SNE-RoadSeg:一种基于表面法向量提取的道路可行驶区域分割方法
 本文解读的是论文《SNE-RoadSeg: Incorporating Surface Normal Information into Semantic Segmentation for Accurate Freespace Detection》,论文作者来自
加州大学圣地亚哥分校和
香港科技大学机器人学院
。
该论文解读首发于“AI算法修炼营”。
本文解读的是论文《SNE-RoadSeg: Incorporating Surface Normal Information into Semantic Segmentation for Accurate Freespace Detection》,论文作者来自
加州大学圣地亚哥分校和
香港科技大学机器人学院
。
该论文解读首发于“AI算法修炼营”。

这篇文章收录于ECCV2020,是一篇关于无碰撞空间区域分割的文章,整体效果很不错。最主要的核心思想是在表面发现估计器的设计,在得到表面法线后将其用于分割网络的编码器环节,并在特征融合部分,借鉴了DenseNet的思想,进行密集连接。网络的计算量和参数量文中并没有比较,应该做不到实时。
论文地址:https://arxiv.org/abs/2008.11351
代码地址:https://github.com/hlwang1124/SNE-RoadSeg
简介
本文方法:SNE-RoadSeg
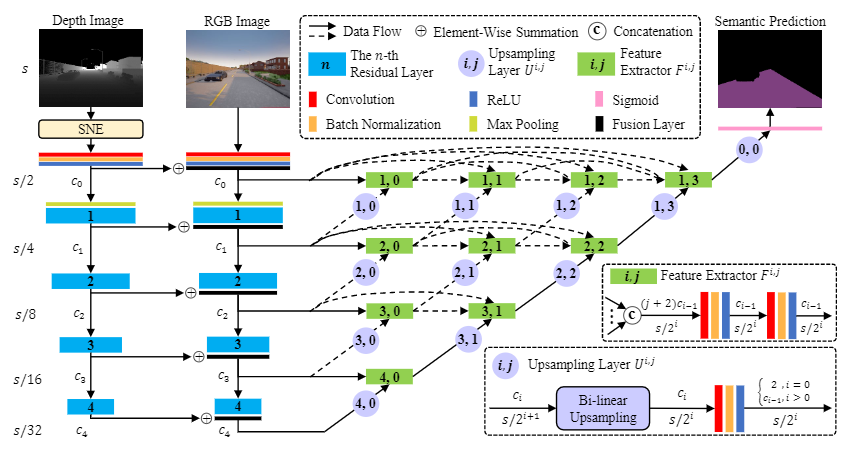
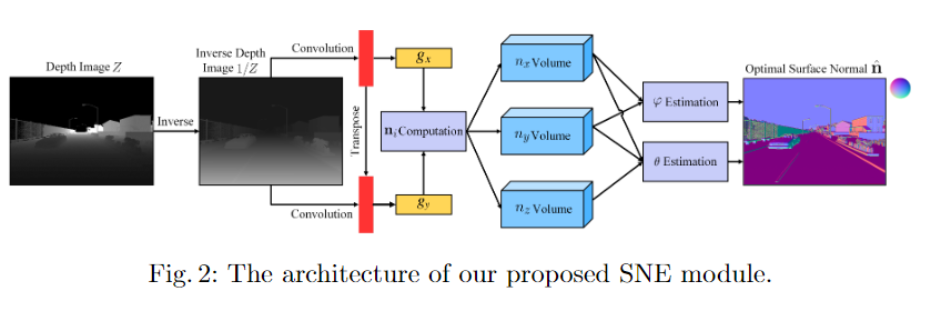
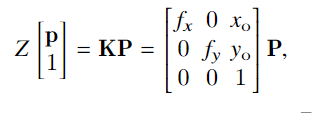
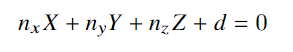
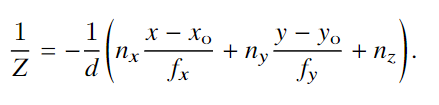
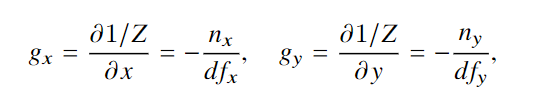
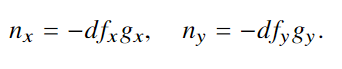
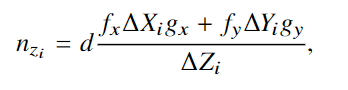
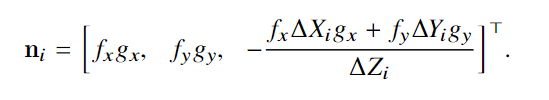
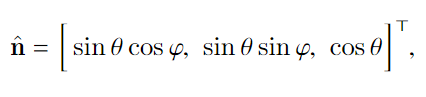
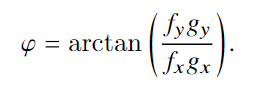
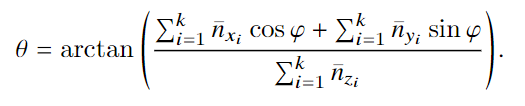
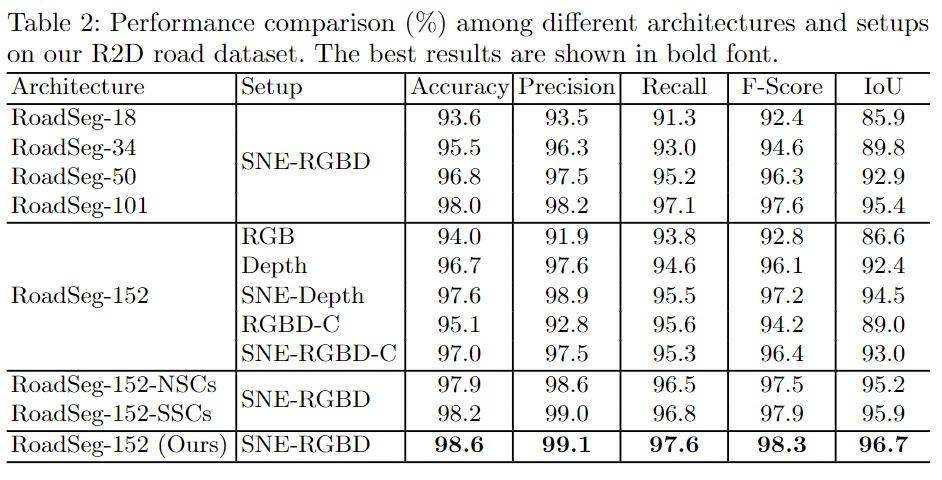
实验与结果
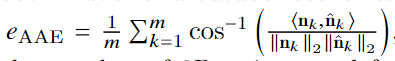
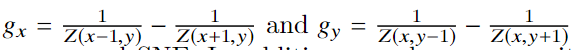

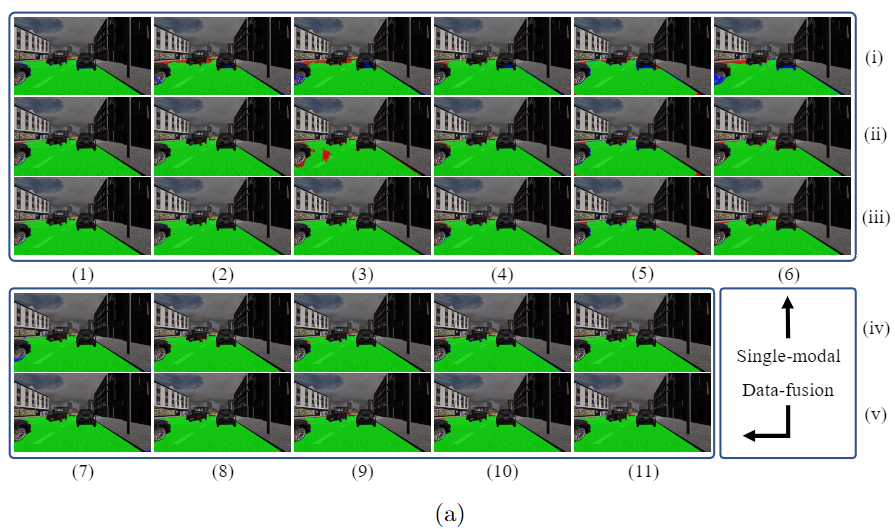
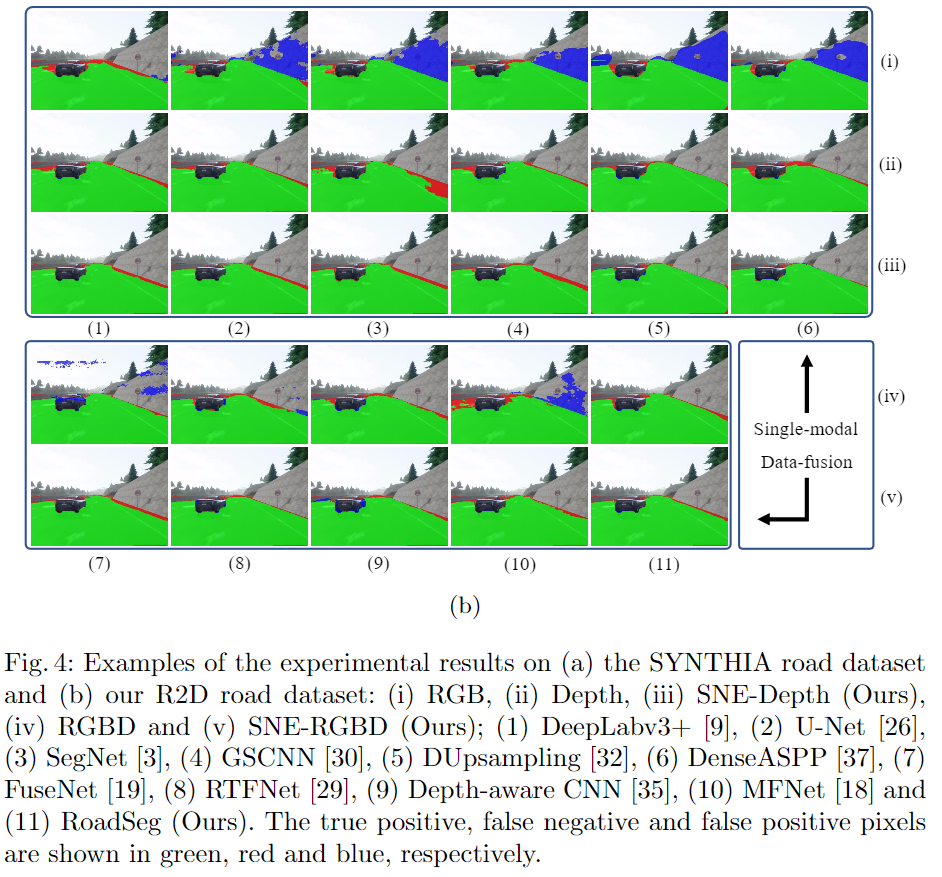
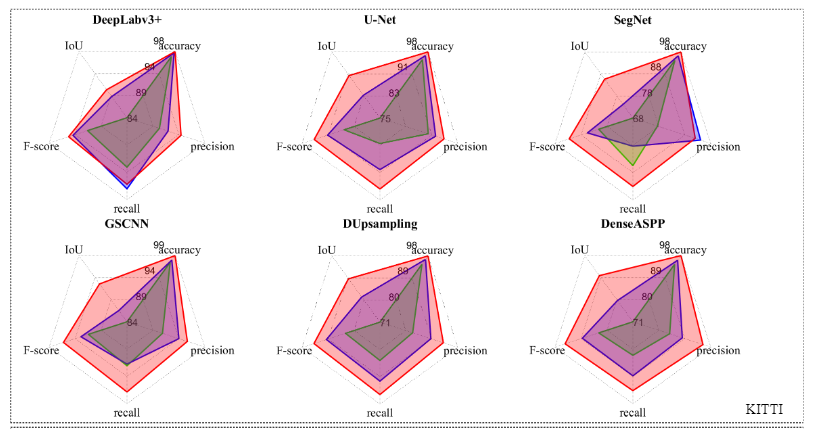
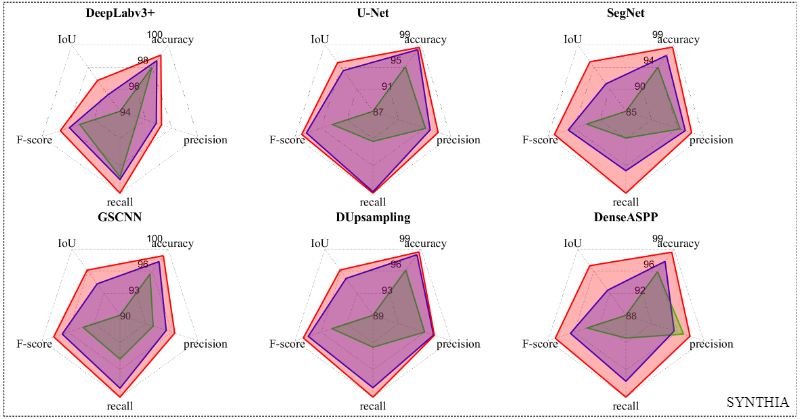
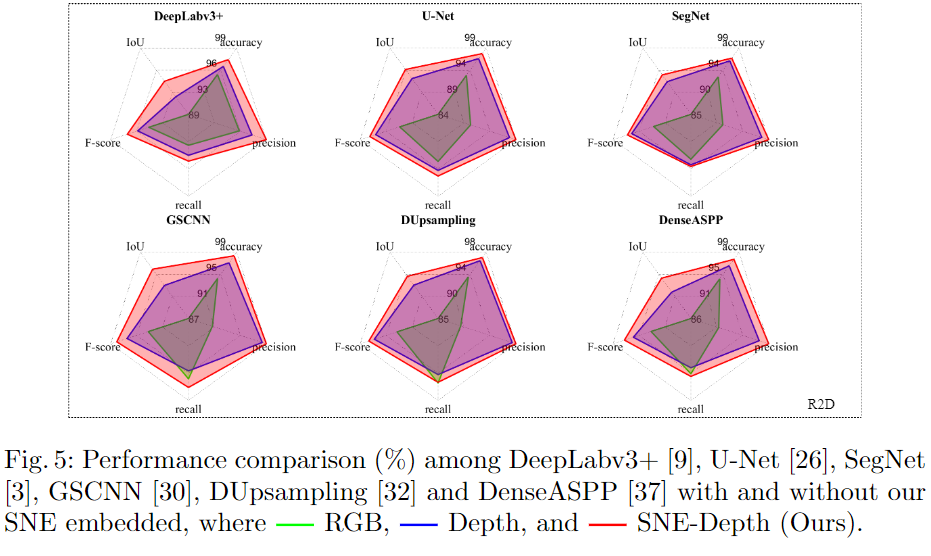
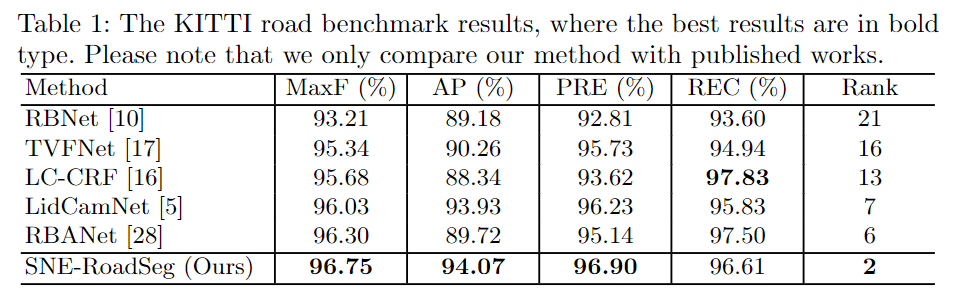


登录查看更多
相关内容

专知会员服务
39+阅读 · 2020年3月19日
Arxiv
0+阅读 · 2020年12月3日
Arxiv
0+阅读 · 2020年12月2日




相关VIP内容
专知会员服务
39+阅读 · 2020年3月19日
相关资讯
相关论文
Arxiv
0+阅读 · 2020年12月3日
Arxiv
0+阅读 · 2020年12月2日