【学界】谷歌大脑提出Adversarial Spheres:从简单流形探讨对抗性样本的来源
选自arXiv
来源:机器之心
近日,Ian Goodfellow 等人提出对抗性同心高维球,他们利用数据流形的维度来研究输入维度的改变对神经网络泛化误差的影响,并表明神经网络对小量对抗性扰动的脆弱性是测试误差的合理反应。
已经有大量工作证明,标准图像模型中存在以下现象:绝大多数从数据分布中随机选择的图片都能够被正确分类,但是它们与那些被错误分类的图片在视觉上很类似(Goodfellow et al., 2014; Szegedy et al., 2014)。这种误分类现象经常被称作对抗样本。这些对抗的错误在角度、方向和缩放方面有着很强的鲁棒性(Athalye & Sutskever, 2017)。尽管已经有了一些理论工作和应对的策略 (Cisse et al., 2017; Madry et al., 2017; Papernot et al., 2016),但是这种现象的成因仍然是很难理解的。
目前有一些针对对抗样本而提出的假设:一个比较常见的假设就是神经网络分类器在输入空间中不同区域的线性特征太强了 (Goodfellow et al., 2014; Luo et al., 2015)。另一个假设认为对抗样本不是数据的主要部分 (Goodfellow et al., 2016; Anonymous, 2018b,a; Lee et al., 2017)。Cisse 等人则认为,内部矩阵中较大的奇异值会让分类器在面临输入中的小波动时变得更加脆弱(2017)。
在尽力解释对抗样本背后的原因时,还有一些工作为增加模型的鲁棒性提出了一些应对方法。有的工作通过改变模型所用的非线性变换来增强鲁棒性 (Krotov & Hopfield, 2017),将一个大型的网络提炼成一个小型网络 (Papernot et al., 2016),或者使用正则化 (Cisse et al., 2017)。其他的工作探索使用另一个统计模型来检测对抗样本((Feinman et al., 2017; Abbasi & Gagné, 2017; Grosse et al., 2017; Metzen et al., 2017))。然而,很多这种方法都被证明是失败的 l (Carlini & Wagner, 2017a,b)。最终,很多例子中出现了使用对抗训练来提升鲁棒性的方法 (Madry et al., 2017; Kurakin et al., 2016; Szegedy et al., 2014; Goodfellow et al., 2014)。尽管对抗训练使得模型在面临对抗扰动时有所进步,但是在超越对抗训练所设计的范围时,局部误差还是会出现(Sharma & Chen,2017)。
这种现象特别有趣,因为这些模型在测试集上具有很高的准确率。我们假设这种现象本质上是由数据流形的高维度造成的。为了着手研究这些假设,我们定义了一个简单的合成任务,来区分两个同心的(concentric)高维球。这使得我们可以研究具有良好数学定义的数据流形中的对抗样本,我们还可以对模型学到的决策边界进行定性地描述。更重要的是,我们可以自然地改变数据流形的维度来研究输入维度的改变对神经网络泛化误差的影响。我们在多个数据集上的实验和理论分析证明以下几点:
与图像模型中类似的现象出现了:大多数从数据分布中随机选择的点被正确分类了,然而未被正确分类的点和不正确的输入很「相近」。即使在测试误差小于百万分之一的时候,这种现象仍然会发生。
在这个数据集中,泛化误差和最近误分类点之间的平均距离存在一个权衡。尤其是,我们证明,任何一个能够将球体的少量点误分类的模型都会在面临 O(1 square root d) 大小的对抗扰动时表现得很脆弱。
在这个数据集上训练得到的神经网络顺理成章地逼近误差集合最近误差平均距离的理论最优的权衡。这表明,为了线性地增加到最近误差的平均值,模型的错误率必须指数降低。
我们还证明,即使忽略掉大部分的输入,在在这个数据集上训练的到的模型也能够达到极高的准确率。
下面,我们探讨一下高维球中的对抗样本和图像模型中的对抗样本之间的联系:
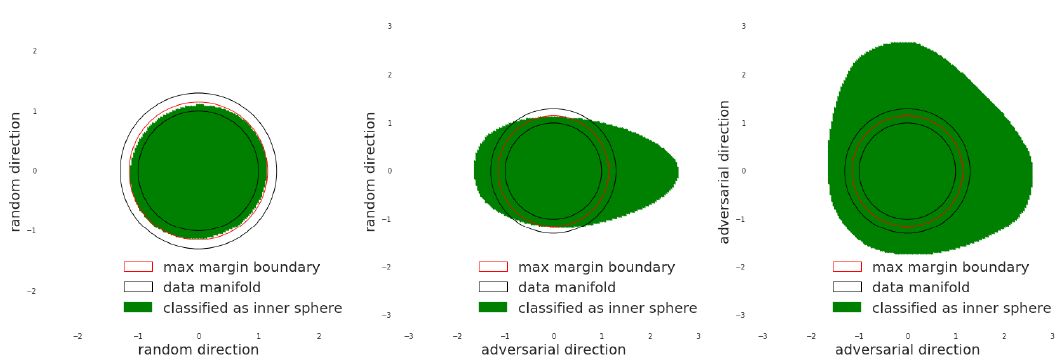
图 1:输入空间的二维切面。左边:两个随机方向;中间:一个随机方向,一个「对抗」方向;右边:两个正交的「对抗方向」。数据流形用黑色标记,最大边界用红色标记。绿色的区域表示被 relu 网络归类为球内的数据点。在最后一张图中,即使模型的错误率低于十万分之一,但是球外数据点的映射还是被错误地分类了。
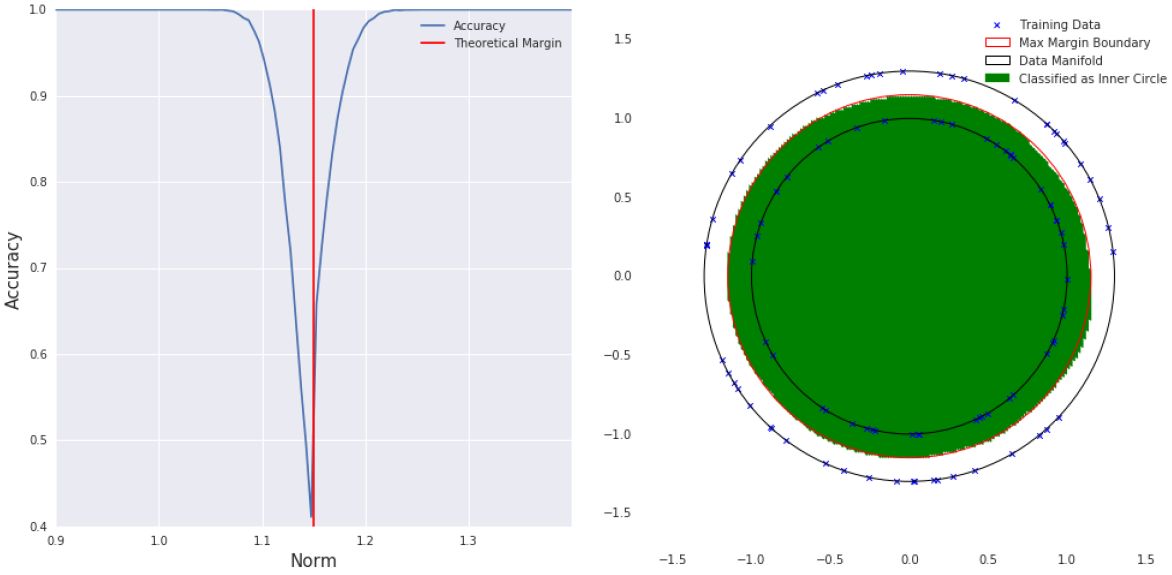
图 2:左:两个在 ReLU net 上基于 5 千万样本从半径为 1.0 和 1.3 的高维球上训练的结果。我们使用 1.15 的理论决策边界评价了整个空间中的准确率。我们画出了每一个范数在 10000 个随机样本上的准确率。可以发现,随着远离理论边界,准确率剧烈上升。当我们离理论边界足够远的时候,再也没有观察到随机样本的错误。然而,我们即便已经远离理论边界 0.6 或者 2.4,我们还是可以发现「误差」。右:d=2 的情况下,我们在 100 个样本上训练了同样的 reLU 网络。通过对整个空间的一个稠密子集的可视化,结果显示模型在两个圆中都没有出现错误。
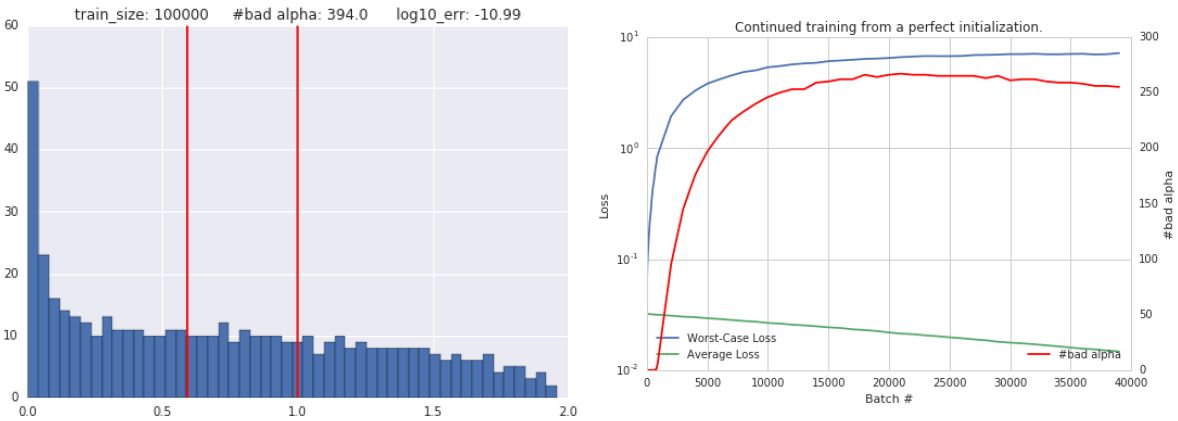
图 3:左:二次网络在 10 万个样本上进行训练之后α的分布。红色的线条代表完美分类所需的区间。尽管在绝大多数α下只有 1e-11 比例的样本被误分类了。右边:二次网络使用没有错误的完美初始化之后的训练曲线。随着训练的进行,平均样本损失会在非常差的样本损失下达到最小化。错误数量α在以相似的速率增加。
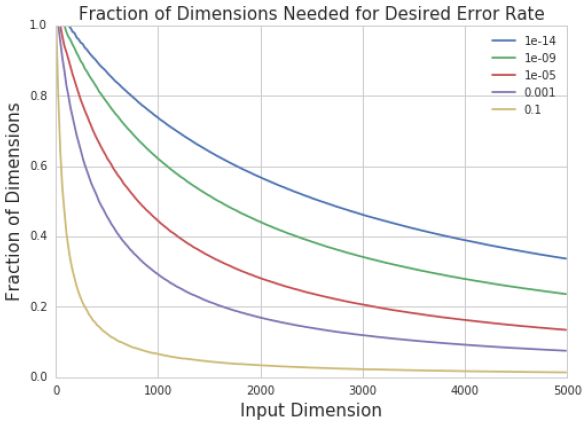
图 4:我们将输入维度为 d 的样本投影到 k 维子空间中的分类模型。然后我们绘制为了得到确定的错误率所需要的 k/d 的图形。我们发现,随着 输入维度的增加,k/d 快速减小。
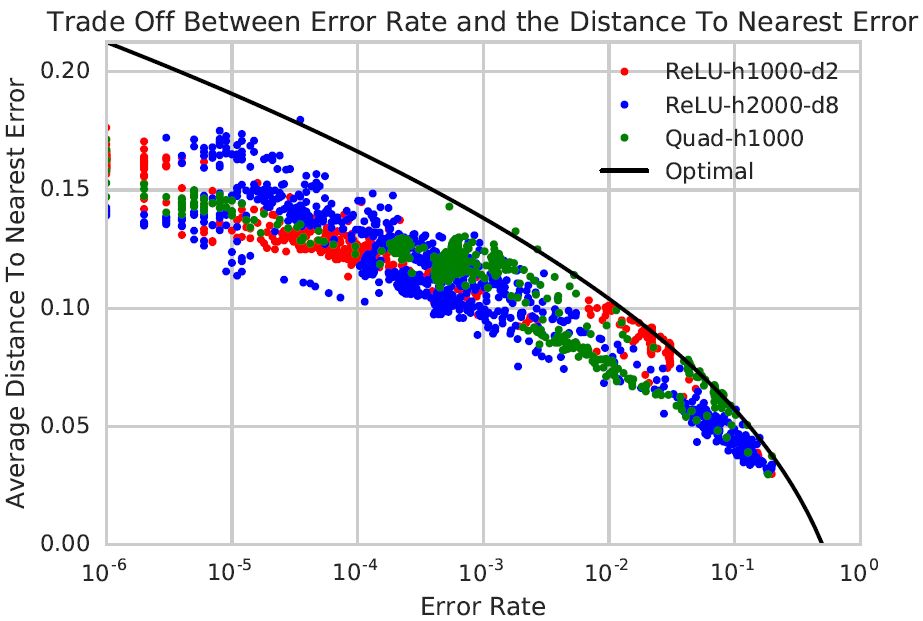
图 5:我们比较了在高维球数据集上训练出的三个网络的最近误差平均距离和错误率。结果显示所有的错误都在球内。三个网络是使用 5 个不同大小的训练集训练的,它们的性能通过训练过程中的不同点来衡量(网络最终变得特别准确,以至这幅图中无法显示出来,因为错误率太小,无法进行统计估计)。意外的是,我们观察到误差量和到最近误差的平均距离之间的衡量追踪了优化过程。需要注意的是:由于估计错误率和平均距离的时候存在一些噪声,一些网络可能表现出比优化之后更好的性能。
论文:Adversarial Spheres

论文链接:https://arxiv.org/abs/1801.02774
摘要:目前最先进的计算机视觉模型表现出了对微弱对抗性扰动的脆弱性。换句话说,数据分布中的绝大多数图像能够被模型正确分类,而且这些被正确分类的图像与被误分类的图像在视觉上特别相似(人眼无法察觉)。尽管这个现象目前已经存在大量的研究,但是这个现象的成因仍然是很难被理解的。我们假设这个反直觉的现象本身是由于输入数据流形的高维几何特征造成的。作为探索这个假设的第一步,我们研究了在一个简单的合成数据集上对两个高维同心球的分类。我们对这个数据集展示了测试误差和最近误差的平均距离之间的权衡。尤其是,我们证明,任何一个能够将球体的少量点误分类的模型都会在面临 O(1 square root d) 大小的对抗扰动时表现得很脆弱。意外地,当我们在这个数据集上训练几个不同结构的网络时,它们的所有误差都达到了这个理论边界。理论结论是,神经网络对小量对抗扰动的脆弱性是观察到测试误差数量的必然结果。希望我们对这个简单例子的理论分析能够推动这种探索:现实世界中复杂数据集的复杂几何结构是如何导致对抗样本的。

☞ 【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞ 【CFP】Virtual Images for Visual Artificial Intelligence
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【解析】当这位70岁的Hinton老人还在努力推翻自己积累了30年的学术成果时,我才知道什么叫做生命力(附Capsule)
☞ 【资源】Style2paints:专业的AI漫画线稿自动上色工具
☞ 【教程】用生成对抗网络给雪人上色,探索人工智能时代的美学
☞ 【技术】“微信身份证”AI显神威,人脸识别误判率百万分之一



