WSDM2022 | 数据困境: 我们究竟有多了解推荐系统数据集?
今天跟大家分享一篇获得WSDM2022最佳论文提名奖的论文,不同于以往论文对实验过程以及实验设置的可复现性分析,该论文从实验的根源入手,即主要对我们所使用的推荐系统数据集进行了实验探索,并对实验结果进行了深入分析。

论文:dl.acm.org/doi/10.1145/3488560.3498519
代码:github.com/almightyGOSU/TheDatasetsDilemma
推荐系统在各种各样的场景下取得了长足的发展,比如电商网站、新闻软件以及社交平台等。并且近些年来推荐模型也从简单传统的模型(ItemKNN、PMF)向复杂高级的模型(NCF、DeepCF)发展,这样的发展推动了推荐系统社区的快速进步。
然而,近些年来的相关工作也对当前社区的发展提出了质疑。
文献1发现许多工作不能够复现,有的工作虽然可以复现但性能却大打折扣(可以被许多经典模型所超越),此前我们也对这一工作进行了报道,详情可参阅评论文本信息对推荐真的有用吗?SIGIR20论文告诉你答案以及MLP or IP:推荐模型到底用哪个更好?。
文献2则发现对物品进行采样用于评测(sampled metrics)与用全部物品集合进行评测的结果存在不一致的情况,因此大部分所发表的文章的性能也有待检验。
本文则从另一个角度,即从数据集本身的角度来探讨是否会对推荐模型的性能有所影响,因此作者发出了“How much do we really Know about recommendation datasets”的疑问。为了回答这个问题,作者进行了三方面的工作:
1. 作者首先对近年来的48篇顶会论文进行了分析,并展示在这些论文中是怎样使用这些不同的数据集的。
2. 另外作者还介绍了不同数据集的特征,并说明了这些数据集的相似性与不同之处。
3. 最后,作者通过实验来验证是否对于数据集的选择可以影响之前所得到的观察与结论。
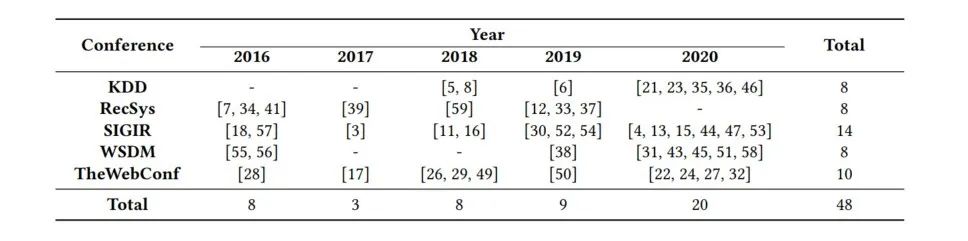
通过对下述5个顶会近5年(2016-2020)年发表的48篇论文进行整理,如下。选择这48篇文章的原则包括:包含关键字“recommend”或者“collaborative”,并且这些论文是针对排序或者分类任务,评价指标为Precision、Recall和nDCG,以及至少使用1个公开数据集。
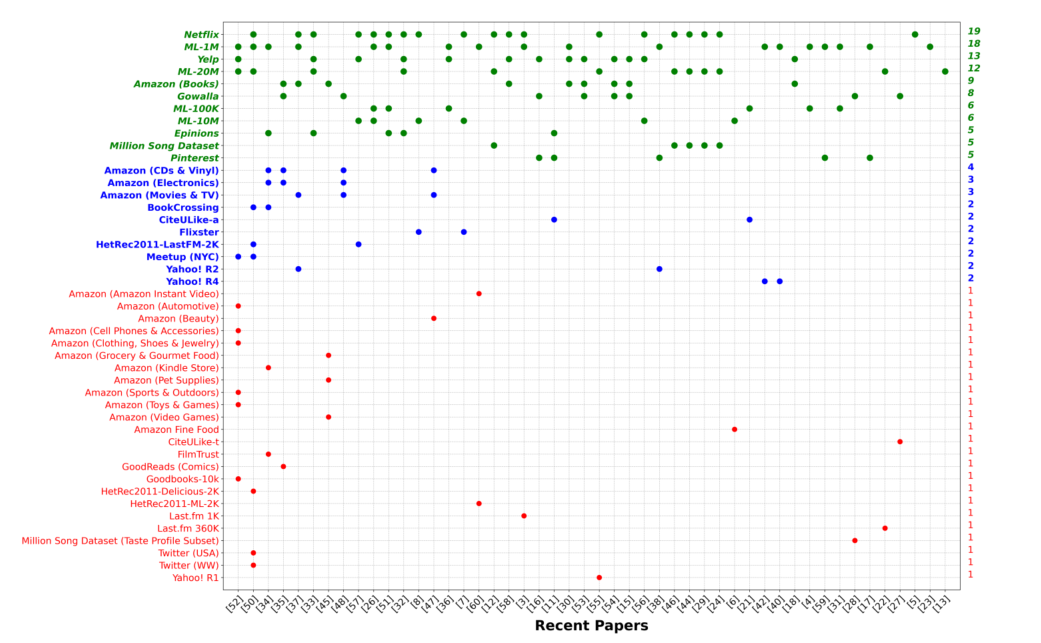
通过对上述论文进行整理发现了45个公开数据集(在我看来分析的数据样本还是有点少o(╥﹏╥)o),具体的数据集名称如下,可以看出Netflix、MovieLens-1M、Yelp以及Movielens-20M是比较受欢迎的。
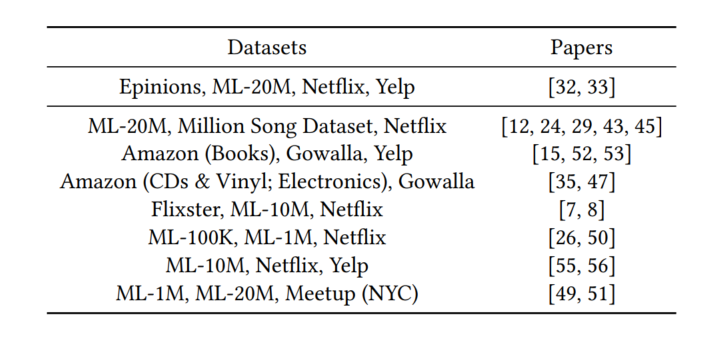
另外,通过利用Apriori算法来对这些论文可能结合的数据集模式进行分析发现,以下数据集组合经常在统一论文中出现,比如ML-20M与Netflix等。另外作者发现,尽管上述论文都解决了基于top-K推荐的隐式反馈问题,但分析表明,数据集的选择往往是任意决定的。即使两篇论文在同一数据集上进行了评价,由于数据预处理或分割策略不同,结果可能不具有可比性。
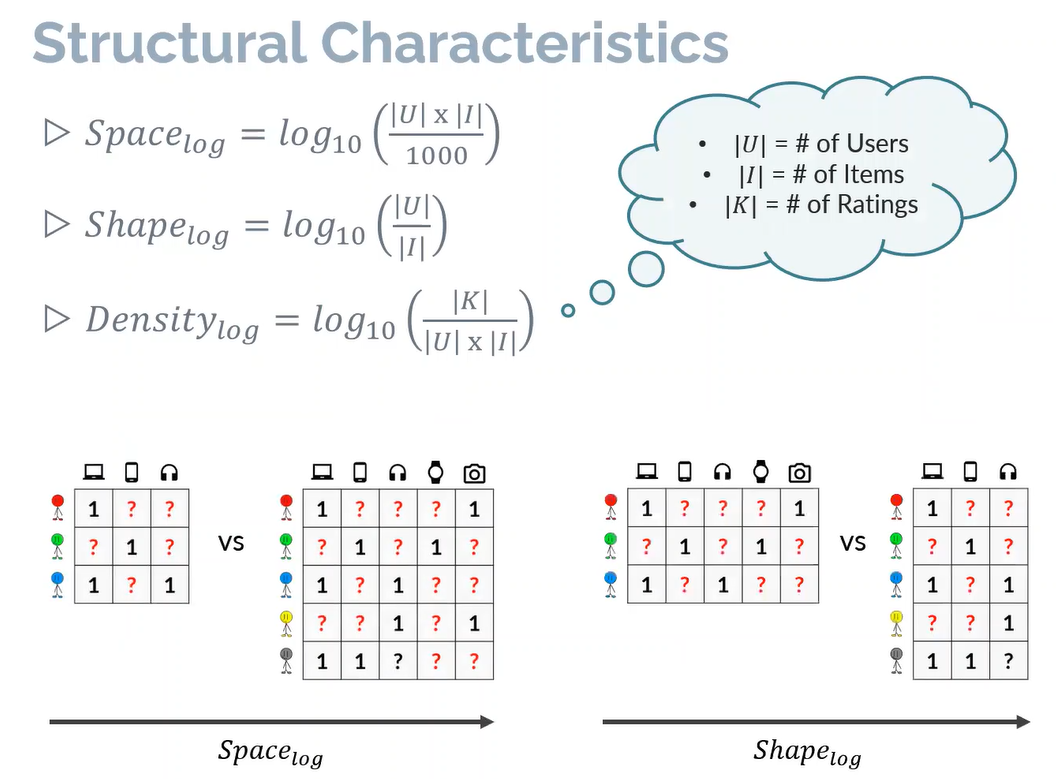
另外,作者还分析了数据集的结构特性(Structural Characteristics),主要反映在空间指标、形状指标以及稠密度指标上。通过下述公式可以看出空间指标反映了用户-物品矩阵空间的大小,形状指标反映了用户与物品的比例,稠密度指标则反映了观测数据相对于所有数据的比例。
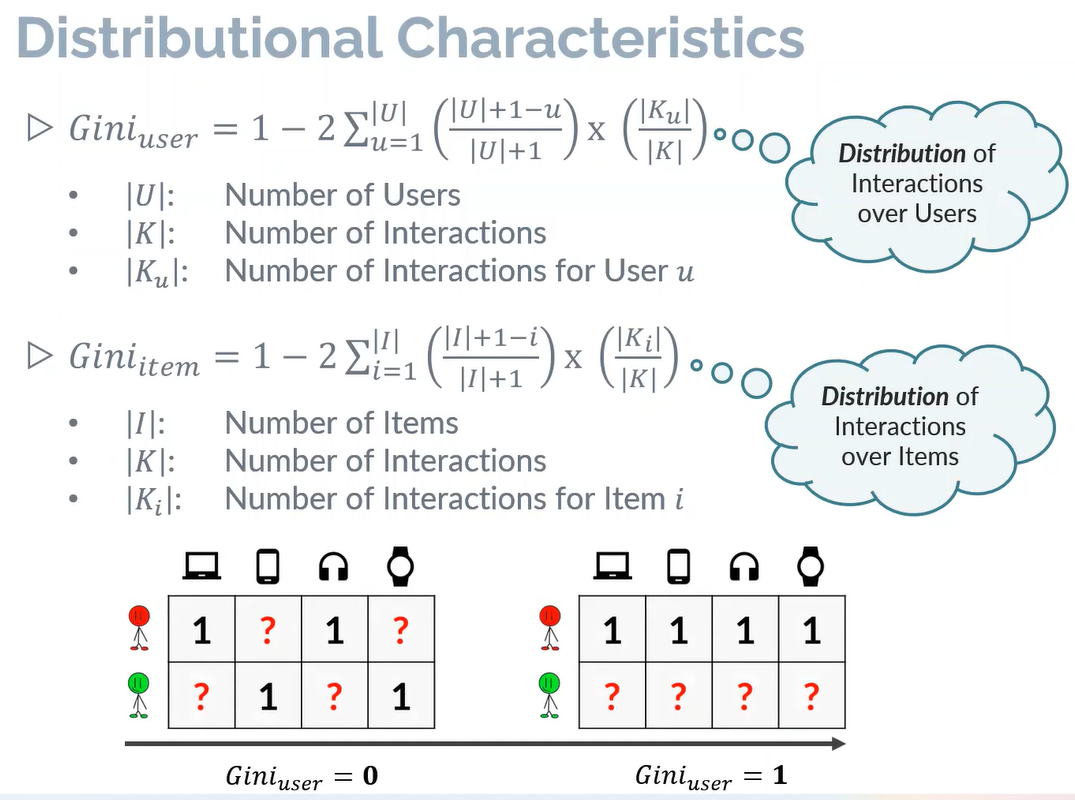
还通过用户侧和物品侧的基尼系数来发现数据集的分布指标。
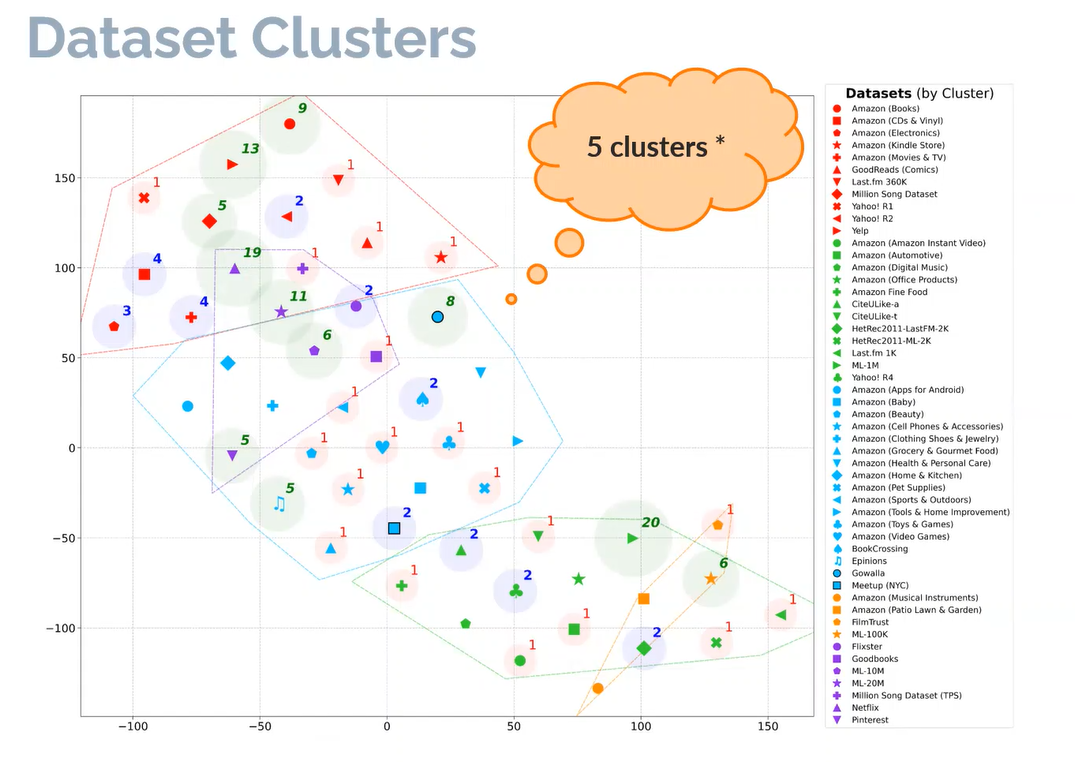
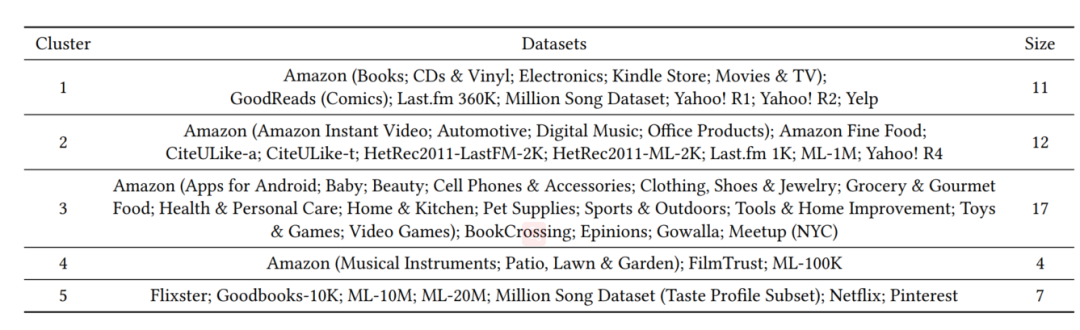
作者根据上述5个指标来对数据集进行聚类然后获得了5个簇,每个簇内的数据集相似,簇间的数据集则不太相似。
下表展示了5个指标在5个簇中心的结果(用矩阵形式表示)。
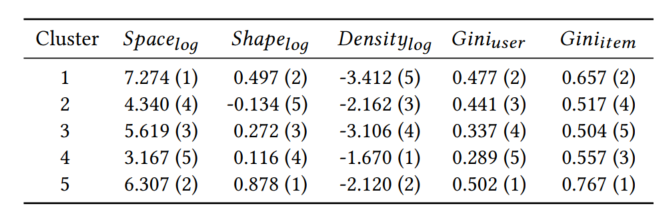
通过上述5个指标利用k-means算法得到的详细聚类结果可见下表。
最后,作者选取了5个典型算法(UserKNN、ItemKNN、RP3Beta、WMF以及Mult-VAE)在上述不同的簇中选取了3个数据集进行测试,来探索在不同的簇中测试的推荐效果是否一致。

通过实验验证发现,对于不同相似性的数据集,算法的性能排名则不同,比如簇3中最好的算法RP3Beta在簇5中则最差。
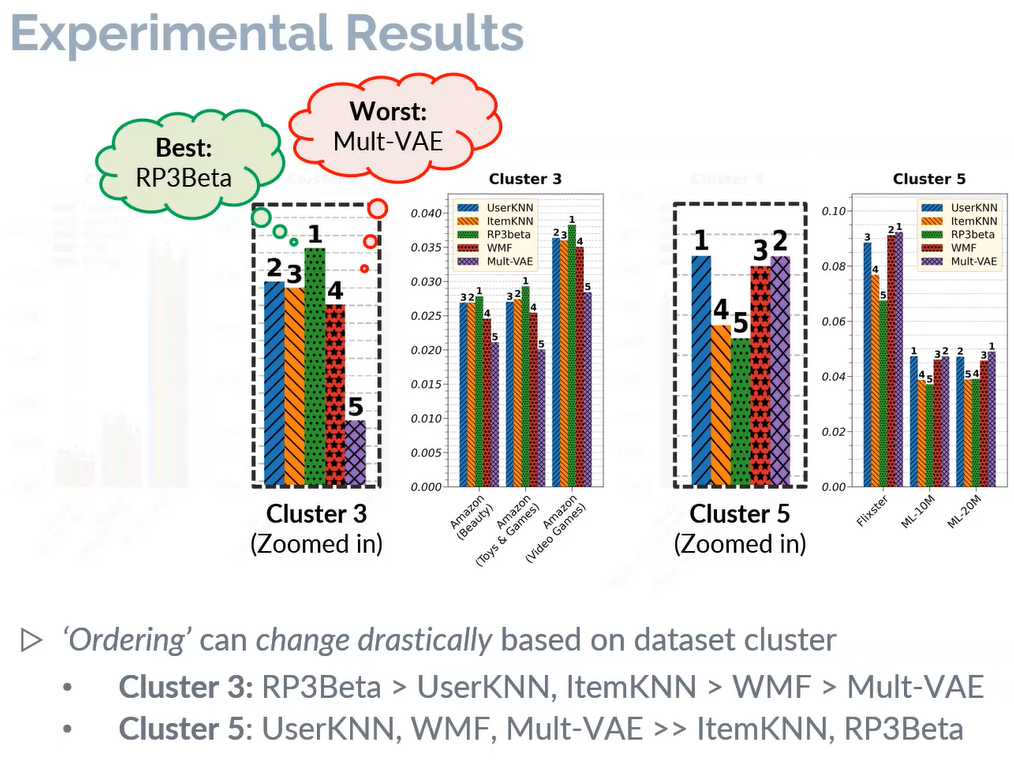
最后得出结论,对于数据集的选择实际上可能会影响从实验评估中获得的观察和结论。由于研究人员面临不同的研究条件,强迫他们利用完全一致的数据集进行对比不太现实。因此考虑到有大量可供选择的公开数据集,该论文强烈建议使用具有不同特征的数据集(在不同簇里的数据集)作为评估过程的一部分,对于算法的鲁棒性以及公平性来说很有必要。
作者在WSDM会议上关于论文介绍的视频已在下方展示,大家可以进行观看。
参考文献
-
Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches. In RecSys ’19. 101–109. On Sampled Metrics for Item Recommendation. In KDD ’20. 1748–1757.
Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison. In RecSys ’20. 23–32.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。



