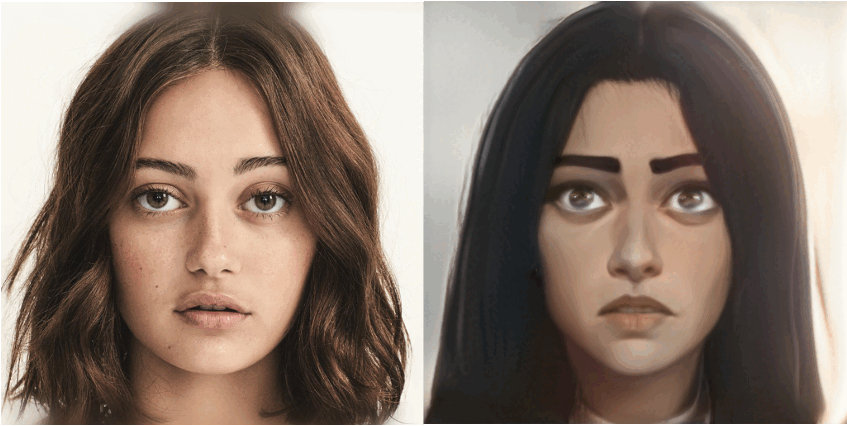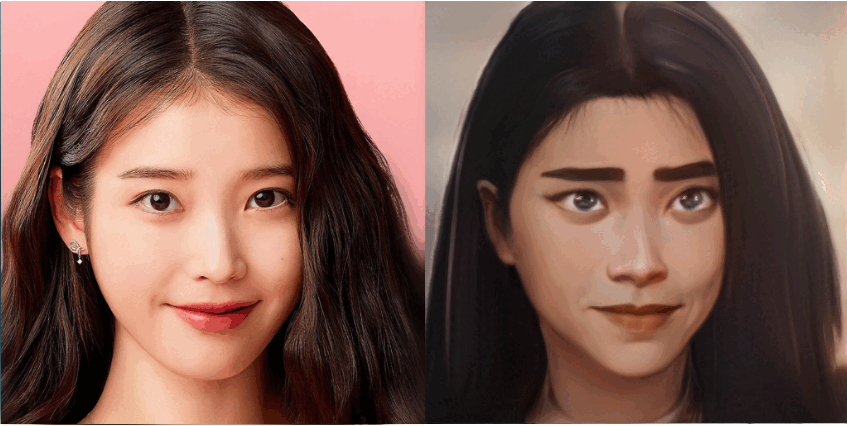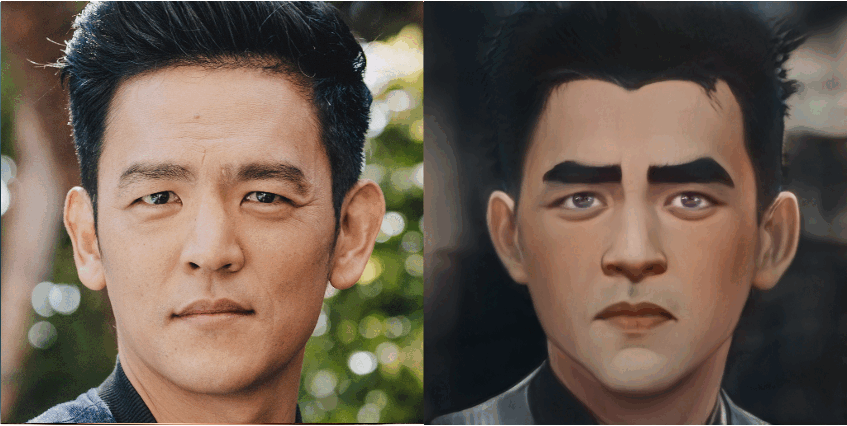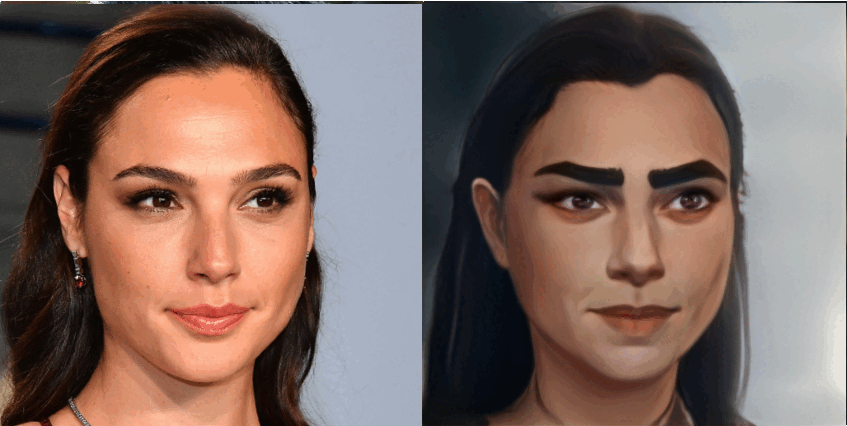JoJoGAN生成的漫画脸可以细致到捕获眼睛形状和细节。
喜欢看漫画的小伙伴,或多或少都听过《JOJO 的奇妙冒险》,简称 JOJO,这是一本由日本漫画家荒木飞吕彦所著漫画,其独特的画风,令人惊叹的剧情,可谓是青少年漫画的必看作。
好的作品总是给人以灵感,来自伊利诺伊大学厄巴纳 - 香槟分校(University of Illinois at Urbana-Champaign,UIUC)的研究者以 JOJO 为灵感,开发出一款漫画生成框架 JoJoGAN,该框架可以将任意人脸进行风格化。用户只需要给定一个单一的输入风格参照(如下图第一排图像,包括不同的动漫和卡通人物),JoJoGAN 就能将该风格应用到任何输入图像上(如下图最左边的歌手 IU,马斯克),生成的图像风格特征都保留完好,如眼睛、发色等。
例如生成长发公主风格的马斯克,眼睛大大的马斯克看起来还挺萌:
![]()
![]()
JoJoGAN 还能在线试玩,你也可以输入自己的图片查看生成的漫画脸,这里,我们也试玩了一下,效果还不错:
![]()
试玩地址:https://huggingface.co/spaces/akhaliq/JoJoGAN
![]()
总体而言,JoJoGAN 首先对一个成对的训练数据集进行近似,然后微调 StyleGAN,以执行单次(one-shot)面部风格化。该研究表明,JoJoGAN 在零监督的情况下,可以很好的保留参考图像的风格细节,还能泛化到不同的风格。
JoJoGAN 通过对具有单个参照风格图像的预训练 StyleGAN2 的微调来工作,具体分为以下四个步骤:
通过 GAN 翻转参照风格图像 y 来准备近似成对训练数据,得到的风格代码 w 可以生成合理的真实人脸图像 x;
找出生成真实人脸图像 x 族的 w 族,它应该与参照风格图像 y 相匹配。形成(w_i, y)对,作为成对训练集;
根据这些成对训练数据进行微调;
使用微调后的 StyleGAN 生成新的样本。
![]()
使用成对数据进行训练时图像风格化任务的最佳选择,但是,成对数据不易获得,需要耗费大量时间和资源。目前,领域内没有适合本研究中任务的好的开源成对数据集。
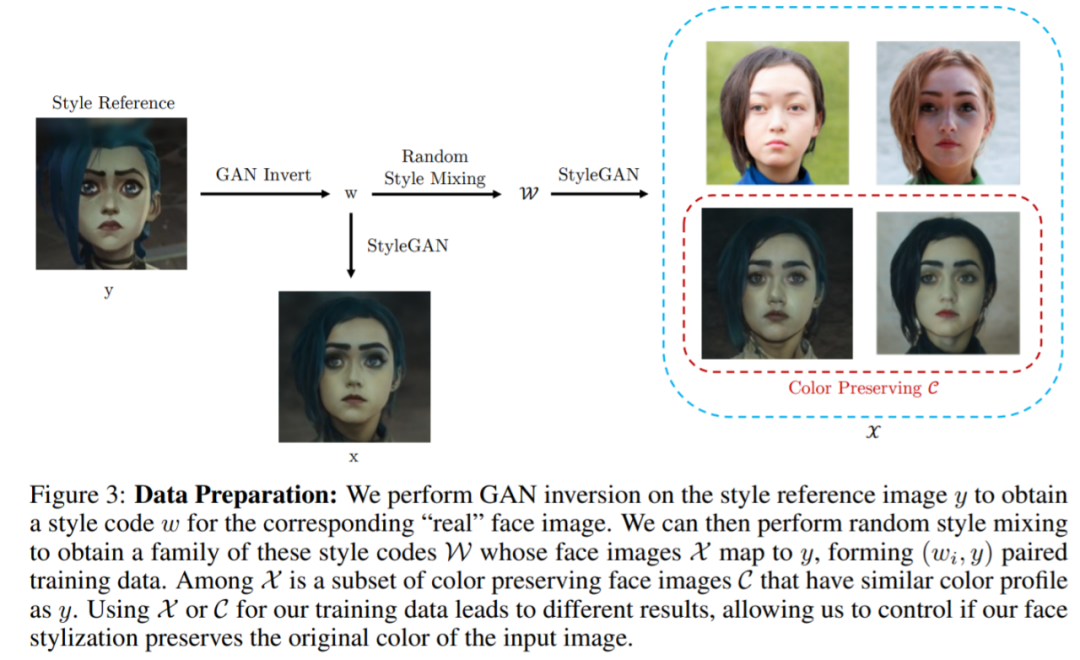
因此,研究者想要通过如下图 3 中的近似成对训练数据集来克服这一问题。给定一个风格参照图像 y,他们使用 e4e 框架执行 GAN 反转以获得 W。由于 e4e 是在真实人脸数据集上训练的,无法泛化到分布外(out-of-distribution)风格图像,因而为研究者提供了一个近似真实人脸图像 y 的 w,形成了一个成对的(w, y)训练集。
![]()
但是,仅使用单个数据点进行训练导致对其他图像的泛化效果较差,如下图 4 所示。因此,研究者通过生成更多训练数据点来克服这一问题。思路很简单,很多真实人脸图像应该与相同风格的参照图像相匹配。例如,眼睛大小或头发纹理略有不同的人脸可以与相同的参照图像相匹配。
![]()
最后,研究者使用 Adam 优化器、以 2×10^-3 的学习率对 JoJoGAN 进行 500 次迭代的微调,在 Nvidia A40 上仅花费 1 分钟左右。
研究者将不保留颜色(non-color preserving)的 JoJoGAN 与当前 SOTA 单 / 小样本风格化方法 StyleGAN-NADA 和 BlendGAN 进行了比较。结果显示,JoJoGAN 可以捕捉定义风格的小细节,同时保持清晰的输入人脸身份特征。
如下图 5a 所示,JoJoGAN 完美地捕捉到了眼睛形状和细节以及来自风格参照的发饰;图 5d 中,JoJoGAN 准确地捕捉到了复杂的面部彩绘。相比之下,虽然 StyleGAN-NADA 也捕捉到了整体小丑妆容,但未能捕捉到眼睛和眉毛等细节,身份特征也受到了大的影响。BlendGAN 未能捕捉到有意义的风格细节,甚至连发型的颜色都不匹配。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com