阿里开源新一代人机对话模型 ESIM:准确率打破世界纪录,提升至 94.1%!

-> ESIM 引入背景
-> 任务描述

-> 模型说明

输入编码

局部匹配


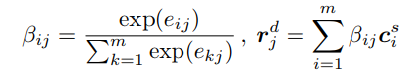
 >,我们可以模拟对齐标记对之间的标记层级语义关系。类似的计算也适用于矢量对<
>,我们可以模拟对齐标记对之间的标记层级语义关系。类似的计算也适用于矢量对<
 >。我们收集如下的局部匹配信息:
>。我们收集如下的局部匹配信息:

 和
和
 。其中 F 是一个单层前馈神经网络,可以使用 RELU 减少维数。
。其中 F 是一个单层前馈神经网络,可以使用 RELU 减少维数。
匹配合成

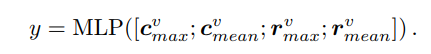
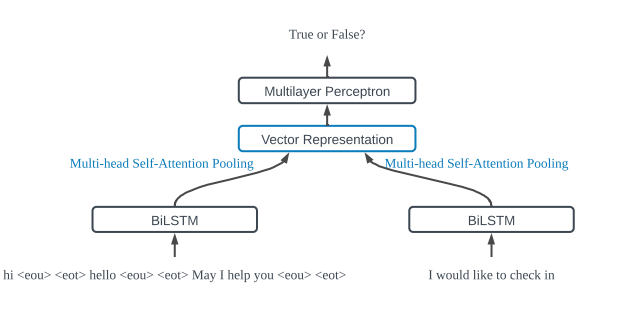
基于句子编码的方法
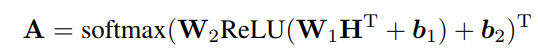
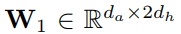
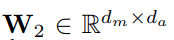 是权重矩阵;
是权重矩阵;
 是偏差; da 是关注网络的维度,dh 是 BiLSTM 的维度。
是偏差; da 是关注网络的维度,dh 是 BiLSTM 的维度。
 是 BiLSTM 的隐藏向量,其中 T 表示序列的长度。
是 BiLSTM 的隐藏向量,其中 T 表示序列的长度。
 是多头注意力机制权重矩阵,其中 dm 是需要使用保持集调整的头数的超参数。我们不是使用最大池或平均池,而是根据权重矩阵 A 对 BiLSTM 隐藏状态 H 求和,以得到输入句子的向量表示:
是多头注意力机制权重矩阵,其中 dm 是需要使用保持集调整的头数的超参数。我们不是使用最大池或平均池,而是根据权重矩阵 A 对 BiLSTM 隐藏状态 H 求和,以得到输入句子的向量表示:
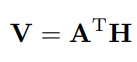
 可以转换为矢量表示
可以转换为矢量表示
 。为了增强句子对之间的关系,与 ESIM 类似,我们将两个句子的嵌入及其绝对差异和元素乘积连接为 MLP 分类器的输入:
。为了增强句子对之间的关系,与 ESIM 类似,我们将两个句子的嵌入及其绝对差异和元素乘积连接为 MLP 分类器的输入:

-> 实验
数据集
数据训练

结果

消融分析
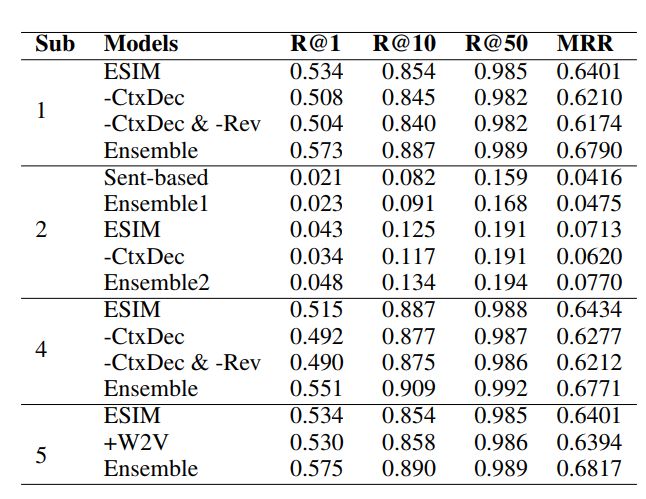

与以前的工作比较

->结论
论文链接: https://arxiv.org/abs/1901.02609 开源地址: https://github.com/alibaba/esim-response-selection


登录查看更多
相关内容
Arxiv
7+阅读 · 2018年4月24日


相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2018年4月24日