谷歌开源NLP模型可视化工具LIT,模型训练不再「黑箱」
机器之心报道
深度学习模型的训练就像是「黑箱操作」,知道输入是什么、输出是什么,但中间过程就像个黑匣子,这使得研究人员可能花费大量时间找出模型运行不正常的原因。假如有一款可视化的工具,能够帮助研究人员更好地理解模型行为,这应该是件非常棒的事。
论文地址:https://arxiv.org/pdf/2008.05122.pdf
项目地址:https://github.com/PAIR-code/lit
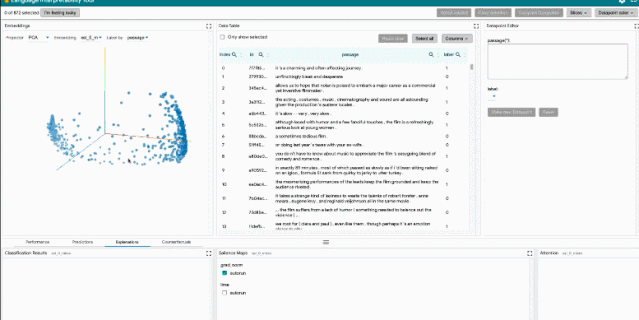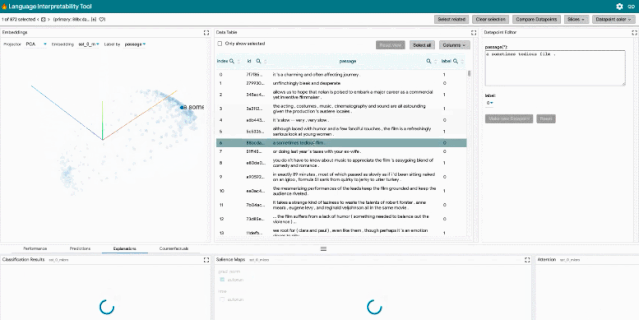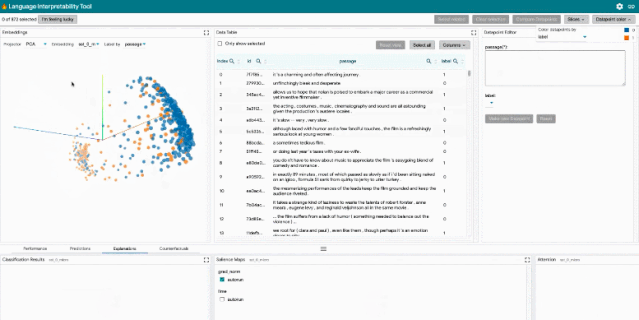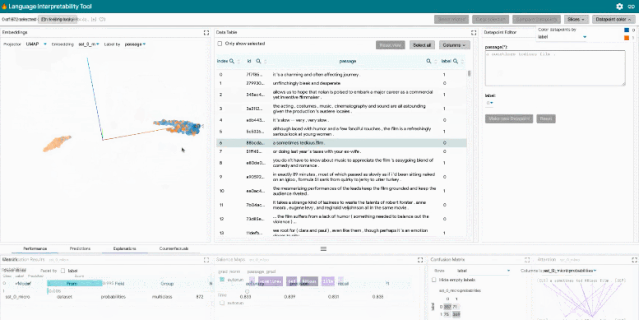
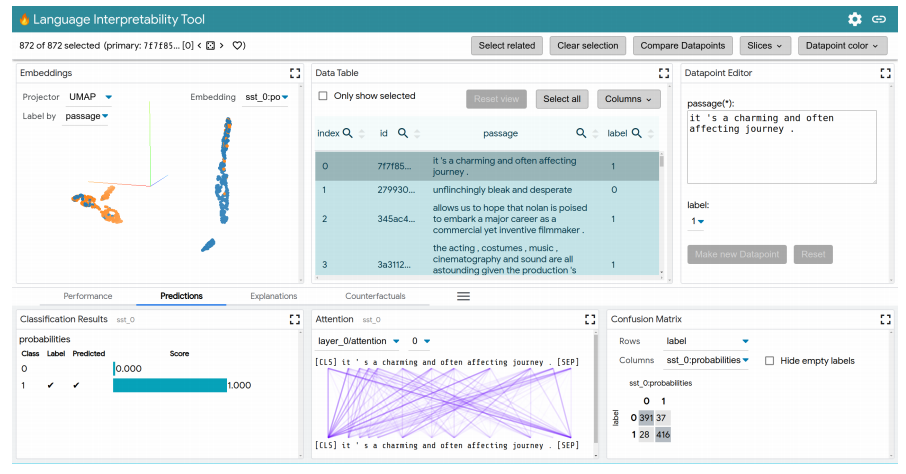
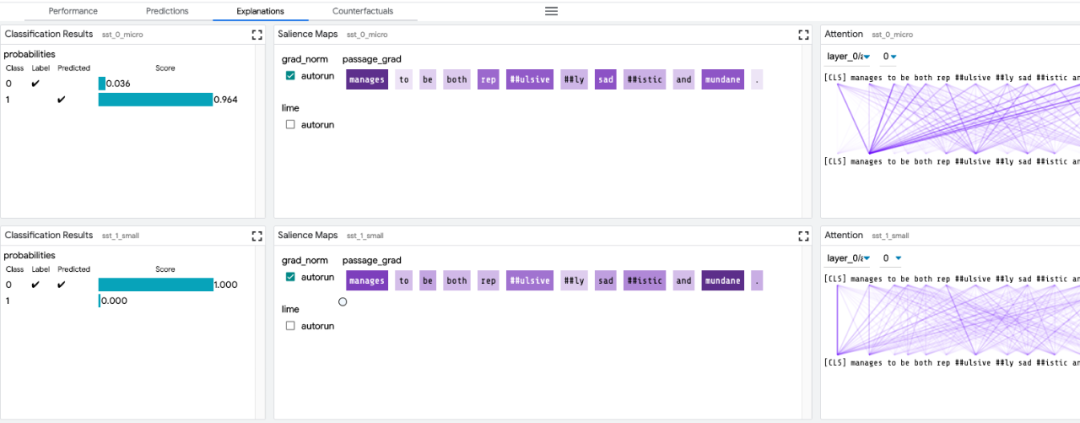
局部解释:通过模型预测的显著图、注意力和丰富可视化图来执行。
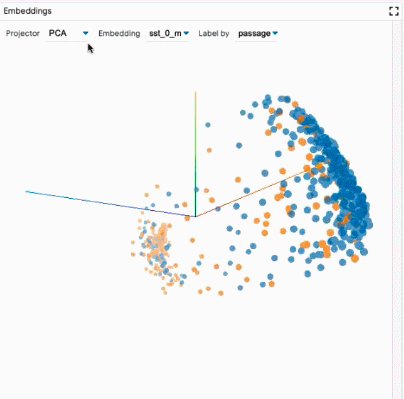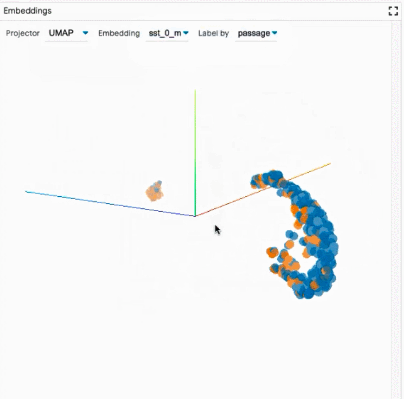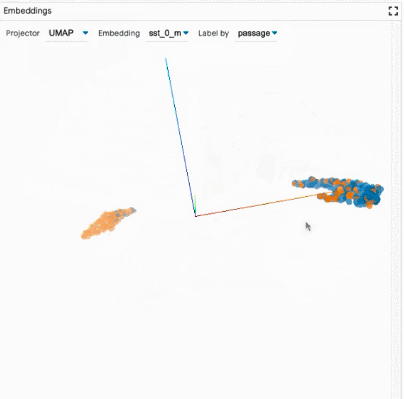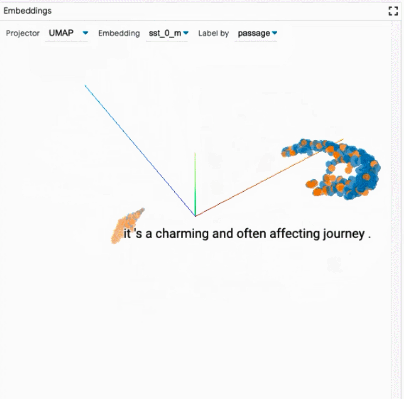
聚合分析:包括自定义度量指标、切片和装箱(slicing and binning),以及嵌入空间的可视化。
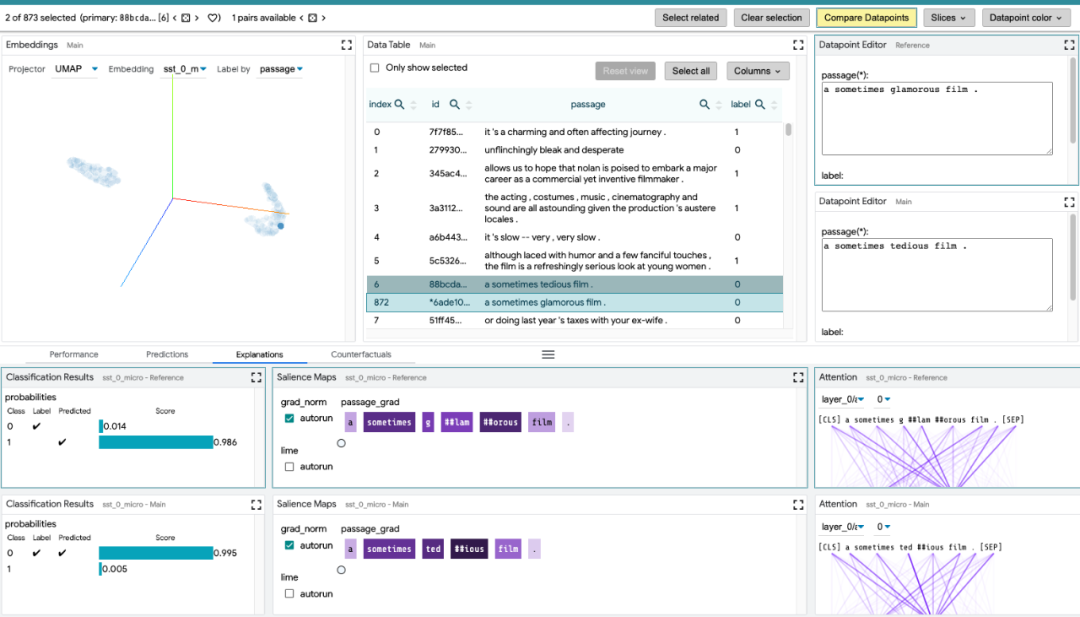
反事实生成:通过手动编辑或生成插件进行反事实推理,动态地创建和评估新示例。
并排模式:比较两个或多个模型,或基于一对示例的一个模型。
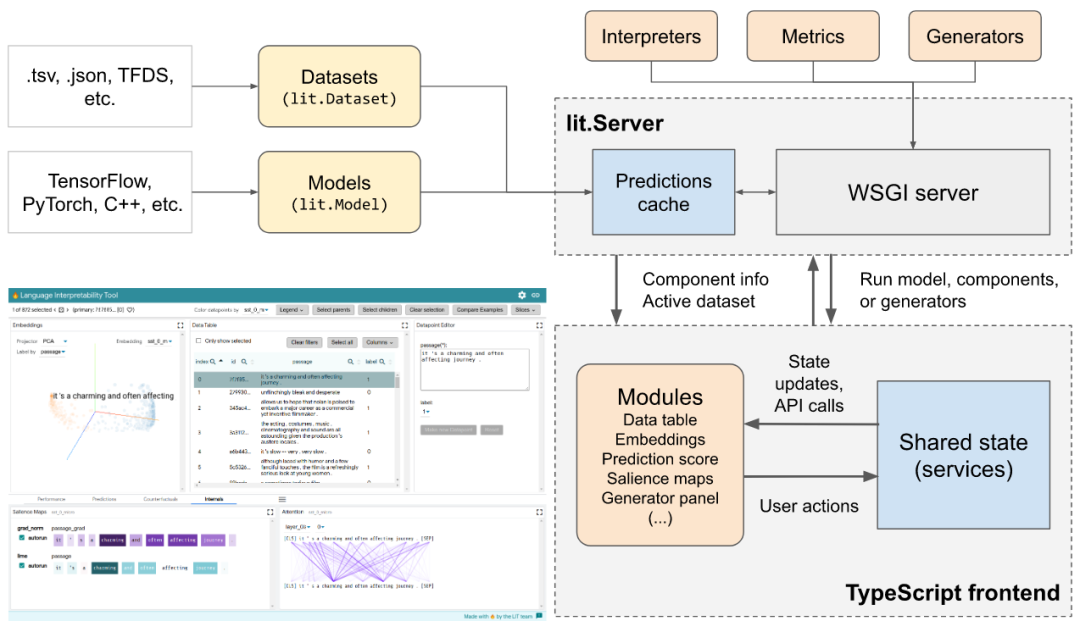
高度可扩展性:可扩展到新的模型类型,包括分类、回归、span 标注,seq2seq 和语言建模。
框架无关:与 TensorFlow、PyTorch 等兼容。
git clone https://github.com/PAIR-code/lit.git ~/lit# Set up Python environmentcd ~/litconda env create -f environment.ymlconda activate lit-nlpconda install cudnn cupti # optional, for GPU supportconda install -c pytorch pytorch # optional, for PyTorch# Build the frontendcd ~/lit/lit_nlp/clientyarn && yarn build
cd ~/litpython -m lit_nlp.examples.quickstart_sst_demo --port=5432
cd ~/litpython -m lit_nlp.examples.pretrained_lm_demo --models=bert-base-uncased \--port=5432
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年6月11日


相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年6月11日