赛尔原创 | 反讽识别综述
作者:哈工大SCIR硕士生罗观柱
摘要:本文对反讽识别任务的研究现状与进展进行了总结。首先介绍了反讽的概念及反讽识别的意义,然后总结了常用的反讽识别数据集,最后概括了当前的研究现状,主要从上下文有关和上下文无关两大方面来介绍反讽识别模型。
关键词:反语; 讽刺; 反讽; 情感分析; 综述
随着社交媒体(Social Media)的蓬勃发展,网络用户大量运用修辞方法在网络上发表观点或表达情感,网络文本越来越多的包含反语、讽刺或幽默等表达方式。修辞方法的运用给自然语言处理带来了极大困难,在情感分析任务中传统的情感分析难以正确识别含反语文本的实际情感,反语等这种修辞方式严重影响了社交媒体情感分析的识别精度,因此针对反语和讽刺的研究,在情感分析等问题中具有重要意义[12]。
反语(Irony)和讽刺(Sarcasm)是社会媒体中常用的修辞方法。反语是指运用跟本意相反的词语来表达此意,却含有否定、讽刺以及嘲弄的意思,是一种带有强烈感情色彩的修辞格,比如“I absolutely love to be ignored !”。讽刺则是用比喻、夸张等手法对人或事进行揭露、批评或嘲笑,比如“Good thing Trumpis going to bring back all those low education highpaying jobs.”。关于反语和讽刺的关系,可以认为讽刺是包含情绪(比如攻击性情绪)的一种反语[9]。为方便起见,后文统一称之为“反讽”,不再对反语和讽刺进行区分。
反讽识别的研究目前主要存在以下难点:(1)权威的反讽数据集较少且规模不大,中文语料更是少之又少;(2)单纯的文本信息,缺乏说话人的语音、语调以及说话人的状态信息,难以判断是否是反讽;(3)由于社交媒体或者会话中,以短文本多见,文本长度制约了对上下文信息的获取;(4)反讽的表达方式与字面意思无关,需要获取深层的语义信息,才能准确的识别反讽;(5)由于反讽与语言习惯有关,不同语言的语言结构对其有着重大影响[12]。
1. 数据集
目前可以公开获取的反讽识别任务数据集多数为英文语料,中文的公开语料较少,目前只有Tang[10]等人针对繁体字构建了一个反语语料库并分析了反语常见的句式结构。下面将介绍已公开的中英文反讽数据集。
1.1 繁体中文语料
国立台湾大学的Yi-jie Tang在Chinese Irony Corpus Construction and Ironic Structure Analysis(COLING 2014)用基于表情符的规则从噗浪网(Plurk,台湾地区的微博平台)挖掘繁体中文反讽语料1005条,并总结了五种反讽语言模式,这是国内第一份中文(繁体)反讽语料。
1. 语料库样例
“很好,又失眠了!! :-(”2. 对应的XML格式
<message><rhetoric>很</rhetoric><ironic sentiment="pos">好</ironic><context sentiment="neg">又失眠了</context><rhetoric>!!</rhetoric>:-(</message>3. XML标签解释
<message>:表示来自噗浪网的一条微博。
<ironic>:表示每个反讽微博中的反讽词或短语,附带的情感属性代表该反讽词或短语的情感极性(褒贬二元极性),每条可以有多个<ironic>标签。
<context>:表示上下文信息,附带的情感属性代表该反讽词或短语的情感极性(褒贬二元极性),该标签并非每条反讽微博都有。
<rhetoric>:表示修辞元素。
语料下载地址:http://nlg.csie.ntu.edu.tw/nlpresource/irony_corpus
1.2 英文语料
英文的反讽语料多而杂,多数为英文tweets(Twitter上的微博)、Reddit(社交新闻)、4Forums(政治辩论投票论坛)等。下面介绍几个论文中常用的英文反讽语料。
1.2.1 Tweets
(1) Riloff et al. 2013 Tweets数据集
这是较早的一份英文Tweets语料,共计3000条,标签为二元类别,即“反讽”与“非反讽”,是根据tweets的Hashtag(#irony, #sarcasm等)自动标注,并加入了人工整理获得。其中反讽为693条,非反讽为2307条。
语料下载地址:http://www.cs.utah.edu/~riloff/publications_chron.html
(2) Ptacek et al. 2014 Tweets数据集
该语料同样来自Twitter(包含了英语和捷克语),标注方法为根据Hashtag(#not, #sarcasm, #irony)自动标注,二元标签。其中平衡数据集反讽50000条,非反讽50000条;非平衡数据集反讽25000条,非反讽50000条(这里只统计了英文语料)。
语料下载地址:http://liks.fav.zcu.cz/sarcasm
说明:
限于Twitter隐私政策,上述tweets数据集只能公开tweets ID列表,原tweets内容需要利用Twitter API自己爬取。
由于数据集中tweets年代久远(tweets大约发表于2013、2014年),大量tweets都已失效,所以现在能爬取到的只能是原数据集的子集。
(3) SemEval-2018任务3的评测数据集
该数据来自2014年1月12日至2015年4月1日的tweets,覆盖2676位不同用户,借助tweets自带的反讽hashtags(#irony, #sarcasm 与 #not)自动构建了2222条反讽tweets,为保证与非反讽语料的平衡性,该数据集又加入2396条非反讽tweets,共计4618条。该评测任务分为两个子任务,任务A为反讽、非反讽二元分类,任务B为四分类问题,即细粒度反讽识别,具体的是在任务A基础上将反讽类Tweets进一步划分为三种:ironic by clash、situation irony和other irony。经统计,ironic by clash约占69.9%,该数据集可能是目前唯一个包含“细粒度”反讽类别的数据集。
语料下载地址:https://github.com/Cyvhee/SemEval2018-Task3
1.2.2 SARC(Reddit数据集)
这是Mikhail Khodak等人在LREC2018论文A Large Self-Annotated Corpus for Sarcasm新构建的语料库,该数据为百万规模,解决了的以前反讽语料库规模小、领域狭隘或者未区分领域的问题。此外,该数据集包含了上下文信息,如发帖的用户名、该句所属的论坛主题、该句的回复等。标注方法为自动标注,依据是Reddit特有的“/s”符号。论文中常用的是该数据集的movies与technology两个子类别。其中movies数据共计8188条,反讽为3450条,非反讽为4738条;technology数据共计22510条,反讽为9858条,非反讽为12652条。
语料下载地址:http://nlp.cs.princeton.edu/SARC
1.2.3 Internet Argument Corpus(IAC)
数据集来自4Forums.com论坛,该论坛用作政治辩论与投票。该数据集的特点为每条长度较长(tweets数据集、Reddit数据集长度为11~18词,IAC长度为54~64词),多为隐晦的政治讽刺风格的长句。论文中常用的是Debates V1和V2两个版本。V1总计4646条,反讽为1232条,非反讽为3414条;V2总计1935条,反讽为703条,非反讽为1232条。
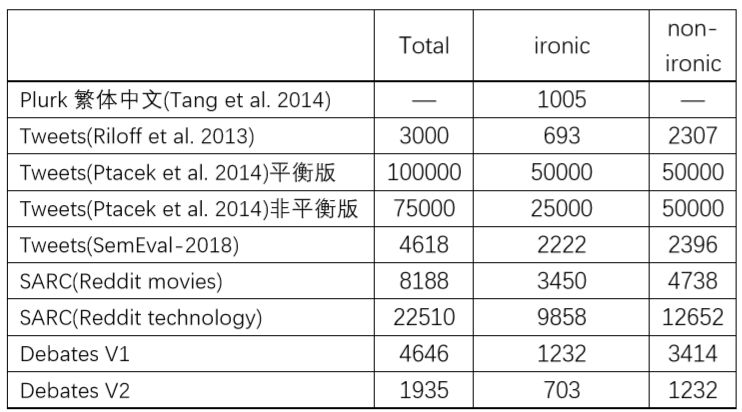
表1 常用反讽数据集统计(部分数据来自Yi Tay et al. EMNLP 2018)
2. 反讽识别现状研究
反讽识别从是否结合上下文来说可分为两大类,即上下文无关的反讽识别和上下文有关的反讽识别。上下文无关的反讽识别仅通过分析目标句判断是否为反讽,不需要结合上下文信息;而上下文有关的反讽识别则通过分析目标句与其上下文来判断是否为反讽。
以下将介绍上下文无关的论文Reasoning withSarcasm by Reading In-between(Yi Tay et al. ACL 2018)和上下文有关的论文CASCADE: Contextual Sarcasm Detection in Online Discussion Forums(Devamanyu Hazarika et al. COLING 2018)和RepresentingSocial Media Users for Sarcasm Detection(Y. AlexKolchinski, EMNLP 2018)。
2.1 上下文无关的反讽识别
Reasoning with Sarcasm by Reading In-between(Yi Tay et al. ACL 2018)提出了一种上下文无关的反讽识别模型。该论文中提到了一种现象,即虽然反讽表达形式多样,但其中有很大一部分(SemEval2018数据集显示占69.9%)是“前后情感矛盾式的反讽”,比如在“I absolutely love to be ignored !”、“ Yay!!! The best thing to wake up to is my neighbor’s drilling .”、“ Perfect movie for people who can’t fall asleep.”中,词对(word pair) {love, ignored}, {best, drilling} 与 {movie, asleep}在情感、状态或行为上“相反”,作者从这一点出发构造一种模型可以“looking in-between”。通常来讲,先前的反讽识别模型模型多依赖深的序列化的神经网络来建模反讽句子,比如主要使用GRU、LSTM等序列建模方法提取特征。这种模型有两个缺点,一个是GRU、LSTM无法精确捕捉反讽句中的“词对相反”这种特点,这就相当于损失了反讽句中的很重要的一种文本特征,另一个缺点就是GRU、LSTM由于无法捕捉长期依赖,举例来讲,如果词对{love, ignored}相距较远便无法很好的检测到。一个更合理的模型应该是“intra-sentence”的,即不但要追求识别精度的提高,还要求模型具有可解释性,由此推断合理的模型应该使用注意力机制。
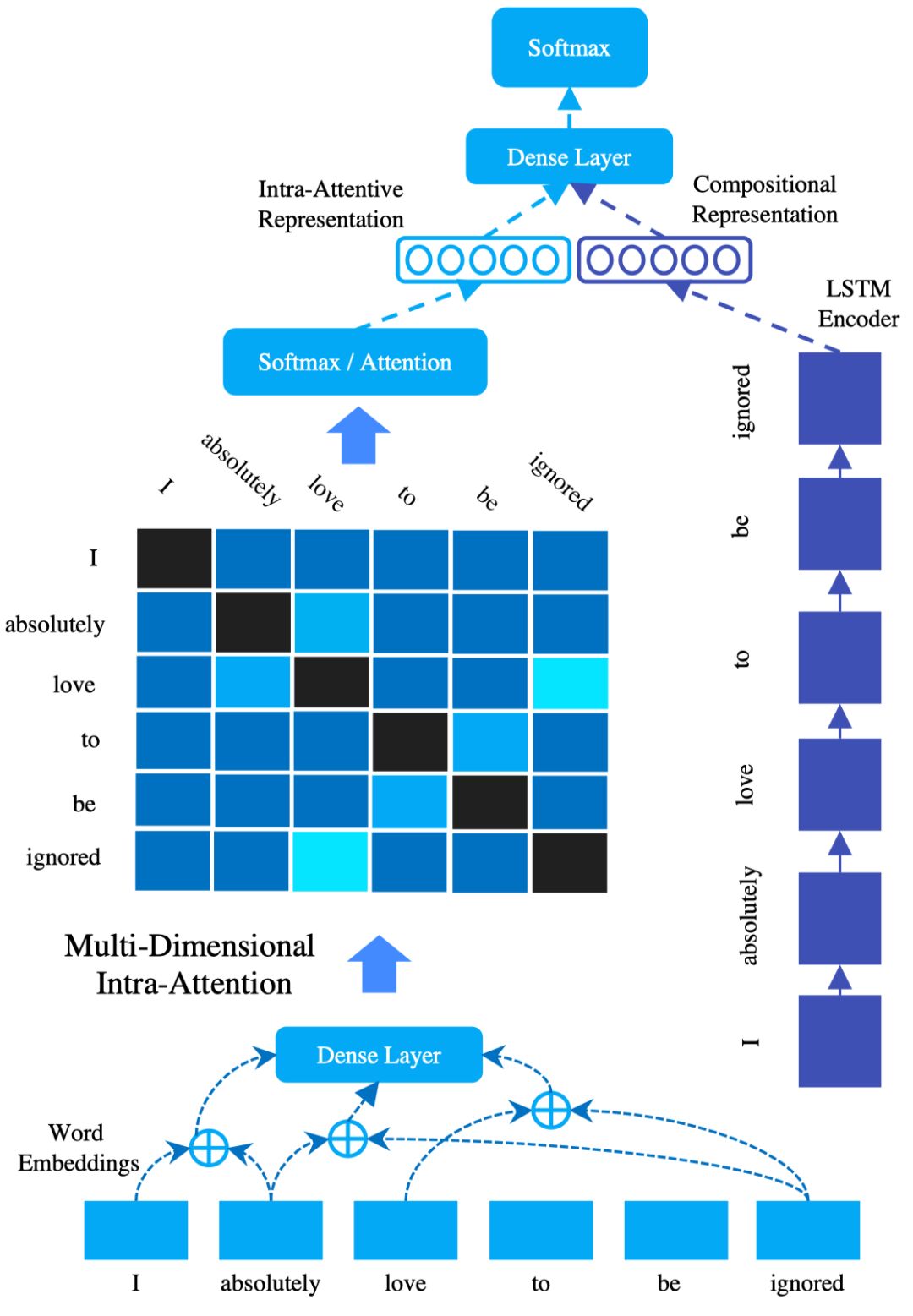
图1 论文中的MIARN模型结构
由上图可知,用作句子分类的“句子向量表示”由LSTM的“句子表示”和“句内attention表示”组成。
2.1.1 LSTM“句子表示”
LSTM“句子表示”是普通的句子序列化建模表示。
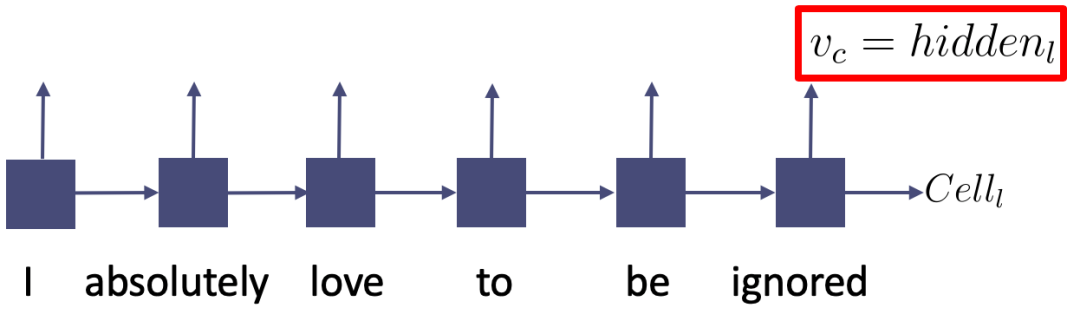
图2 LSTM“句子表示”用最后一个隐层输出表示
2.1.2 “句内attention表示”
“句内attention表示”是对于“词对关系”的表示,用来突出{love, ignored}这种词对关系,构建方法如下:
(1) 计算任意词对的注意力分数
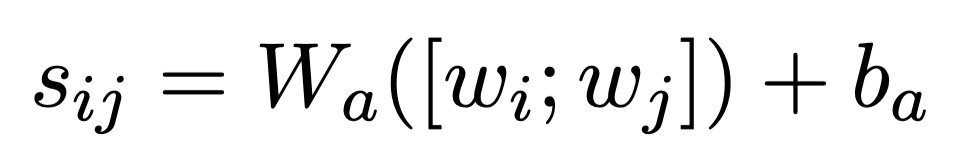
(2) 二维分数矩阵按行取max pooling并做归一化;由(1)词之间两两做attention可以得到注意力分数矩阵,在该矩阵每一行取最大可降维得到一维向量,然后再做softmax归一化。
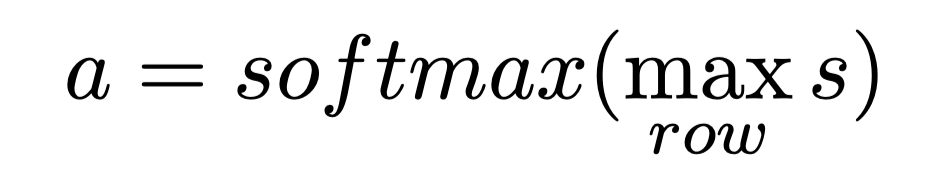
(3) 最后计算“句内attention表示”
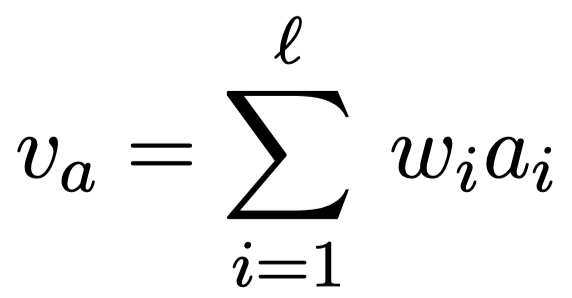
2.1.3 分类预测
由上述1和2分别得到了LSTM“句子表示”和“句内attention表示”,将二者拼接做分类预测。
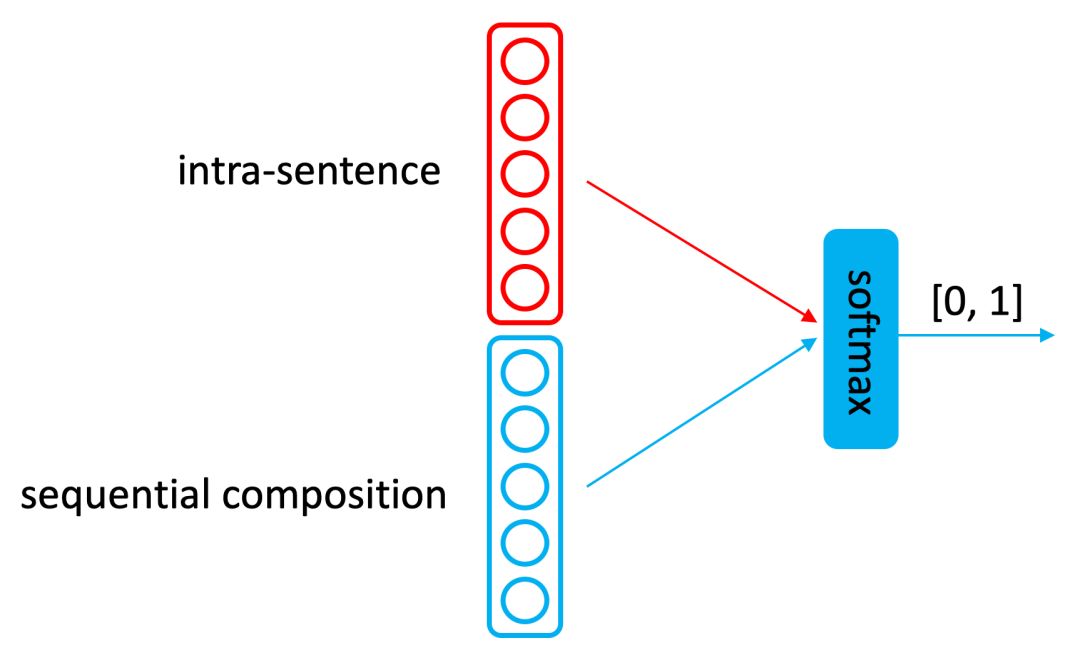
图3 模型下游的句子向量表示来做分类
2.2 上下文有关的反讽识别
事实上,反讽的判定严重依赖于上下文,这里的上下文指的是广义的上下文,比如说话人的声音、语调、表情,说话人当时的状态等,或者要识别的文本在长文中的位置、社会媒体的转发、回复、评论等等。因此,原则上反讽判定需使用上下文推定才够准确。下面将介绍两个上下文有关的建模识别反讽论文,分别是CASCADE: Contextual Sarcasm Detection in Online Discussion Forums(Devamanyu Hazarika et al. COLING 2018)和RepresentingSocial Media Users for Sarcasm Detection(Y. AlexKolchinski, EMNLP 2018),前者使用了较为复杂的上下文信息,后者则使用了简单的上下文信息。
2.2.1 COLING 2018 论文
在COLING 2018一文中,作者提出了一种结合多种上下文识别反讽的模型。该论文实验使用的是含有上下文信息的SARC(Reddit)数据集。作者认为每条post(Reddit的发帖称为post)由两部分组成,即post本身的内容和post的上下文(这里的上下文包括post的用户信息和post所属的主题信息),作者构造了一种模型将二者融合来检测反讽。
2.2.1.1 上下文信息的构建
对该论文来说,Post的上下文信息包括用户信息和主题信息,具体如下:
1. 用户信息(User Embeddings)
这里的用户(user)是指发布该post的用户,用户信息又分为用户的文体风格(编注:Stylometric,该特征常用来分析文章的作者,即Authorship Analysis,可参考[14])和用户的个性化(编注:Personality,可使用Personality分析人的行为,可参考[15])。
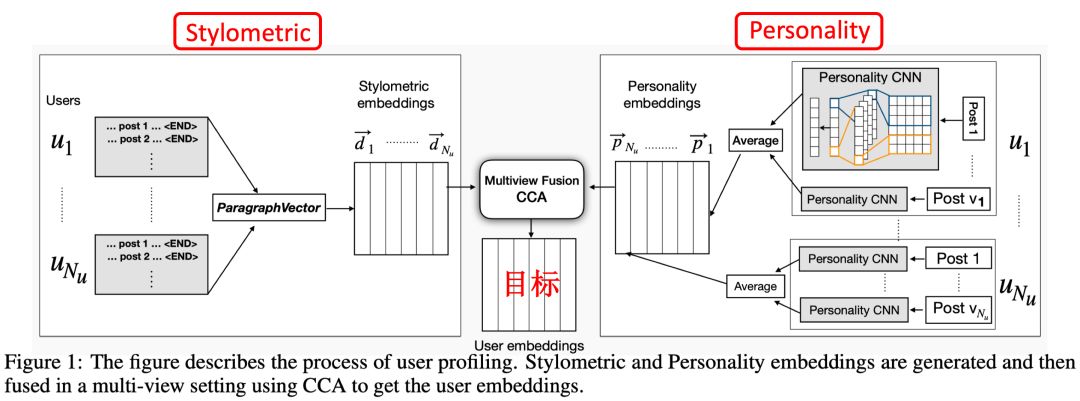
图4 用户信息建模(Stylometric + Personality)
Stylometric建模流程如下:

图5 Stylometric建模流程
Personality建模流程如下:
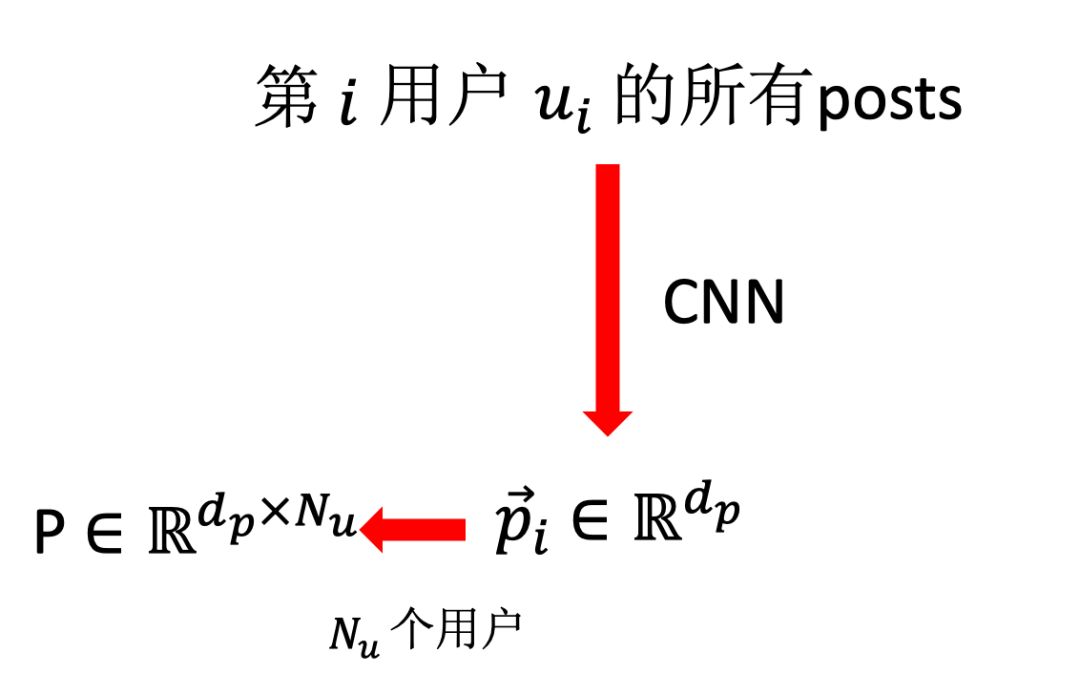
图6 Personality建模流程
由Stylometric和Personality建模分别得到和的矩阵,然后使用典型相关性分析(CCA)融合降维为User Embeddings。
2. 主题信息(Discourse Features)
在SARC数据集中,每条post有所属的forums,每个forums有自己的主题。
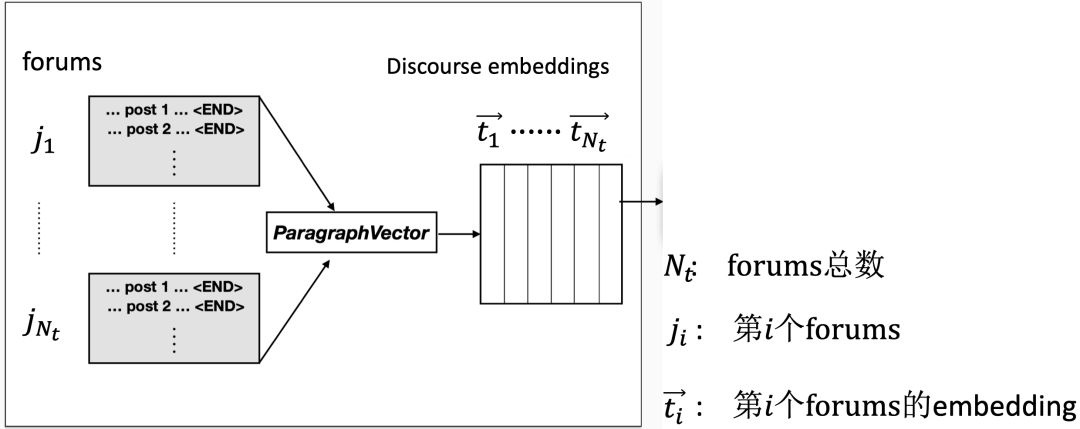
图7 forums的主题
2.2.1.2 建模post内容+融合
在该部分,post内容表示使用CNN+MaxPooling得到的向量表示该post,然后与用户信息上下文和post主题上下文拼接得到该post的上下文有关表示进行分类。
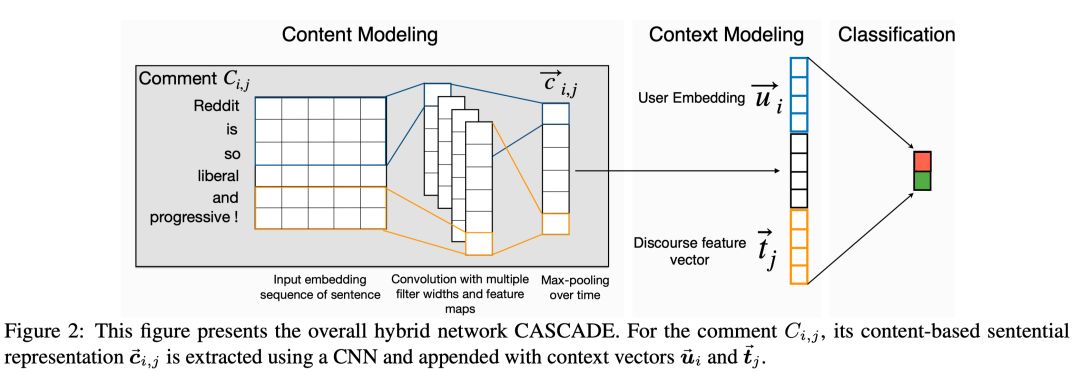
图8 COLING 2018论文模型框图
2.2.2 EMNLP 2018 论文
在EMNLP 2018一文中,作者简化了上下文信息,仅研究用户(Author)信息对反讽识别的作用,其基本假设是不用用户的表达习惯不同,可以作为反讽识别的重要特征。
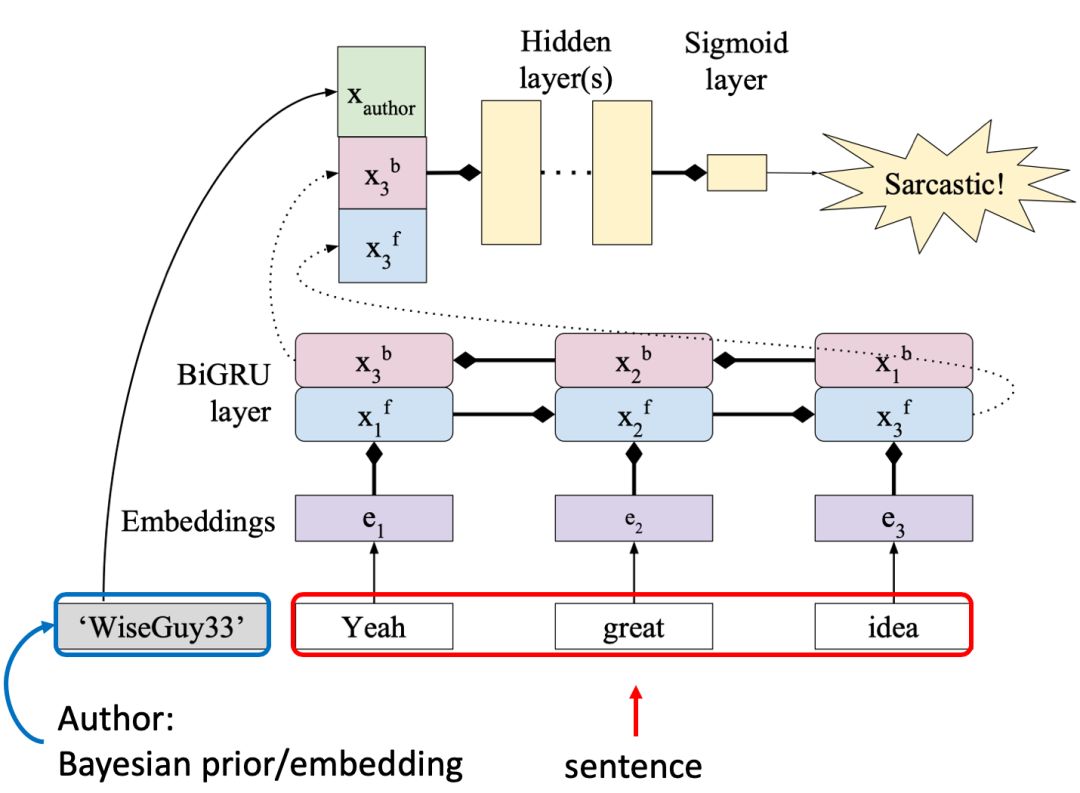
图9 EMNLP 2018 模型框图
下面考虑加入Author信息的方式,并与基准模型做对比。
1. 基准模型
朴素BiGRU二分类器,无上下文信息,只对目标句做BiGRU表示进行分类。
2. 加入Author信息:Bayesianprior + BiGRU
这种方法将Author视为贝叶斯先验知识,可通过训练语料统计得到。此时,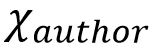
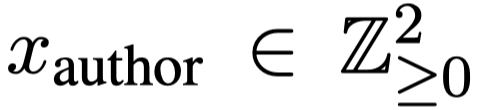
3. 加入Author信息:Author embedding + BiGRU
这种方法将Author视为可学习的向量,数值可通过训练训练模型微调。此时,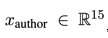

模型实验:
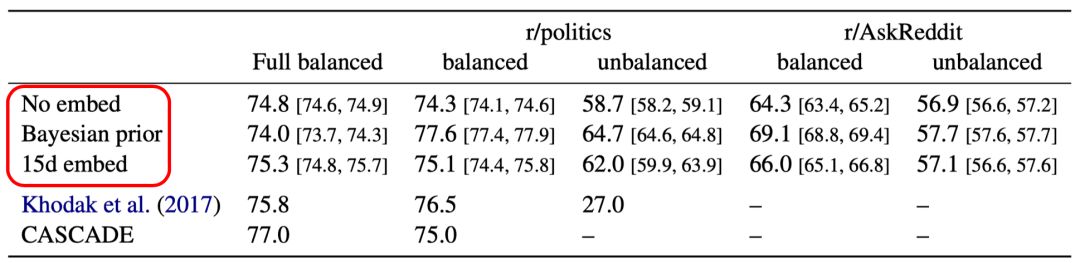
表2 测试语料为SARC的子集
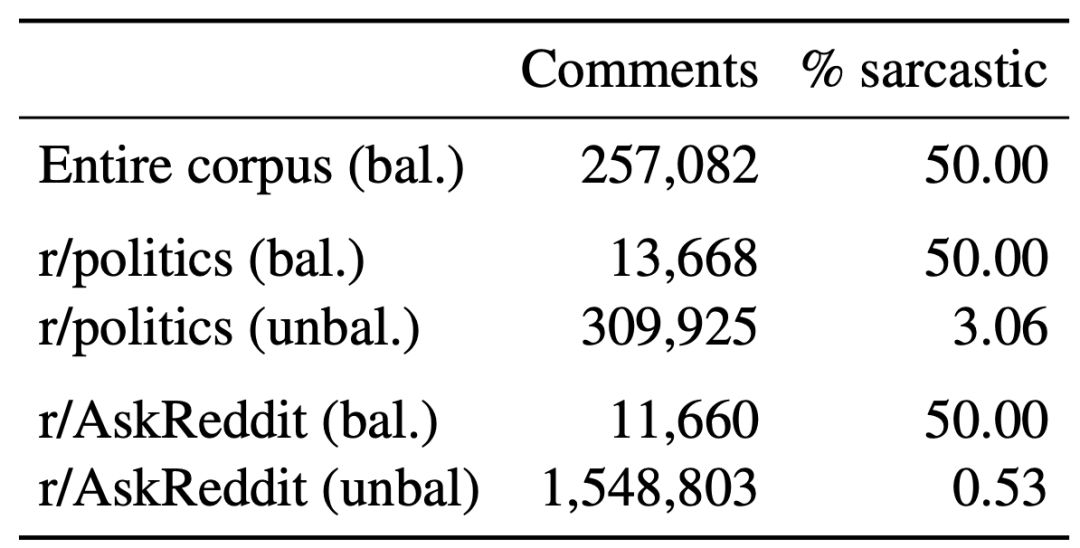
EMNLP2018模型实验结果表明,该模型与使用复杂上下文的CASCADE (COLING2018) 相比,某种程度上具有可比性。
表3 EMNLP2018模型实验
3. 结论与展望
本文主要对社会媒体中的反讽检测做了归纳总结,包括反讽检测的概念、存在的难点、常用数据集及研究现状等。反讽是社会媒体中常用的修辞手法,反讽的出现会对一些NLP任务带来挑战,因此反讽检测具有重要的研究意义。反讽数据集往往规模较小,而SARC数据集的出现带来了百万规模、多种主题且附带上下文的反讽语料库。关于反讽检测的未来工作可考虑如下几个方面[16]:
1. 数据集
我们认为多类型、多格式的数据集对反讽检测任务有积极意义。推测未来有潜力的可以构建反讽数据集的网站之一是Steam store(一个电子游戏商店平台),该网站拥有大量活跃的用户,商店评论内容更新及时,购买游戏前阅读商店评论是用户访问该网站的主要原因。很多情况下,如果游戏质量没有厂商宣传的那么好就会有用户发表反讽类的评论。我们建议未来的研究人员可以将Steam数据集作为研究主题。
2. 加入上下文信息
反讽与上下文高度相关,原则上使用上下文信息能极大提高反讽检测的准确率,我们认为未来的工作应该着眼于与上下文信息的结合。广义的上下文信息包括但不限于:
用户特性
目标文本的回复、评论等
目标文本所处的语境(这里指狭义的上下文)
参考文献:
[1] Tang YJ, Chen H. Chinese irony corpusconstruction and ironic structure analysis, COLING 2014.
[2] Yi Tay, Luu Anh Tuan et al. Reasoningwith Sarcasm by Reading In-between, ACL 2018.
[3] Y. Alex Kolchinski, Christopher Potts. RepresentingSocial Media Users for Sarcasm Detection,EMNLP 2018.
[4] Devamanyu Hazarika et al. CASCADE: ContextualSarcasm Detection in Online Discussion Forums, COLING 2018.
[5] Mikhail Khodak, Nikunj Saunshi et al. ALarge Self-Annotated Corpus for Sarcasm, LREC 2018.
[6] Hen-Hsen Huang, Chiao-Chen Chen et al.Disambiguating False-Alarm Hashtag Usages in Tweets for Irony Detection, ACL2018.
[7] Huayi Li, Arjun Mukherjee et al.Extracting Verb Expressions Implying Negative Opinions. AAAI 2015.
[8] Yu-Hsiang Huang, Hen-Hsen Huang et al.Irony Detection with Attentive Recurrent Neural Networks, ECIR 2017.
[9] Uraz Yavanoglu et al, A Review onSarcasm Detection from Machine-Learning Perspective, 2017 IEEE 11thInternational Conference on Semantic Computing.
[10] Yi-jie Tang et al, Chinese IronyCorpus Construction and Ironic Structure Analysis, COLING 2014
[11] 邢竹天, 徐扬. 面向网络文本的汉语反讽修辞识别方法研究. 山西大学学报, 2015, 38(3), 385-391.
[12] 孙晓, 何家劲. 任福继. 基于多特征融合的混合神经网络模型讽刺语用判别. 中文信息学报, 2016年06期.
[13] 邓钊, 贾修一. 陈家骏面向微博的中文反语识别研究. CCL 2015.
[14] STEVEN H. H. DING et al, LearningStylometric Representations for Authorship Analysis.
[15] Basant Agarwal, Personality Detection from Text: A Review, InternationalJournal of Computer System, 2014.
[16] Uraz Yavanoglu et al, Technical Review:Sarcasm Detection Algorithms, International Journal of Semantic Computing, Vol.12, No. 3 (2018) 457–478.
本期责任编辑:刘一佳
本期编辑:赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。






