MIT切割大量文本黑科技!数十亿选择中“海底捞”出一本好书
新智元报道
新智元报道
来源:MIT
编辑:向学
【新智元导读】MIT和IBM的研究人员结合了三种流行的文本分析工具——主题建模、词嵌入和最优传输——来每秒比较数千个文档。而且可以更快、更准确对文档分类,轻轻松松从数十亿选择中更快找到更相关的读物。戳右边链接上 新智元小程序 了解更多!

在MIT-IBM沃森人工智能实验室和MIT几何数据处理小组的帮助下,Solomon最近在NeurIPS会议上提出了一种切割大量文本的新技术。该技术结合了三种流行的文本分析工具——主题建模(Topic Modeling)、词嵌入(Word Embeddings)和最优传输(Optimal Transport),这比流行的文档分类基准的竞争方法提供更好、更快的结果。
如果一个算法知道你过去喜欢什么,它可以扫描出数百万个类似的可能性。随着自然语言处理技术的改进,那些“你可能也喜欢”的建议正变得越来越快,也越来越相关。
在NeurIPS提出的这种方法,是一种算法根据集合中的常用词将一种集合(比如说书)归纳成主题。然后将每本书分成5-15个最重要的主题,并估算每个主题对整本书的贡献。

NeurIPS 现场,热闹非凡,人潮涌动
为了比较书籍,研究人员使用了另外两种工具:词嵌入(一种将词转换成数字列表的技术,以反映词在流行用法中的相似性)与最优传输(一种计算在多个目的地之间的移动对象或数据点的最有效方式的框架)。
词嵌入使得两次利用最优传输成为可能:首先将集合中的主题作为一个整体进行比较,然后在任意两本书中比较常见主题的重叠程度。
该技术在扫描大量书籍和冗长的文档时特别有效。在这项研究中,研究人员提供了Frank Stockton的《战争辛迪加》(The Great War Syndicate)的例子,这本19世纪的美国小说,预言了核武器的兴起。如果你正在寻找一本类似的书,那么主题模型将有助于识别与其他书共享的主要主题——在这种情况下,是航海、元素和军事。

战争辛迪加
但是仅仅是一个主题模型并不能将Thomas Huxley在1863年的演讲《有机自然过去的环境》(The Past Condition of Organic Nature)确定为一个很好的匹配。这位作家是Charles Darwin进化论的拥护者,他的演讲中充斥着化石和沉积作用,反映了关于地质学的新观点。当Huxley演讲中的主题与Stockton的小说通过最优传输相匹配时,出现了一些交叉主题:Huxley的地理、动植物、知识主题 ,分别与Stockton的航海、元素和军事主题紧密相关。

有机自然过去的环境
根据书籍的代表性主题(而不是单个词)对书籍进行建模,使高层次比较成为可能。该研究的主要作者、IBM研究员Mikhail Yurochkin说:“如果你让某人比较两本书,他们会把每本书分解成易于理解的概念,然后比较这些概念。”
研究表明,结果是更快、更准确。研究人员在一秒钟内对比了Gutenberg Project数据集的1720对书籍,比次佳方法快800多倍。

Gutenberg Project数据集
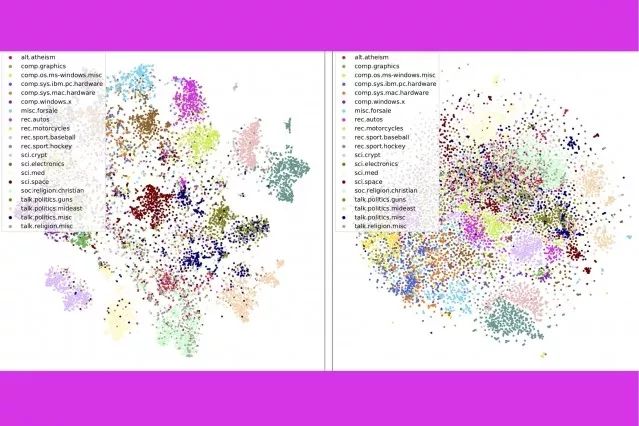
与其它方法相比,该技术还可以更准确地对文档进行分类:例如,按作者对Gutenberg Project数据集中的书籍进行分组,按部门对亚马逊的产品评论分类,以及按体育项目对BBC体育报道分类。在一系列的可视化中,作者展示了他们的方法可以很好地按类型对文档进行聚类。
除了快速和更准确地对文档进行分类之外,该方法还提供了一个窗口来了解模型的决策过程(想想就很厉害~~)。通过出现的主题列表,用户可以看到模型推荐文档的原因。
参考资料:
http://news.mit.edu/2019/finding-good-read-among-billions-of-choices-1220


