综述:在RGB-D图像上进行目标检测(Object detection in RGB-D images)

极市导读
融合显著深度特征的RGB-D图像显著目标检测方法是提取基于颜色和深度显著图的综合特征,根据构图先验和背景先验的方法进行显著目标检测。本文根据论文先后发表的时间顺序,带大家速览自2014年以来的,在RGB-D图像上进行目标检测的典型论文。>>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
CNN(convolutional neural network)在目标检测中大放异彩,R-CNN系列,YOLO,SSD各类优秀的方法层出不穷。在2D图像的目标检测上,不少学术界提出的框架已经投入商用。但是,具体落实到自动驾驶、机器人这类应用场景上时,2D场景下的目标检测对于3D真实世界的场景描述依然不够。
目标检测问题实际上包含了两个任务:定位和分类。3D目标检测在定位这一任务上的目标是返回3D bounding boxes,而其需要的信息除了2D的RGB图像以外,还包含了与之对应的深度信息Depth Map:
RGB-D = 普通的RGB三通道彩色图像 + Depth Map
在3D计算机图形中,Depth Map(深度图)是包含与视点的场景对象的表面的距离有关的信息的图像或图像通道。其中,Depth Map 类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系。
本文以时间为主轴,带你速览自2014年以来的,在RGB-D图像上进行目标检测的典型论文。
论文
2014年:Learning Rich Features from RGB-D Images for Object Detection and Segmentation(ECCV'14)
本文是rbg大神在berkeley时的作品。”基于CNN已经在图像分类、对象检测、语义分割、细粒度分类上表现出了相当的优势,不少工作已经将CNN引入在RGB-D图像上的视觉任务上。这些工作中一部分直接采用4-channel的图像来进行语义分割任务(not object detetction),一部分只是在非常理想的环境下对小物体进行目标检测。“
作者的方法是在2D目标检测框架R-CNN的基础上,增加对Depth Map进行利用的module,总体结构如下:
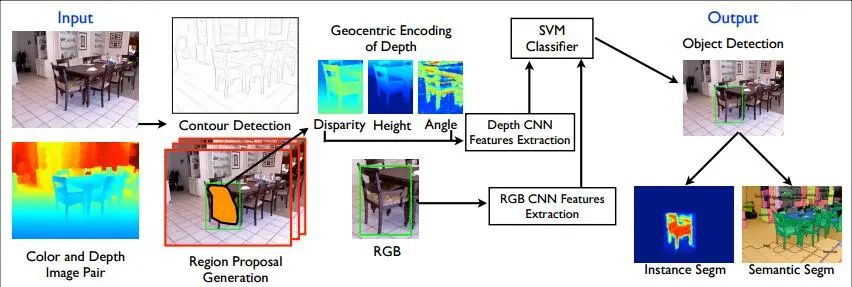
(1)基于RGB图像和Depth Map,检测图像中的轮廓,并生成2.5D的proposals(从overview上可以看到,所谓的2.5D实则包括目标每个像素的视差、高度、倾斜角)
(2)利用CNN进行特征提取,这里的网络包括两个:Depth CNN学习深度图上的特征,RGB CNN学习2D图像上的特征,最后利用SVM进行分类。
在对Depth Map的利用上,论文所述方法并没有直接利用CNN对其进行学习,而是encode the depth image with three channels at each pixel: horizontal disparity(水平视差), height above ground(高度), and the angle the pixel’s local surface normal makes with the inferred gravity direction(相对于重力的倾斜角).
2015年:3D Object Proposals for Accurate Object Class Detection(NIPS'15)
来自Tsing Hua陈晓智大神的作品(大神在同时也是CVPR17: Multi-View 3D Object Detection Network for Autonomous Driving的一作,给跪了)。
作者首先指出,目前最先进的RCNN方法在自动驾驶数据集KITTI上表现不好,原因之一在于KITTI上的测试图像中,包含许多小型物体、遮挡、阴影,使得实际包含了object的proposals被认为是不包含的。此外,KITTI对区域的精细程度要求很高(overlap),而目前的大多数区域推荐都基于强度和纹理的grouping super pixels,它们无法获得高质量的proposals。
文章面向自动驾驶场景,提出了一种新的object proposal方法。对于每一个3D bounding box(记为y),将其用一个元组来表示(x, y, z, θ, c, t),(x, y, z) 表示 3D box的中心,θ 表示其方位角,c代表object是哪一类,t代表相应的3d box模板集合。
以x代表点云,y代表proposal,作者认为y应该有以下特性:
包含点云的高密度区域
不能与free space重叠
点云不应该垂直延伸在3d box之外
box附近的点云高度应该比之低
基于这些特性,作者列出了能量方程,目标为最小化E(x,y),采用ICML2004上一篇文章中所述的structured SVM进行训练。
文章中所述方法的效果、代码、数据:3D Object Proposals for Accurate Object Class Detection

2016年:Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images(CVPR'16)
文章来自普林斯顿大学,提出的方法为Faster R-CNN的3D版本,侧重于indoor scene下的object detection。
目前关于3D目标检测任务的方法,有采用2D方法来结合深度图的,也有在3D空间内进行检测的。这不禁让作者发问:which representation is better for 3D amodal object detection, 2D or 3D?接着他指出,目前2D方法表现更优异的原因,可能是因为其CNN模型更为powerful(well-designed&pre-trained with ImageNet),而不是由于其2D表达。
作者的方法是设计名为Deep Sliding Shapes的3D CNN,输入3D的立体场景,输出3D bounding boxes,由此提出了Multi-scale 3D RPN(Region Proposal Network):
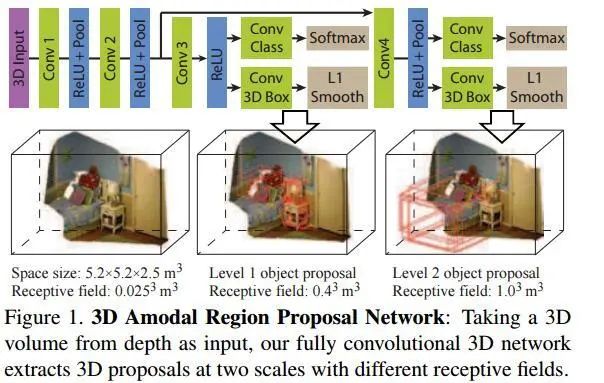
类似于Faster R-CNN中的RPN网络,对于每一个滑动窗口,作者定义N=19种anchor boxes:
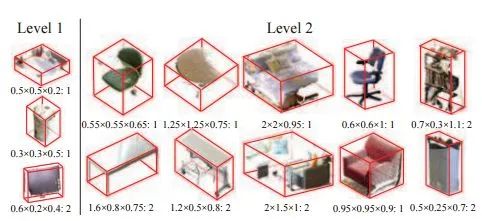
而后,为了检测大小不一的目标,作者增加了多尺度的检测手段。具体来说,在不同的卷积层上进行滑窗。这里的滑窗是3D sliding window,因为整个网络结构就是接收3Dinput的。为了精修区域,作者改进了bbox regression,提出3D box regression:一个3D box可以由中心坐标[cx, cy, cz],长宽高[s1, s2, s3]来表示,最后要得到的是6个偏移量:
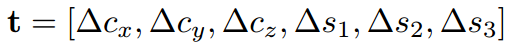
而后采用与2D box regression同样的smooth L1 loss即可。
补充:如何从Depth Map得到3D Input?
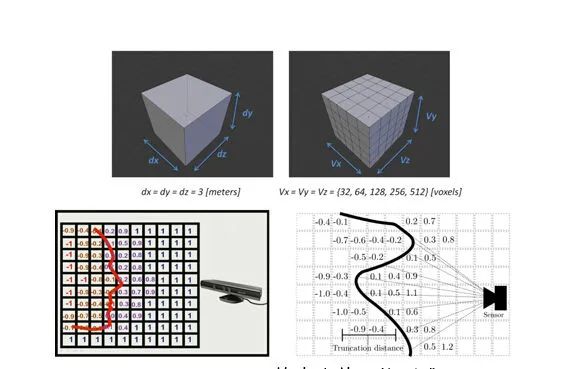
Encoding 3D Representation:不同于Depth RCNN的disparity+height+angle 表达,作者在这里采用了TSDF方法,可以看如下的引用:
KinectFusion在世界坐标系中定义了一个立方体,并把该立方体按照一定的分辨率切割成小立方体(voxel)。以图8上为例所示,图中定义了一个3x3x3米的立方体,并把立方体分为不同分辨率的小立方体网格。也就是说,这个大立方体限制了经过扫描重建的模型的体积。然后,KinectFusion使用了一种称为“截断有符号距离函数”(truncated signed distance function,简称TSDF)的方法来更新每个小网格中的一个数值,该数值代表了该网格到模型表面的最近距离,也称为TSDF值(图8下)。对于每个网格,在每一帧都会更新并记录TSDF的值,然后再通过TSDF值还原出重建模型。例如,通过图8下两幅图中的网格的TSDF数值分布,我们可以很快还原出模型表面的形状和位置。这种方法通常被称为基于体数据的方法(Volumetric-based method)。该方法的核心思想是,通过不断更新并“融合”(fusion)TSDF这种类型的测量值,我们能够 越来越接近所需要的真实值。
2017:Learning Cross-Modal Deep Representations for Robust Pedestrian Detection(CVPR'17)
这篇文章虽然是针对于专门的pedestrians detection任务,但是其做法是很具有启发性的,所以也贴在这里。
作者指出,“行人检测任务在深度学习的帮助下已经取得重大突破,同时新型传感器(如thermal and depth cameras)也为解决不利照明和遮挡提供了新的机会。但是,现有监控系统绝大多数仍然采用传统的RGB传感器,因此在illumination variation, shadows, and low external light仍然十分具有挑战。”
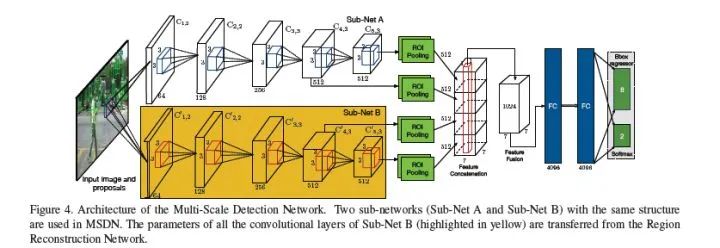
在针对于照明条件不利环境下的行人检测任务,文章描述了一种依赖于cross-modality learning framework的学习框架,由两个网络组成:
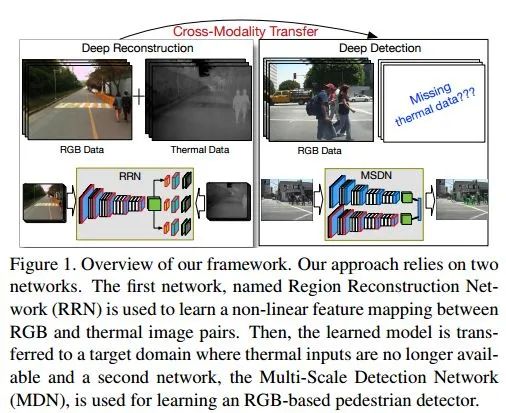
(1)Region Reconstruction Network (RRN)
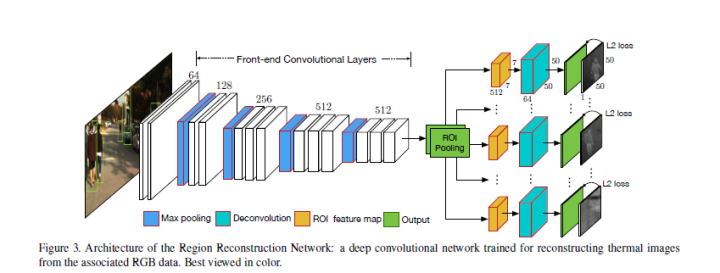
RRN用于学习在RGB图像和thermal image间的映射,而后学习得到的模型就可以用于依据RGB生成thermal image。RRN接收RGB+行人proposals,在ROI Pooling后加了重建网络(全卷积)。这里的重建网络不重建整幅图像的thermal image,而是只对行人区域进行重建。
(2)Multi-Scale Detection Network (MSDN)
MSDN利用RRN学习的cross-modal representations来进行检测。其包含两个子网(Sub-Net A和Sub-Net B),其中Sub-Net B中的参数从RRN中迁移而来,最后的fc分别做multi-task:bbox regression和softmax。
2017:Amodal Detection of 3D Objects: Inferring 3D Bounding Boxes from 2D Ones in RGB-Depth Images(CVPR'17)
来自坦普尔大学的文章。作者在这里与2016的Deep Sliding Shapes思路不同,重新回到2.5D方法来进行3D目标检测。所谓2.5D方法,实则就是从RGB-D上提取出合适的表达,而后building models to convert 2D results to 3D space。“虽然利用三维几何特征检测前景光明,但在实践中,重建的三维形状往往不完整,由于遮挡、反射等原因而含有各种噪声。”
整个系统的overview如下,其基于Fast R-CNN实现:
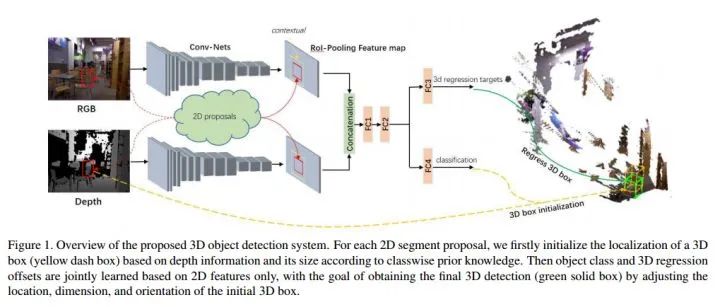
对于每一个2D的proposal(这里关于2D proposals的方法就是用的Depth R-CNN中的方法),由分类结果和depth information来初始化一个3D bounding box(图中黄色的虚线框),而后也是用一个3d box regression来进行区域精修。重点关注3D box proposal and regression:
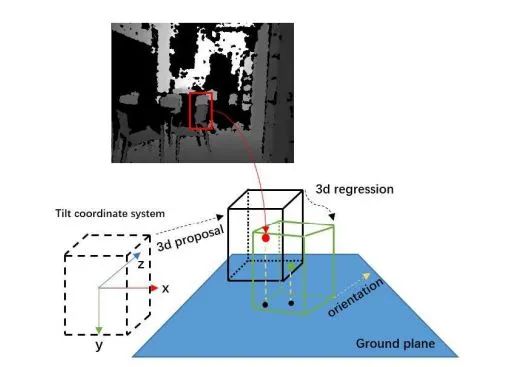
图中是3D box proposal的一个实例。每一个3d box由向量[xcam, ycam, zcam, l, w, h, θ].来表达,[xcam, ycam, zcam]表中心位置,[l, w, h]表尺寸,θ∈ [−π/2, π/2]表示方位角,即图中黄色的箭头与z轴形成的夹角。在初始化的时候,关于尺寸是由某一类物体的类别来进行确定的。最后输出7个调整量[δx, δy, δz, δl, δw, δh, δθ],利用Smooth L1 Loss作为损失函数。
结语
3D目标检测对于自动驾驶与机器人等领域意义重大。本文以时间为序,重点关注和分析了基于RGB-D上的3D Object Detection方法。从Depth R-CNN到3D Faster-RCNN,似乎始终基于2D的目标检测框架在跟循改进。期待在未来,将会有更为优美的方法出现。
感谢您的阅读,文中的遗漏与错误,恳请批评指正。
参考文献
推荐阅读







