谷歌联合团队论文:什么决定了AI数据集们的生命周期?



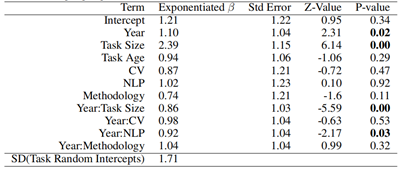
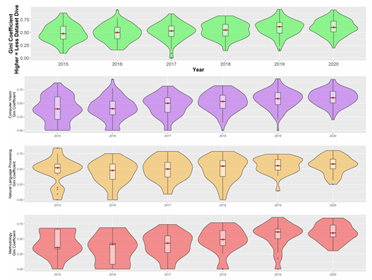

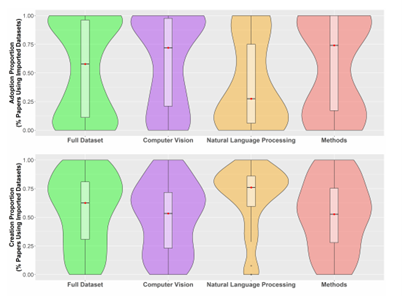
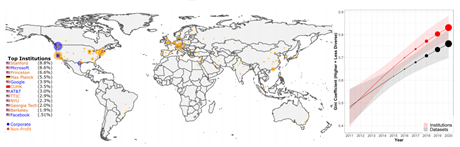

关于【数据实战派】

热门视频推荐
更多精彩视频,尽在学术头条视频号,欢迎关注~

Science公布2021年度十大科学突破,AI这项前所未有的突破上榜

登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月16日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
23+阅读 · 2021年9月29日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月16日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
23+阅读 · 2021年9月29日