【问答系统】QA问答系统(Question Answering)
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要18分钟
跟随小博主,每天进步一丢丢


来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/61914325
作者 | 浪大大
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
问答领域是自然语言处理中很重要的一个领域
大多数问答系统关注的是真凭实据的问题,这些问题可以用简短的文本表达简单的事实来回答。以下问题的答案可以用个人姓名、时态或地点来表达:
(23.1) Who founded Virgin Airlines?
(23.2) What is the average age of the onset of autism?
(23.3) Where is Apple Computer based?事实问题回答的两个主要范例。信息检索或基于IR的问题回答依赖于网络上或PubMed等集合中的大量文本信息。给定用户问题,信息检索技术首先找到相关文档和段落。然后系统(基于特征,神经或两者)使用阅读理解算法来读取这些检索到的文档或段落,并直接从文本跨度中得出答案。
在第二个范例中,基于知识的问题回答,系统构建查询的语义表示,映射“What states border Texas?逻辑表示为:
总结下就是两个部分:
查找包含答案的文档:它可以通过传统的信息检索/网络搜索来处理。
在段落或文件中找到答案:这个问题常被称为阅读理解。这就是我们今天要关注的。
最后,像IBM的Watson中的DeepQA系统这样的大型工业系统通常是混合的,使用文本数据集和结构化知识库来回答问题。DeepQA在知识库和文本源中找到许多候选答案,然后使用地理空间数据库、分类分类或其他文本源等知识源为每个候选答案打分。在下一节中,我们将介绍基于IR的方法(包括神经阅读理解系统),然后是基于知识的系统、沃森深度QA和评估讨论。
IR(信息检索)-based Factoid Question Answering
基于信息检索的问题回答的目的是通过在web或其他文档集合中查找短文本段来回答用户的问题。图23.1显示了一些示例的factoid问题及其答案

图23.2展示了一个基于ir的factoid问答系统的三个阶段:问题处理、文章检索和排序以及答案提取
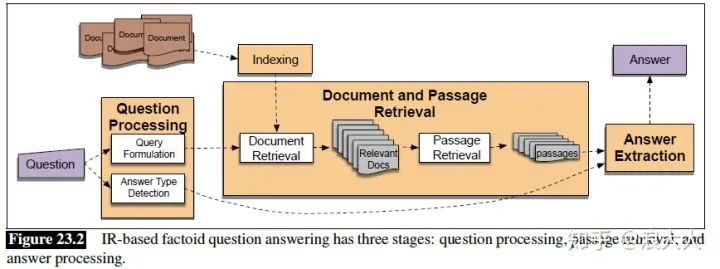
Question Processing
问题处理阶段的主要目标是提取查询:将关键字传递给IR系统以匹配潜在的文档。有些系统还提取进一步的信息,例如:
answer type:答案的实体类型(人、位置、时间等)
focus:问题中可能被任何找到的答案字符串替换的单词字符串(关键字)
question type:这是定义问题、数学问题、列表问题吗?
例如,对于Which US state capital has the largest population?查询处理可能会产生:
query: “US state capital has the largest population”
answer type: city
focus: state capital接下来,我们将总结两个最常用的任务,查询公式和答案类型检测。
Query Formulation
Query Formulation的任务是创建一个查询,其中包含一系列要发送到信息检索系统的令牌,以便检索可能包含回答字符串的文档。对于web上的问题回答,我们可以简单地将整个问题传递给web搜索引擎,最多可以省略问题单词(where, when,等等)。
对于来自更小的文档集的问题回答,如企业信息页面或Wikipedia,我们仍然使用IR引擎来索引和搜索我们的文档,通常使用标准的tf-idf余弦匹配,但是我们可能需要做更多的处理。例如,对于搜索Wikipedia,它可以帮助在查询和文档中以双图而不是单图计算tf-idf 。或者,我们可能需要进行查询扩展,因为在web上,一个问题的答案可能以许多不同的形式出现,其中一个可能与另一个问题匹配,在较小的文档集中,一个答案可能只出现一次。查询扩展方法可以添加查询术语,希望与出现的答案的特定形式匹配,比如添加问题中内容词的形态学变体,或者来自同义词库的同义词。
有时用于查询web的Query Formulation方法是将查询重公式规则应用于查询。规则将问题重新措辞,使其看起来像可能的声明性答案的子字符串。“when was the laser invented?”可以重新表述为“the laser was invented”;“where is the Valley of the Kings?”如“the Valley of the Kings is located in”。以下是的一些手写的重新制定规则的例子:
wh-word did A verb B! . . .A verb+ed B
Where is A! A is located inAnswer Types
一些系统利用问题分类,找到答案类型的任务,命名实体对答案进行分类。像“Who founded Virgin Airlines?”的问题,期待PERSON类型的答案。像“What Canadian city has the largest population?”的问题, 期待CITY类型的答案。如果我们知道问题的答案类型是一个人,我们可以避免检查文档集中的每个句子,而是关注提及人的句子。
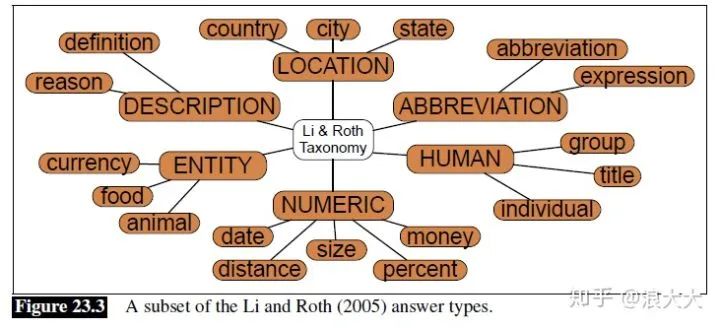
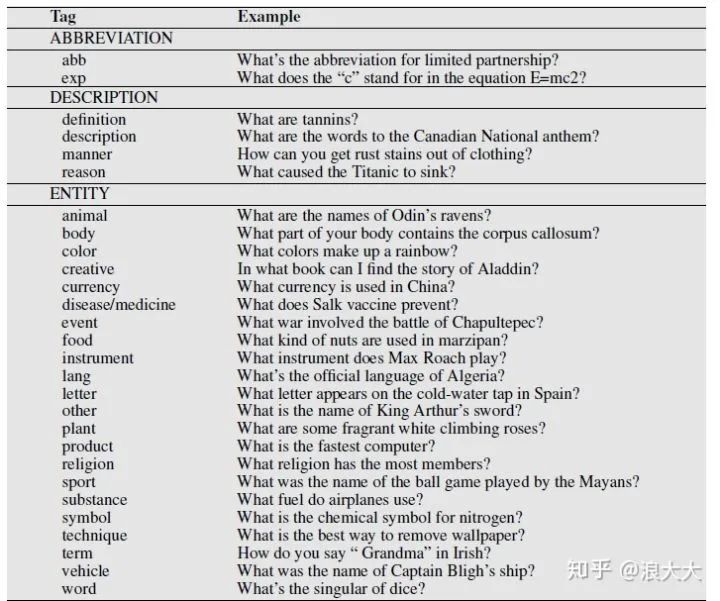
虽然回答类型可能只是人名、位置和组织之类的命名实体,但是我们也可以使用一组更大的层次结构的回答类型,称为回答类型分类法。这些分类法可以通过WordNet等资源自动构建,也可以手工设计。图23.4显示了这样一个手工构建的本体,Li和Roth标记集;图23.3还显示了一个子集。在这个分层的标记集中,每个问题都可以使用粗粒度标记(如HUMAN)或细粒度标记(如HUMAN:DESCRIPTION、HUMAN:GROUP、HUMAN:IND)等。描述类型通常被称为传记问题,因为答案需要给出一个人的简短传记,而不仅仅是一个名字。问题分类器可以通过手工编写规则来构建,比如以下来自(Hovy et al., 2002)的规则,用于检测答案类型传记
who {is | was | are | were} PERSON然而,大多数的问题分类器都是基于监督学习的,它们都是在手工标注答案类型的问题数据库上训练的。可以使用基于特征的方法或神经方法。基于特征的方法依赖于问题中的单词及其嵌入、每个单词的词性以及问题中的命名实体。通常,问题中的一个单词提供关于答案类型的额外信息,并将其标识用作一个特性。这个词有时被称为答案类型词或问题词头词,可以定义为问题后的第一个NP词头词;在下面的例子中,标题词用黑体字表示

一般来说,对于简单的问题类型,如人物、地点、时间等,问题分类的准确率较高;检测的原因和描述问题可能要难得多。

文档及段落检索
从问题处理阶段生成的IR查询被发送到IR引擎,生成一组文档,根据它们与查询的相关性进行排序。因为大多数抽取答案的方法都是针对小区域(如段落)而设计的,所以QA系统接下来会将前n个文档分成更小的段落(如段落、段落或句子)。这些可能已经在源文档中分段,或者我们可能需要运行段落分段算法。
然后,最简单的段落检索形式就是将每个段落都传递到答案提取阶段。一个更复杂的变体是通过对检索到的段落运行命名实体或回答类型分类来过滤这些段落。不包含分配给问题的答案类型的段落将被丢弃。
也可以使用监督学习来对剩余的段落进行全面排名,使用如下功能:
文章中正确类型的命名实体的数量
文章中问题关键词的数量
文章中出现的最长的准确的问题关键字序列
摘录这篇文章的文件的等级
关键字之间的相似性
文章和问题之间重叠的n-gram数
对于来自web的问题回答,我们可以从web搜索引擎中提取片段作为段落。
答案抽取
回答问题的最后一个阶段是从文章中提取一个特定的答案,例如回答答案为:29,029 feet的问题“珠穆朗玛峰有多高?”这个任务通常由span标记来建模:给定一段,确定组成答案的文本的span。
提取答案的一个简单基线算法是在候选通道上运行一个命名实体标记器,并返回正确答案类型在通道中的任何跨度。因此,在下面的例子中,划线的命名实体将从段落中提取出来,作为“HUMAN”和“DISTANCE-QUANTITY”问题的答案

不幸的是,许多问题的答案,例如定义问题,往往不是特定的命名实体类型。因此,现代的答案提取工作使用了更复杂的算法,通常基于监督学习。下一节将介绍一个简单的基于特征的分类器,然后我们将讨论现代神经算法。
基于特征的答案抽取
有监督学习方法的答案提取训练分类器,以确定一个span或一个句子是否包含一个答案。一个明显有用的特性是上述基线算法的答案类型特征。手写的正则表达式模式也发挥了作用,例如图23.6中定义问题的示例模式

这类分类器中的其他特性包括:
答案类型匹配:如果候选答案包含具有正确答案类型的短语,则为True。
模式匹配:匹配候选答案的模式的标识。
匹配的问题关键字数量:候选答案中包含多少个问题关键字。
关键字距离:候选答案与查询关键字之间的距离
新颖因素:如果候选答案中至少有一个单词是新颖的,即不在查询中,则为真
同位语特征:如果候选答案与包含许多问题术语的短语相对应,则为True。可以通过最多三个单词和一个逗号与候选答案分开的问题术语的数量来近似
标点位置:如果考生的答案后面紧跟着逗号、句号、引号、分号或感叹号,则为真。
问题术语序列:候选答案中出现的最长问题术语序列的长度。
N-gram tiling answer extraction
另一种仅用于Web搜索的答案提取方法是基于n-gram平铺,这种方法依赖于Web的冗余。这种简化的方法首先从Web搜索引擎返回的代码片段开始,这些代码片段由重新构造的查询生成。在第一步,n-gram挖掘中,提取片段中出现的每个一元、二元和三元图并对其进行加权。权重是发生n-gram的代码片段的数量和返回它的查询重新制定模式的权重的函数。在n-gram筛选步骤中,n-gram的得分取决于它们与预测答案类型的匹配程度。这些分数是通过为每种答案类型构建的手写过滤器计算的。最后,一个n-gram平铺算法将重叠的n-gram片段连接成更长的答案。一个标准的贪心方法是从得分最高的候选答案开始,然后尝试用这个候选来平铺其他候选。将得分最高的连接添加到一组候选项中,删除得分较低的候选项,然后继续这个过程,直到构建一个答案为止。
Neural Answer Extraction
神经网络方法提取答案的直觉是,一个问题和它的答案在语义上以某种适当的方式相似。我们将看到,这种直觉可以通过计算问题的嵌入和文章每个标记的嵌入来充实,然后选择嵌入最接近问题嵌入的段落跨度。
阅读理解的数据集:因为神经回答抽取器通常是在阅读理解任务的上下文中设计的,所以让我们从这个任务开始。Hirschman等人首次提出采用儿童阅读理解测试教学工具,让儿童阅读一篇文章,必须回答有关文章的问题,并用这些问题来评估机器文本理解算法。他们收集了120篇文章的语料库,每篇文章有5个问题,每个问题都是为3 -6年级的孩子设计的。他们建立了一个答案提取系统,并测量了他们的系统给出的答案与测试发布者给出的答案的对应程度。
现代阅读理解系统倾向于使用专门为NLP设计的问题集合,因此对于训练监督学习系统来说足够大。例如,斯坦福问答数据集由来自维基百科的文章和答案跨越文章的相关问题组成,以及一些设计为无法回答的问题(Rajpurkar et al. 2016, Rajpurkar et al. 2018);总共有超过15万个问题。图23.7显示了一个摘自SQUAD 2.0文章的摘要,以及三个问题和它们的答案span。

“SQuAD的建立是通过让人们为给定的维基百科文章写问题,并选择答案范围。其他数据集使用了类似的技术;NewsQA数据集由10万对来自CNN新闻文章的问答对组成,对于其他数据集,如WikiQA,跨度是包含答案的整个句子;选择一个句子而不是一个更小的答案跨度的任务有时被称为句子选择任务。
这些阅读理解数据集本身既可作为阅读理解任务使用,也可作为开放式问题回答算法句子提取组件的训练集和评价集使用。
基本的阅读理解算法。用于阅读理解的神经算法给出问题q的l个标记 




图23.8为Chen等人(2017)的DrQA系统的文档阅读器组件架构。像大多数这样的系统一样,DrQA为问题构建一个嵌入,为文章中的每个标记构建一个嵌入,计算上下文中问题和每个文章单词之间的相似性函数,然后使用问题-文章相似性评分来决定答案跨度的起点和终点。
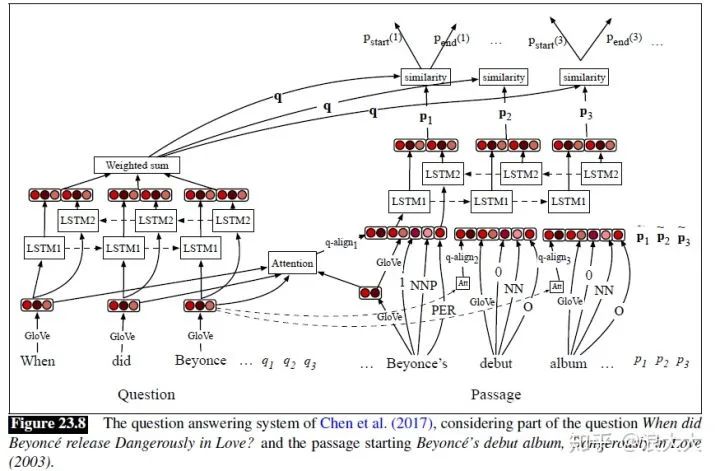
让我们按照Chen等人(2017)的描述来详细考虑算法。问题由单个嵌入的q表示,它是每个问题单词qi的加权表示和。(如图23.8所示的bi-LSTM)它通过RNN传递问题词的一系列嵌入 


权值bj是衡量问题中每个词的相关度,它依赖于一个习得的权值向量w:

为了计算段落嵌入 

每个单词
的嵌入,如来自GLoVE
标记特性,如
的词性部分,或
的命名实体标记,来自运行POS或NER标记器
精确匹配特征表示文章单词
是否出现在问题中:
。标记的大小写形式可以使用单独的精确匹配特征。
对齐的问题嵌入:除了精确的匹配功能之外,许多QA系统使用注意机制来提供文章和问题单词之间更复杂的相似性模型,比如相似但不完全相同的单词,比如release和single。例如,可以使用加权相似度
,其中注意权重
编码
与每个问题单词
之间的相似度。attention weight可以计算为函数α之间的点积:
,
可以是一个简单的前馈网络
 的嵌入,如来自GLoVE
的嵌入,如来自GLoVE 。
。 ,其中注意权重
,其中注意权重  编码
编码  之间的相似度。attention weight可以计算为函数α之间的点积:
之间的相似度。attention weight可以计算为函数α之间的点积:  ,
, 可以是一个简单的前馈网络
可以是一个简单的前馈网络然后将 

前两个步骤的结果是,一个问题嵌入了q和文章 


这些神经回答提取器可以通过像SQuAD这样的数据集进行端到端的训练。
目标函数:

Knowledge-based Question Answering
虽然web上大量的文本编码了大量的信息,但信息显然也以更结构化的形式存在。我们使用基于知识的问题回答这个术语,是为了通过将自然语言问题映射到结构化数据库上的查询来回答这个问题。就像基于文本的问题回答范例一样,这种方法可以追溯到自然语言处理的早期,使用棒球等系统回答棒球比赛和统计数据的结构化数据库中的问题。将文本字符串映射到任何逻辑形式的系统称为语义分析器。用于回答问题的语义分析器通常映射到谓词演算的某个版本或查询语言(如SQL或SPARQL),如图23.9中的示例所示。

因此,问题的逻辑形式可以是查询形式,也可以很容易地转换成查询形式。数据库可以是完整的关系数据库,也可以是更简单的结构化数据库,如RDF三元组集。RDF三元组是一个三元组,一个带有两个参数的谓词,表示一些简单的关系或命题。像Freebase (Bollacker et al., 2008)或DBpedia (Bizer et al., 2009)这样的流行本体有大量来自Wikipedia信息框的三元组,这些信息框是与特定Wikipedia文章关联的结构化表。以知识为基础的问题回答任务最简单的形式是回答关于三元组中缺失的一个参数的事实性问题。考虑如下所示的RDF三元组:

这个三元组可以用来回答文本问题,比如‘When was Ada Lovelace born?’ or ‘Who was born in 1815?'。在这个范例中,回答问题需要从文本字符串映射,比如”When was ... born”在知识基础上的规范关系,如出生年份。我们可以把这个任务概括为:
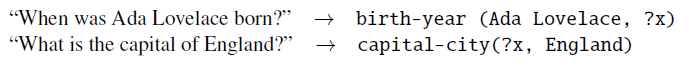
基于规则的方法
对于非常频繁的关系,可能值得编写从问题中提取关系的手写规则,例如,要提取出生年份关系,我们可以编写模式来搜索疑问词When、一个像born这样的主要动词以及提取动词的命名实体参数。







