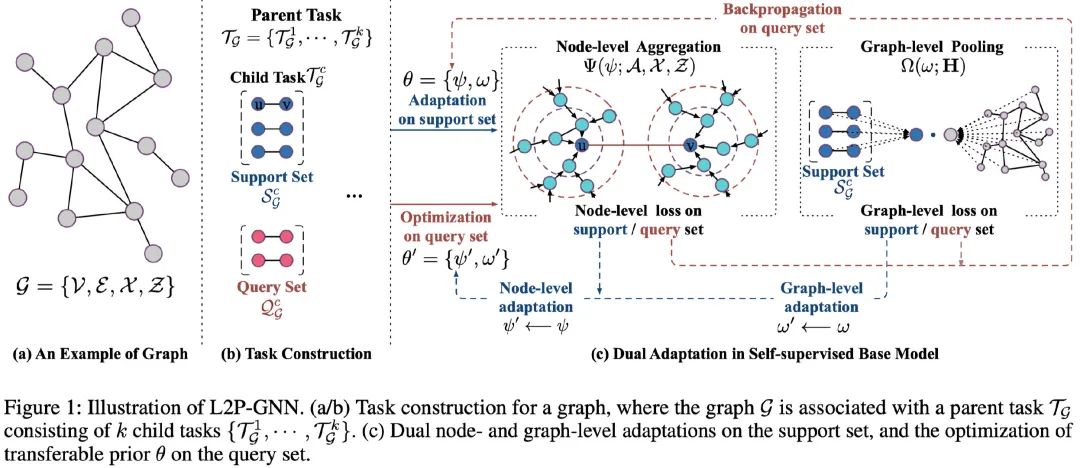
基础 GNN 模型. 对于给出的父任务与子任务,该研究设计了一个具有节点级聚合和图级池化的自监督 GNN 模型,旨在将节点级和图级的无标签图数据的内在结构作为自监督信号。模型的关键在于,利用无标签图数据的内在结构在节点和图层次上进行自我监督。具体地说,基本模型
涉及节点级别聚合
,其聚合节点信息(例如,局部结构和特征信息)生成节点表示,以及图级别池化
进一步生成图的表示。
2.2 双重适应
为了缩小预训练和微调过程之间的差距,在预训练过程中优化模型快速适应新任务的能力是至关重要的。为此,该研究提出学习基础 GNN 模型的预训练,旨在学习可迁移的先验知识,提供可适应的初始化,以便快速针对具有新图数据的新型下游任务进行微调。具体而言,学习到的初始化不仅对节点对之间的局部连通性进行编码和调整,还能够泛化到图的不同子结构。相应地,该研究设计了节点和图级双重适应,如图 1(c) 所示。
节点级适应. 为了模拟在下游训练集合上的微调,我们在支持集上训练损失函数,然后基于损失函数进行节点级适应,从而得到适应后的先验知识 。
图级适应. 为了编码如何池化节点信息,从而表示一整张图,我们将图级池化先验知识 适应到具体任务上,从而得到适应后的先验知识:
先验知识的优化. 经过节点级和图级自适应后,我们已经将全局先验知识 适配为任务特定的知识 。为了模拟微调模型的测试过程,通过优化适配后的参数在查询集上的表现,基础GNN模型得以训练。即,可迁移的先验知识 可以通过在查询loss上的反向传播得到优化:
3 实验
3.1 性能比较
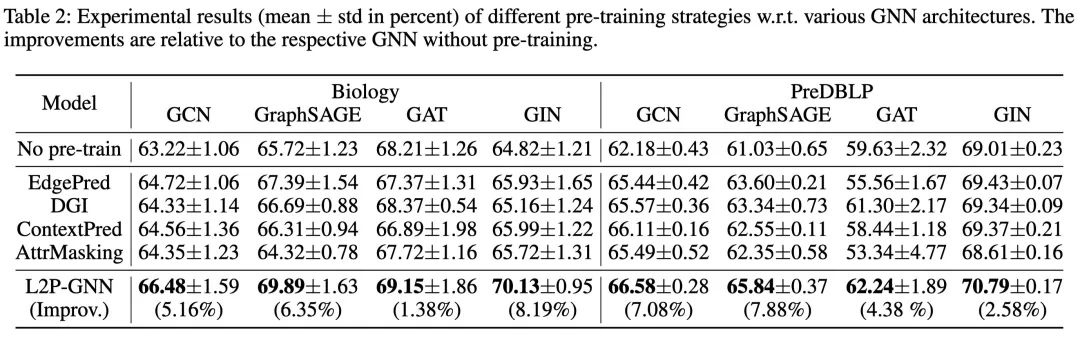
上表对比了 L2P-GNN 和 SOTA 预训练基线(4 种不同的 GNN 结构)的性能,得到了以下发现:
-
总体而言,在不同GNN结构的所有方法中,L2P-GNN 始终表现最优。与每种结构的最佳基线相比,L2P-GNN 在两个数据集上分别实现了高达 6.27% 和 3.52% 的提升。我们认为显著的的性能提升归功于预训练过程中的微调模拟,缩小了预训练和微调目标之间的差距。 -
此外,使用大量未标注数据对 GNN 进行预训练显然对下游任务有所帮助。因为相比于在两个数据集上未经过预训练的模型,L2P-GNN 分别带来了 8.19% 和 7.88% 的增益。 -
同时我们还注意到,一些基线(即使用 EdgePred 和 AttrMasking 策略的 GAT 模型)在下游任务中的性能提升极为有限,并在下游任务上产生了负迁移。原因可能是这些策略学习的信息与下游任务无关,因而不利于预训练 GNN 的泛化。这一发现也证实了先前的观察结果,即负迁移会限制预训练模型的使用性和可靠性。
3.2 模型分析
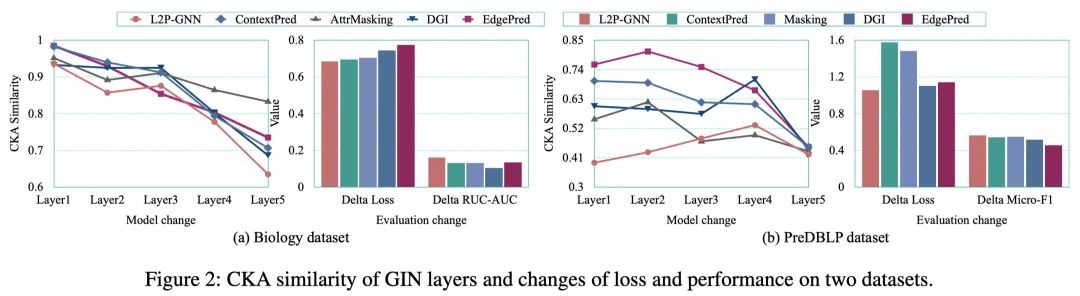
比较分析. 我们尝试对预训练GNN模型进行了下游任务微调前后的对比分析,以验证L2P-GNN是否缩小了预训练和微调之间的差距。如图 2 所示,微调前后 L2P-GNN 参数的 CKA 相似性通常小于基线,这表明 L2P-GNN 经历了更大的变化,从而更加适应下游任务。
消融分析
此外,由于节点、图级双重适应在 L2P-GNN 中非常重要,该研究比较了两种变体:L2P-GNN-Node(只有节点级适应)和 L2P-GNN-Graph(只有图级适应)。如图 3(a) 所示,在两个数据集上的结果表明 L2P-GNN 优于这两个变体。这说明,局部节点级结构和全局图级信息都是有用的,有利于进行联合建模。
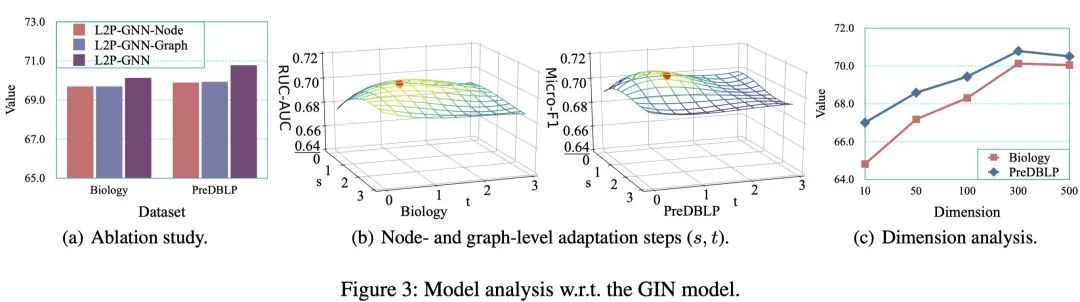
参数分析
最后,该研究总结了维度的影响如图 3(c) 所示。当维度在 300 维时,L2P-GNN 性能达到最优,并且在最优设置附近基本稳定,这说明 L2P-GNN 在维度表示方面具有鲁棒性。
4 总结
在本文中,我们介绍了L2P-GNN,一种自监督的GNN预训练策略。我们发现,在传统的预训练策略下,预训练目标与微调目标之间存在偏差,导致预训练GNN模型不是最优的。为了通过学习如何对GNN进行预训练来缩小差距,L2P-GNN通过在预训练过程中模拟对下游任务的微调,从而直接优化预训练模型对下游任务的快速适应能力。在节点级和图级,L2P-GNN具有双重自适应,利用无标签图数据的内在结构作为自监督信息,同时学习局部和全局表示。大量的实验表明,L2P-GNN显著优于当前的最优基线,并有效地缩小了训练前和微调之间的差距。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LPGNN” 可以获取《AAAI2021 | 学习预训练图神经网络》专知下载链接索引