点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
本文转载自:机器之心
上个月,计算机视觉顶会 CVPR 2020 接收论文结果已经正式公布。在 6656 篇有效投稿中,最终有 1470 篇论文被接收,录取率约为 22%。厦门大学媒体分析与计算实验室共有 11 篇论文接受,其中两篇为 Oral。本文将介绍一篇CVPR 2020 Oral 论文,作者来自厦门大学、深度赋智和西安电子科技大,其提出的单阶段协同学习网络在目标检测和目标分割任务中均实现了新的SOTA性能。
![]()
该论文名为《Multi-task Collaborative Network for Joint Referring Expression Comprehension and Segmentation》,其首次提出单阶段的协同学习网络来同时解决指向性目标检测(Referring Expression Comprehension)和指向性目标分割(Referring Expression Segmentation)两个任务,而且在性能超越了 SOTAs 的条件下,达到了实时检测和协同检测的目的。
论文的共同一作为厦门大学媒体分析与计算实验室(纪荣嵘 团队)硕士生罗根和博士后周奕毅,并由厦门大学媒体分析与计算实验室(纪荣嵘团队)和深度赋智合作指导完 成。以下是论文一作罗根对该论文做出的解读:
![]()
给定一句语言描述,Referring Expression Comprehension (REC) 旨在检测出与该描述相关的目标 bounding box,而 Referring Expression Segmentation (RES) 旨在分割出对应目标。REC 和 RES 长期以来被当成两个不同的 任务来看待并被设计出了大量的单任务网络,例如将语言模块嵌入到语义分割网络(RES)或者利用语言来检索目标(REC)。尽管其中有一些基于目标检索的多阶段网络,例如 MAttNet,能得到两个任务的结果,但究其本质仍是单任务的检索(ranking)网络,其多任务的结果归根于后端的 mask-rcnn。
与此同时,这种依赖于预训练目标检测器先提特征后利用语言特征和其进行交互检索的方式不仅仅费时费力,而且有如下弊端:1)两个任务无法在多模态学习中相互促进;2)frcnn/mrcnn 特征丢失了预训练 CNN 网络的关系先验和空间先验;3)当 proposals 中没有候选目标,检索网络将毫无疑问会失败。
我们认为过去的方法不是解决这两个任务的最佳范式。实际上,这两个任务之间高度趋近且能够互相促进。比如,RES 任务详细的标签能指导视觉和文本之间的对齐而 REC 任务得到更好的定位能力也能帮助 RES 确定目标。因此,很自然地能想到把这两个任务放到一个单阶段网络里学习,在保证速度和精度的同时,又能使两个任务的学习互相促
进。并且这样的多任务尝试在计算机视觉领域已经非常成功,即实例分割(Instance Segmentation)。
但与实例分割不同,这样的联合训练仍存在一个重大问题,即预测分歧 (Prediction Conflict). 预测分歧其实也会存在于实例分割当中,比如框出来的物体没有被分割出来,但对于任务本身的目的而言,这个问题不会显得那么严重。而这个问题在语言指导下的 RES 和 REC 中则会尤为突出:
![]()
如上图所示,这样的错误放在 RES 和 REC 中是不可接受的。因此,在解决多任务学习的同时,我们还要考虑两个任务之间的协同性的问题,就此本文首次提出了一种高效且有效的单阶段协同学习网络。
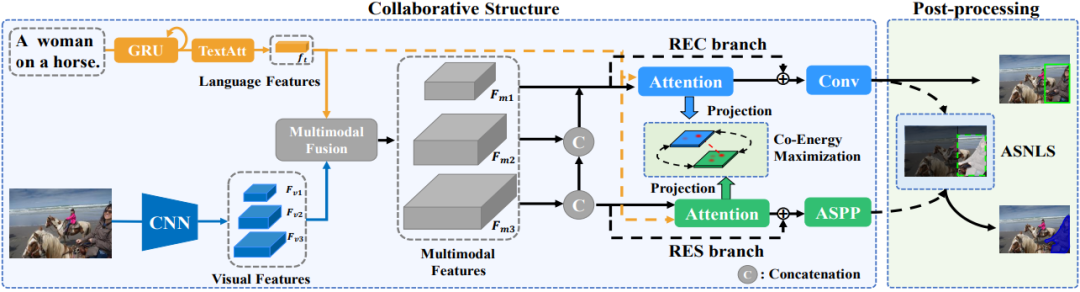
方法上可以分为网络结构和解决预测分歧的设计两块内容,整体框架如下图所示:
![]()
网络结构上,我们要尽可能保证两个任务之间能相互促进,同时各个部分的设计要复合两个任务的属性。首先我们对视觉特征和语言特征进行多模态多尺度的 fusion。在 REC 部分,我们采用了单尺度的预测并通过一条通路将浅层的多模态特征回传过来。这样的设计一方面考虑到浅层特征带有更多的纹理、颜色信息并且受到 RES 任务的直接监督因而能够促进语言语义的理解,另一方面由于 REC 任务中的 targets 较少,多尺度的预测往往在训练中会带来巨大的负样本数。而 RES 部分,则需要大的分辨率的感受野,因此网络的输出尺度增大同时配备了 ASPP 来增加感受野。
此外,两个任务分支间的多次交互保证了在训练过程中能够互相促进。训练阶段,REC 分支回归出 bounding box 以及预测对应的 confidence score,其过程类似于 Yolov3。而 RES 分支则预测出关于目标的概率图,具体细节可以参见论文或者代码。
预测分歧问题的出现,一方面是由于 RES 定位能力弱造成的(RES 无法精确定位特定的目标而只能得到分割像素的集合,但这不能保证该集合就只包含或者完整包含了指向性物体),另一方面也是由于 RES 的任务更加复杂(在目标不够显著的情况下,REC 仍能得到正确的 bounding box 而 RES 却不能),对训练和学习的要求更高。因此从这两个角度出发,我们考虑如何增强两个任务间的共同关注,同时减少两者之间的分歧。
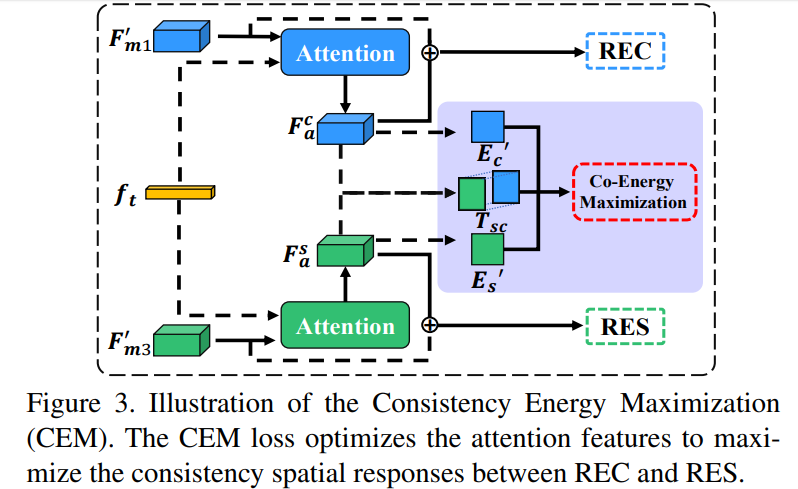
对此我们提出了协同能量最大化 (Consistency Energy Maximization) 的自监督方法来最大化两者在训练阶段的协同,同时提出了自适应软非定位区域抑制(Adaptive Soft Non-Located Suppression)来在测试阶段利用 REC 的定位能力帮助 RES 更好地定位和区分目标。以上两种方式几乎不会带来任何的额外训练/测试成本,同时能够大大增强两个任务的共同关注。
协同能量最大化 (Consistency Energy Maximization) :
![]()
首先考虑训练的问题就需要明确优化的目标,很显然我们要优化两个任务分支的共同关注,但由于两个任务的特征以及性质上有所差异,直接优化两路特征往往会很大程度上影响性能。一个更好的选择则是优化 Attention 特征。一方面 Attention 特征能够更直接地反映出两个任务的关注,另一方面通过残差连接作为额外信息也不会影响原有信息。
这里的 Attention 可以为任意的 Attention,文中我们采用了过去的工作(GARAN Attention)来得到 RES 和 REC 的 Attention 特征分别定义为
![]() 和
和
![]() 。
接着我们将 Attention 特征投影到平面空间来获得 RES 和 REC 的空间关注(能量幅值):
。
接着我们将 Attention 特征投影到平面空间来获得 RES 和 REC 的空间关注(能量幅值):
![]()
![]() 和
和![]() 经过 Softmax 进行归一化后得到
经过 Softmax 进行归一化后得到![]() 和
和![]() 。接着我们考虑
。接着我们考虑![]() 和
和![]() 之间的关系(能量夹角),这里我们用余弦相似度来刻画:
之间的关系(能量夹角),这里我们用余弦相似度来刻画:
![]()
其中
![]() 和
和
![]() 为常数项用于归一化。
最终协同能量
为常数项用于归一化。
最终协同能量
![]() 可以被定义为:
可以被定义为:
![]()
最终我们通过最大化![]() 来使得两个任务在训练中协同,其中前三项能够最大化共同关注的能量,后两项能够约束非共同关注的能量。
自适应软非定位区域抑制(Adaptive Soft Non-Located Suppression)
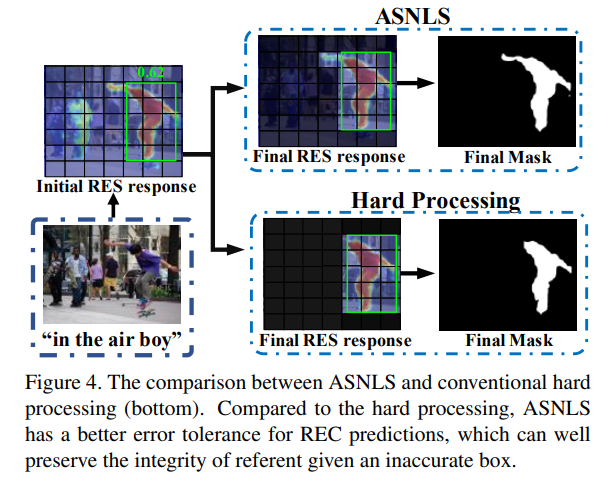
为了在测试阶段能够更好的帮助 RES 定位目标,一个自然地想法是采取传统目标检测/实例分割中的 box crop 的方式,利用 REC 检测出来的 box 对 RES 预测出的概率分割图进行裁剪,接着再将其二值化。然而,这种硬性裁剪的方式及其容易将目标的部分也裁剪掉,从而导致性能的下降:
来使得两个任务在训练中协同,其中前三项能够最大化共同关注的能量,后两项能够约束非共同关注的能量。
自适应软非定位区域抑制(Adaptive Soft Non-Located Suppression)
为了在测试阶段能够更好的帮助 RES 定位目标,一个自然地想法是采取传统目标检测/实例分割中的 box crop 的方式,利用 REC 检测出来的 box 对 RES 预测出的概率分割图进行裁剪,接着再将其二值化。然而,这种硬性裁剪的方式及其容易将目标的部分也裁剪掉,从而导致性能的下降:
![]()
对此,我们提出了一个 Soft 的方式来对框内和框外的分割图概率分布进行重新加权/抑制。给定一个 RES 分支预测的 mask
![]() ,
以及 REC 预测的 bounding box
,
以及 REC 预测的 bounding box
![]() ,中的每个元素
,中的每个元素
![]() 会按下式更新:
会按下式更新:
![]()
其中
![]() and
and
![]() 为加权因子和衰减因子,最后我们再对
为加权因子和衰减因子,最后我们再对
![]() 进行二值化,这样的结果比直接的
裁剪方式具有更强的鲁棒性。更进一步地,要如何针对每个不同的样本确定
进行二值化,这样的结果比直接的
裁剪方式具有更强的鲁棒性。更进一步地,要如何针对每个不同的样本确定
![]() 和
和
![]() 呢?
我们通过 bounding box 的 confidence score
呢?
我们通过 bounding box 的 confidence score
![]() 来对其进行建模。
理由也很直观,
来对其进行建模。
理由也很直观,![]() 隐式地建模了框内特征的显著性,通过
隐式地建模了框内特征的显著性,通过![]() 我们能很好地得到不同样本的加权因子和衰减因此。
文中我们采用了如下简单有效的线性关系建模:
我们能很好地得到不同样本的加权因子和衰减因此。
文中我们采用了如下简单有效的线性关系建模:
![]()
其中
![]() ,
,
![]() ,
,
![]() and
and
![]() 为超参,来调节加权和衰减的幅度。
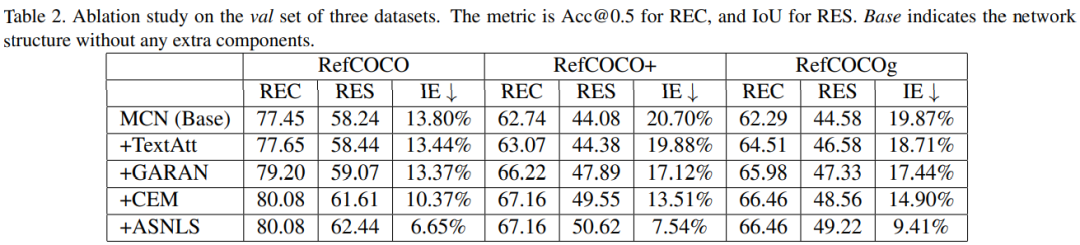
实验设计上,为了量化地衡量 prediction conflict,我们设计了一个新的评价指标 Inconsistency Error(IE)。它用于计算 REC 结果与 RES 结果不一致的比例。简单来说,IE 计算了 REC 正确时 RES 错误以及 RES 正确时 REC 错误这两种情况在所有样本中的比例。
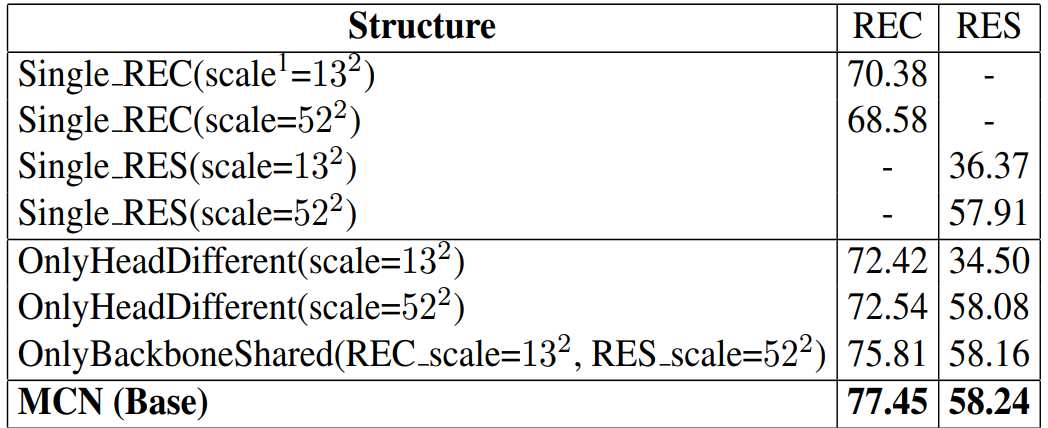
实验部分,我们首先比较了网络结构,将我们设计的结构与几种可能的搭配以及单任务的网络进行比较,结果显示我们的网络设计在两个任务的性能上是最优的:
为超参,来调节加权和衰减的幅度。
实验设计上,为了量化地衡量 prediction conflict,我们设计了一个新的评价指标 Inconsistency Error(IE)。它用于计算 REC 结果与 RES 结果不一致的比例。简单来说,IE 计算了 REC 正确时 RES 错误以及 RES 正确时 REC 错误这两种情况在所有样本中的比例。
实验部分,我们首先比较了网络结构,将我们设计的结构与几种可能的搭配以及单任务的网络进行比较,结果显示我们的网络设计在两个任务的性能上是最优的:
![]()
接着,我们比较了不同的推理阶段后处理的方式,结果显示 Soft-NLS 以及 ASNLS 具有更好的鲁棒性,同时够大大降低 IE score。
![]()
然后我们进行了控制变量实验,可以看到各个部分都能有效地改进性能,同时我们提出的两个设计能够大大降低 IE score。
![]()
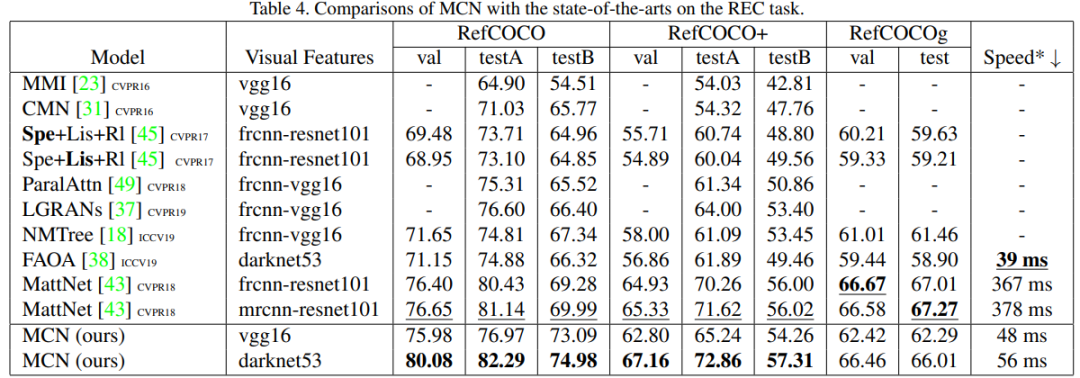
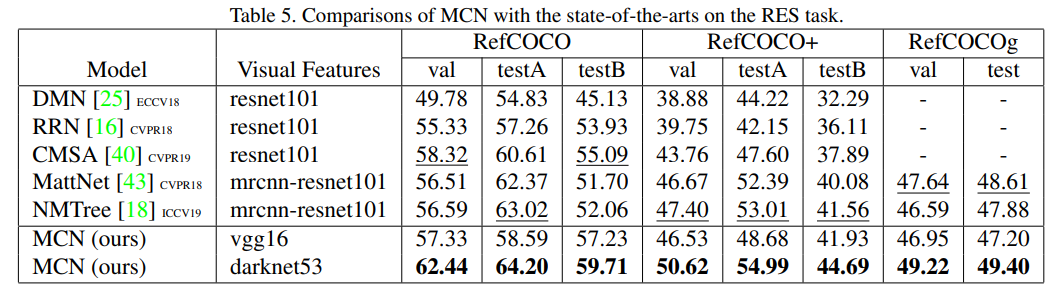
最后我们在两个任务上和目前的 SOTAs 进行了比较,结果显示,在两个任务上性能均领先于 SOTAs 的情况下,我们的模型还达到了实时的检测。
![]()
![]()
实际上,RES 和 REC 只是 language+vision 任务中的一个重要分支,包括另外一些多模态任务在内,过去大家都非常青睐于 FRCNN 的特征,直觉上它可能会表现更好,但很多的事实表明它具有一些劣势并且性能上不会优于 Grid 特征。有兴趣的可以看一下 CVPR 2020 的一篇文章《In Defense of Grid Features for Visual Question Answering》(实验设计堪称典范)。
因此 single-stage 可能会成为一个趋势。除此之外,很多多模态任务之间都有着千丝万缕的关系,如何求同存异可能会是比 bert 这一类预训练模型更值得研究的方向。这两点同时也是本文的两个非常重要的支撑点,也可能是未来进一步发展的方向。
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集3500人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!




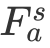 和
和
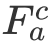 。
接着我们将 Attention 特征投影到平面空间来获得 RES 和 REC 的空间关注(能量幅值):
。
接着我们将 Attention 特征投影到平面空间来获得 RES 和 REC 的空间关注(能量幅值):
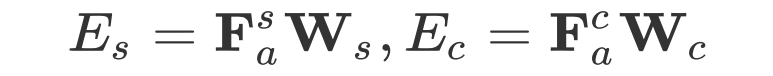
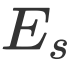
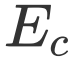
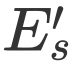
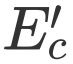
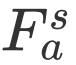
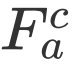
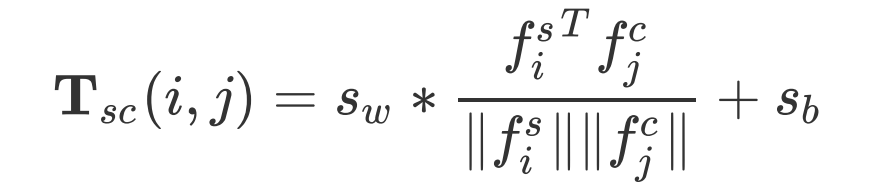
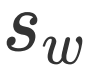 和
和
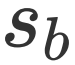 为常数项用于归一化。
最终协同能量
为常数项用于归一化。
最终协同能量
 可以被定义为:
可以被定义为:
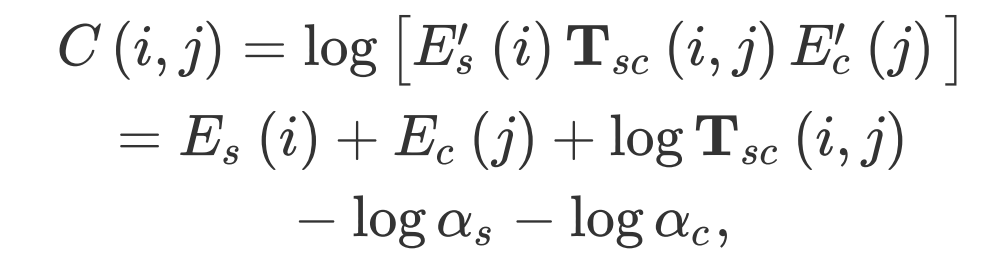
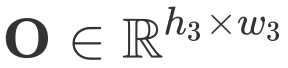 ,
以及 REC 预测的 bounding box
,
以及 REC 预测的 bounding box
 ,中的每个元素
,中的每个元素
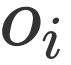 会按下式更新:
会按下式更新:
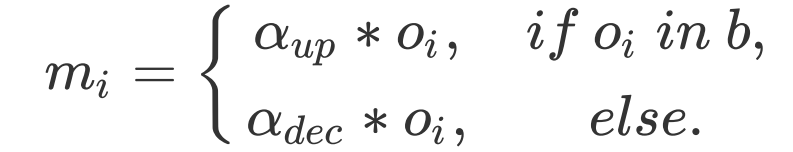
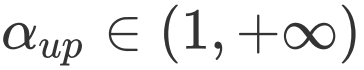 and
and
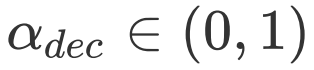 为加权因子和衰减因子,最后我们再对
为加权因子和衰减因子,最后我们再对
 进行二值化,这样的结果比直接的
裁剪方式具有更强的鲁棒性。更进一步地,要如何针对每个不同的样本确定
进行二值化,这样的结果比直接的
裁剪方式具有更强的鲁棒性。更进一步地,要如何针对每个不同的样本确定
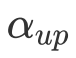 和
和
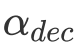 呢?
我们通过 bounding box 的 confidence score
呢?
我们通过 bounding box 的 confidence score
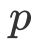 来对其进行建模。
理由也很直观,
来对其进行建模。
理由也很直观,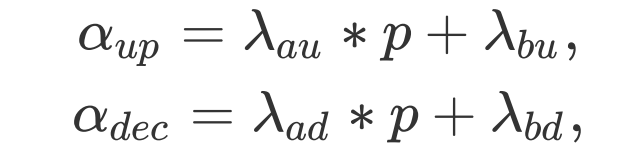
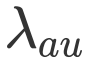 ,
,
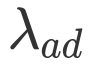 ,
,
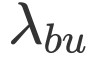 and
and
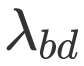 为超参,来调节加权和衰减的幅度。
为超参,来调节加权和衰减的幅度。