文本挖掘从小白到精通(十四)--- 如何将训练所得的word2vec模型用于后续任务
特别推荐|【文本挖掘系列教程】:

文本挖掘从小白到精通(一)---语料、向量空间和模型的概念
文本挖掘从小白到精通(三)---主题模型和文本数据转换
文本挖掘从小白到精通(五)---主题模型的主题数确定和可视化
文本挖掘从小白到精通(六)---word2vec的训练、使用和可视化
文本挖掘从小白到精通(七)--- Word2vec的增量学习
文本挖掘从小白到精通(八)--- 从海量文章中挖掘主要观点
文本挖掘从小白到精通(九)--- 文本相似性度量
文本挖掘从小白到精通(十)--- 不需设定聚类数的Single-pass
文本挖掘从小白到精通(十一)--- 不需设定聚类数的DBSCAN
文本挖掘从小白到精通(十二)--- 7种简单易行的文本特征提取方法
文本挖掘从小白到精通(十三)--- 文本挖掘中会涉及的若干降维方法
【特辑】文本分类算法集锦,从小白到大牛,附代码注释和训练语料
《文本挖掘从小白到精通》系列的更新中断许久,现在继续更新干货~
之前的文章中有提到word2vec的训练方法,这是关键的一个步骤,但它不是终点,训练好的词嵌入模型可以用于后续的高阶NLP任务。本文将通过3个实际案例,来聊聊如何将训练好的word2vec模型与后续的NLP任务有机结合起来。它们是:
词汇相似度度量
文本分类
词汇分类
这里会用到NLP领域两个重要的库 ---gensim和keras,笔者将gensim模型的封装接口融入到keras的处理流程中,将二者无缝对接,文本挖掘的操作流程将会大大顺畅!
这里,笔者将会用到的一个重要的封装器是gensim.models.keyedvectors中的方法get_keras_embedding。
在使用Word2Vec前, 先导入要用到的库:
import jiebafrom gensim.models import word2vec
接下来,我们创建一个Demo语句集用以训练一个word2vec模型。
sentences = [['social_listening', '市场分析', '调研'],['文本挖掘', 'NLP', '文本处理', '情感分析', 'social_listening', '时效性'],['口碑监测', '声量', '情感分析', '语义分析'],['声量', '口碑监测', '时效性', '调研'],['典型意见挖掘', '文本挖掘', '语义分析'],['social_listening','NLP'],['文本挖掘', 'social_listening'],['市场分析', '用户画像', '口碑监测'],['social_listening', '用户画像', '声量']]
传入适当的参数来创建word2vec模型。
model = word2vec.Word2Vec(sentences, size=100, min_count=1, hs=1)1、与Keras进行融合 --- 词汇相似度度量
作为gensim的word2vec模型与keras接口融合的一个例子,笔者首先考虑词汇相似度任务 --- 通过计算词汇向量的余弦距离来度量两个词汇之间的相似度。
import numpy as npfrom keras.engine import Inputfrom keras.models import Modelfrom keras.layers.merge import dot
使用get_keras_embedding方法返回可用的层。
wv = model.wvembedding_layer = wv.get_keras_embedding()
接下来,我们构建Keras模型。
input_a = Input(shape=(1,), dtype='int32', name='input_a')input_b = Input(shape=(1,), dtype='int32', name='input_b')embedding_a = embedding_layer(input_a)embedding_b = embedding_layer(input_b)similarity = dot([embedding_a, embedding_b], axes=2, normalize=True)keras_model = Model(inputs=[input_a, input_b], outputs=similarity)keras_model.compile(optimizer='sgd', loss='mse')
现在,输入两个要进行比较的词汇,模型返回的数值就是这两个词汇的相似度,数值越大表示两个词汇的含义越接近。
word_a = '文本挖掘'word_b = 'social_listening'# 输出是两个词之间的余弦距离(一种文本相似性度量)output = keras_model.predict([np.asarray([model.wv.vocab[word_a].index]), np.asarray([model.wv.vocab[word_b].index])])print (output[0][0][0])
0.10063825
word_a = '文本挖掘'word_b = '市场分析'# 输出是两个词之间的余弦距离(一种文本相似性度量)output = keras_model.predict([np.asarray([model.wv.vocab[word_a].index]), np.asarray([model.wv.vocab[word_b].index])])print (output[0][0][0])
-0.16512173
word_a = '用户画像'word_b = 'social_listening'# 输出是两个词之间的余弦距离(一种文本相似性度量)output = keras_model.predict([np.asarray([model.wv.vocab[word_a].index]), np.asarray([model.wv.vocab[word_b].index])])print (output[0][0][0])
0.044785
从上面的结果可以看出,基于demo语料,我们可以了解到“文本挖掘”和'social_listening'的内涵比较接近,而文本挖掘”和“市场分析”的内涵则相去甚远。
2、与Keras进行融合 --- 文本分类
为了进一步了解在处理有监督(分类)任务时gensim的Word2Vec模型如何与Keras集成,笔者以一个demo文本分类数据集(包含教育、娱乐、科技和体育这4个类别)。
再次导入必要的分析库。
import osimport sysimport kerasimport numpy as npfrom gensim.modelsimport word2vecfrom keras.models import Modelfrom keras.preprocessing.text import Tokenizerfrom keras.preprocessing.sequence import pad_sequencesfrom keras.utils.np_utils import to_categoricalfrom keras.layers import Input, Dense, Flattenfrom keras.layers import Conv1D, MaxPooling1Dimport pandas as pd
加载数据集,因为是做示例用,所以仅抽取少部分数据。
data = pd.read_excel(r'datasets/toutiaodata.xlsx').sample(frac=0.05)检视数据:
data.head()
写两个辅助函数 --- 分词和标签数字化。
def segment_words(text):stwlist = [line.strip() for line in open('datasets/stopwords.txt','r',encoding='utf-8').readlines()]results = [i.strip() for i in list(jieba.cut(text)) if i not in stwlist]return ' '.join(results)def label_index(label):if label == 'news_car':return 0if label == 'news_tech':return 1if label == 'news_edu':return 2else:return 3
进行分词和标签数值化操作:
data['segment_words'] = data['text'].apply(lambda x: segment_words(x))data['label_id'] = data['class'].apply(lambda x: label_index(x))data['text_lenghth'] = data['segment_words'].apply(lambda x: len(x))
首先是载入文本。这里的文本来自今日头条,类别有教育、科技、娱乐和汽车,文本部分仅取标题。最终得到的数据包括文本、经过预处理的文本、标签ids。
texts = data['segment_words'].tolist() # 文本存储listtexts_w2v = [i.split() for i in data['segment_words'].tolist()] # 存储用来训练word2vec的预处理文本labels = data['label_id'].tolist() # 标签ids
看看分词后的文本长啥样。
texts_w2v[:2][['大爷', '妻子', '精神病', '患者', '低保', '过日子', '妻子', '低保', '停'],
['澳洲', '留学', '澳大利亚', '转学', '转', '专业', '一篇', '彻底', '解读']]
然后,将文本样本和标签转化为张量,张量可以直接喂进神经网络。
有赖于keras中的2个实用预处理函数keras.preprocessing.text.Tokenizer和keras.preprocessing.sequence.pad_sequences,这个步骤可以轻松完成。
MAX_SEQUENCE_LENGTH = 30# 将文本样本矢量化为二维整数张量tokenizer = Tokenizer()tokenizer.fit_on_texts(texts)sequences = tokenizer.texts_to_sequences(texts)word_index = tokenizer.word_indextext_data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)x_train = text_datay_train = to_categorical(np.asarray(labels))
检视转化后的训练数据:
x_train[:2]array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 770,
18, 3407, 5772, 3408, 5773, 18, 3408, 917],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 918,
223, 2343, 5774, 5775, 89, 2344, 1379, 415]])
检视转化后的标签数据。
y_train[:10]
array([[0., 0., 0., 1.],
[0., 0., 1., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.],
[1., 0., 0., 0.],
[0., 0., 1., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.]], dtype=float32)
下一步,准备好嵌入层,以便在实际的keras模型中运行。
Keras_w2v = word2vec.Word2Vec(min_count=1,size = 50)Keras_w2v.build_vocab(texts_w2v)Keras_w2v.train(texts, total_examples=Keras_w2v.corpus_count, epochs=Keras_w2v.epochs)Keras_w2v_wv = Keras_w2v.wvembedding_layer = Keras_w2v_wv.get_keras_embedding()
看看word2vec的常规操作 --- 相近词汇检索。
Keras_w2v.wv.most_similar('开学')
[('来头', 0.48893409967422485),
('缘由', 0.48849064111709595),
('余万', 0.47019052505493164),
('中型车', 0.46262967586517334),
('星际', 0.46233227849006653),
('南校区', 0.457729697227478),
('入场', 0.4485323429107666),
('面板', 0.43472689390182495),
('关闭', 0.43151184916496277),
('北海道', 0.4294525980949402)]
import numpy as npfrom keras.callbacks import Callback,EarlyStoppingfrom keras.engine.training import Modelfrom keras.optimizers import Adamfrom sklearn.metrics import confusion_matrix, f1_score, precision_score, recall_scoreclass Metrics(Callback):def on_train_begin(self, logs={}):self.val_f1s = []self.val_recalls = []self.val_precisions = []def on_epoch_end(self, epoch, logs={}):val_predict = (np.asarray(self.model.predict(self.validation_data[0]))).round()val_targ = self.validation_data[1]_val_f1 = f1_score(val_targ, val_predict,average='weighted')_val_recall = recall_score(val_targ, val_predict,average='weighted')_val_precision = precision_score(val_targ, val_predict,average='weighted')self.val_f1s.append(_val_f1)self.val_recalls.append(_val_recall)self.val_precisions.append(_val_precision)print( ' — val_f1: %f — val_precision: %f — val_recall %f' %(_val_f1, _val_precision, _val_recall))return
提前设置一些超参数,便于追踪和把控模型的性能。
metrics = Metrics()adam = Adam(lr=1e-2, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)earlyStopping=EarlyStopping(monitor='val_acc', patience=20,verbose=1, mode='max')callbacks_list = [earlyStopping,metrics]
from __future__ import print_functionfrom keras.preprocessing import sequencefrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Embeddingfrom keras.layers import Conv1D, GlobalMaxPooling1Dfrom keras.datasets import imdbprint('构建模型...')model = Sequential()#我们从一个有效的嵌入层开始,它将训练文本中的词汇索引映射到嵌入维度中input_shape=(MAX_SEQUENCE_LENGTH,)model.add(embedding_layer)#model.add(Dropout(0.5))# 我们添加卷积1dmodel.add(Conv1D(256,5,padding='valid',activation='relu',strides=1))# 使用全局最大池化层(global max pooling)model.add(GlobalMaxPooling1D())# 增加一个隐藏层model.add(Dense(256))model.add(Dropout(0.2))model.add(Activation('relu'))#我们投射到一个单元输出层,使用适用于多分类的激活函数 - softmax:model.add(Dense(y_train.shape[1]))model.add(Activation('softmax'))model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['acc'])model.summary()
构建模型...
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_6 (Embedding) (None, None, 50) 770600
_________________________________________________________________
conv1d_2 (Conv1D) (None, None, 256) 64256
_________________________________________________________________
global_max_pooling1d_2 (Glob (None, 256) 0
_________________________________________________________________
dense_3 (Dense) (None, 256) 65792
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
activation_3 (Activation) (None, 256) 0
_________________________________________________________________
dense_4 (Dense) (None, 4) 1028
_________________________________________________________________
activation_4 (Activation) (None, 4) 0
=================================================================
Total params: 901,676
Trainable params: 131,076
Non-trainable params: 770,600
_________________________________________________________________进行实际上的训练。
print('训练模型...')history = model.fit( x_train, y_train, callbacks=callbacks_list, batch_size= 64, validation_split=0.15, epochs=500, verbose=1 )训练模型...
Train on 4680 samples, validate on 827 samples
Epoch 1/500
4680/4680 [==============================] - 2s 340us/step - loss: 1.4110 - acc: 0.3156 - val_loss: 1.3572 - val_acc: 0.3277
— val_f1: 0.042835 — val_precision: 0.187252 — val_recall 0.024184
Epoch 2/500
576/4680 [==>...........................] - ETA: 0s - loss: 1.3576 - acc: 0.3038
4680/4680 [==============================] - 1s 241us/step - loss: 1.3535 - acc: 0.3301 - val_loss: 1.3397 - val_acc: 0.3313
— val_f1: 0.062810 — val_precision: 0.301866 — val_recall 0.035067
Epoch 3/500
4680/4680 [==============================] - 1s 206us/step - loss: 1.3070 - acc: 0.3532 - val_loss: 1.3076 - val_acc: 0.3555
— val_f1: 0.157191 — val_precision: 0.361587 — val_recall 0.102781... Epoch 40/500
4680/4680 [==============================] - 1s 176us/step - loss: 0.7573 - acc: 0.6923 - val_loss: 1.5984 - val_acc: 0.4619
— val_f1: 0.425898 — val_precision: 0.526507 — val_recall 0.360339
Epoch 41/500
4680/4680 [==============================] - 1s 167us/step - loss: 0.7546 - acc: 0.6908 - val_loss: 1.6570 - val_acc: 0.4547
— val_f1: 0.399224 — val_precision: 0.503027 — val_recall 0.350665
Epoch 00041: early stopping
将训练中的loss和accuracy的变化进行可视化展示。
import matplotlib.pyplot as pltplt.switch_backend('agg')%matplotlib inlinefig1 = plt.figure()plt.plot(history.history['loss'],'r',linewidth=3.0)plt.plot(history.history['val_loss'],'b',linewidth=3.0)plt.legend(['Training loss', 'Validation Loss'],fontsize=18)plt.xlabel('Epochs ',fontsize=16)plt.ylabel('Loss',fontsize=16)plt.title('CNN Loss',fontsize=16)#fig1.savefig('loss_cnn.png')plt.show()
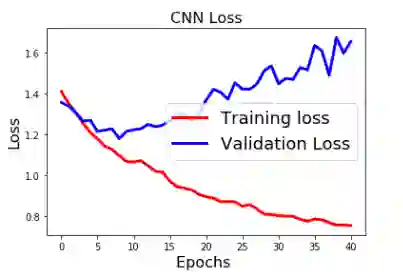
fig2=plt.figure()
plt.plot(history.history['acc'],'r',linewidth=3.0)
plt.plot(history.history['val_acc'],'b',linewidth=3.0)
plt.legend(['Training Accuracy', 'Validation Accuracy'],fontsize=18)
plt.xlabel('Epochs ',fontsize=16)
plt.ylabel('Accuracy',fontsize=16)
plt.title('CNN Accuracy',fontsize=16)
#fig2.savefig('accuracy_cnn.png')
plt.show()
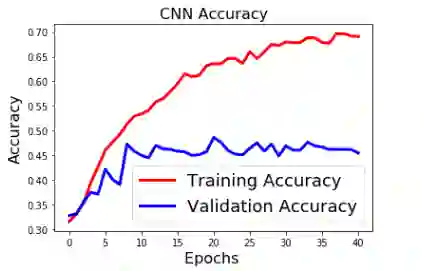
从上述结果看来。模型是大大的过拟合嘛!不过,作为示例,其实简化了很多操作,比如文本预处理、加大训练数据量等,结果还有很大的提升空间。
下面使用训练好的模型来预测位置文本的标签。
def process_text(text):""" 对文本进行分词和填充 """text = ' '.join(list(jieba.cut(text)))tokenizer = Tokenizer()tokenizer.fit_on_texts(text)x_train = tokenizer.texts_to_sequences(text)x_train = pad_sequences(x_train, maxlen=1000)return x_train
预测一下,看看模型效果怎样。
input_text = '要规范执行上级要求,防止和纠正执行简单化、形式化、机械化现象,持续推进规范化办学'
matrix = process_text(input_text)
predictions = model.predict(matrix)
# get the actual categories from output
scoredict = {}
classlabels = ['汽车','科技','教育','娱乐']
for idx, classlabel in zip(range(len(classlabels)), classlabels):
scoredict[classlabel] = predictions[0][idx]
print (scoredict)
3、与Keras进行融合 --- 词汇分类
import os
import gensim
import jieba
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dropout
from keras.regularizers import l2
from keras.models import Model
from keras.engine import Input
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
from gensim.models import keyedvectors
from collections import defaultdict
from keras.preprocessing.sequence import pad_sequences
from keras.utils.np_utils import to_categorical
from keras.layers import Input, Dense, Flatten
from keras.layers import Conv1D, MaxPooling1D
from gensim.models import word2vec
from keras.models import Model
from keras.preprocessing.text import Tokenizer
from gensim.models import word2vec
from sklearn import preprocessing
# 参数
nb_filters = 250 # 筛选器的数量
n_gram = 2 # n-gram值, 或者CNN/ConvNet的窗口大小
maxlen = 6 # 一个语句中最大词汇数量
vecsize = 100 # 模型中词向量的维度
cnn_dropout = 0.2 # CNN/ConvNet中的dropout比率
final_activation = 'softmax' # 用于多标签分类的激活函数
dense_wl2reg = 0.01 # L2正则化系数
dense_bl2reg = 0.01 # bias的L2 正则化系数
optimizer = 'adam' # 优化器
# 辅助函数
def retrieve_csvdata_as_dict(filepath):
"""
在CSV文件中检索训练数据,第一列是类标签,第二列是文本数据。
本函数它返回一个字典,其中类标签作为key,短文本列表作为每个key的value。
"""
df = pd.read_csv(filepath)
category_col, descp_col = df.columns.values.tolist()
shorttextdict = dict()
for category, descp in zip(df[category_col], df[descp_col]):
if type(descp) == str:
shorttextdict.setdefault(category, []).append(descp)
return shorttextdict
def subjectkeywords():
"""
本函数返回一个包含4个主题及其相应关键词汇的示例数据集。
"""
data_path = os.path.join(os.getcwd(), 'datasets/keras_classifier_training_data_zh.csv')
return retrieve_csvdata_as_dict(data_path)
def convert_trainingdata(classdict):
"""
将训练数据转换成输入神经网络的格式。
"""
classlabels = classdict.keys()
lblidx_dict = dict(zip(classlabels, range(len(classlabels))))
#分词并决定词长
phrases = []
indices = []
for label in classlabels:
for shorttext in classdict[label]:
shorttext = shorttext if type(shorttext) == str else ''
category_bucket = [0]*len(classlabels)
category_bucket[lblidx_dict[label]] = 1
indices.append(lblidx_dict[label])
phrases.append(shorttext)
return classlabels, phrases, indices
def process_text(text):
"""
分词并填充文本,得到语句的数值矩阵表示
"""
text = list(jieba.cut(text))
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text)
x_train = tokenizer.texts_to_sequences(text)
x_train = pad_sequences(x_train, maxlen=maxlen)
return x_train
看看文本预处理的效果,该函数将把语句转化为数值矩阵。
process_text('引入glove预训练词向量模型')
array([[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 2],
[0, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 0, 4],
[0, 0, 0, 0, 0, 5],
[0, 0, 0, 0, 0, 6],
[0, 0, 0, 0, 0, 7]])
因为是一个新的任务,所以我们得重新训练word2vec模型。这里,可选的方案有如下两种:
(1) 训练Word2Vec模型
w2v_training_data_path = os.path.join(os.getcwd(), 'datasets/Chinese_wiki_text.txt')
input_data = word2vec.LineSentence(w2v_training_data_path)
w2v_model = word2vec.Word2Vec(input_data, size=300)
w2v_model_wv = w2v_model.wv
(2)载入 pre-trained word-vectorse
w2v_model_wv2 = gensim.models.KeyedVectors.load_word2vec_format(r'D:\2018-7-5desk\wiki_word2vec.txt', binary=False)
w2v_model_wv2.wv.vector_size
# 测试下效果
w2v_model_wv2.wv.most_similar('辐射',topn = 20)
[('射线', 0.531625509262085),
('能量', 0.4896048605442047),
('物质', 0.47490665316581726),
('质量', 0.45089954137802124),
('产生', 0.44488710165023804),
('温度', 0.4419964849948883),
('效应', 0.4408746361732483),
('微波', 0.437751829624176),
('粒子', 0.4353615641593933),
('游离', 0.42930740118026733),
('探测', 0.4264931380748749),
('气体', 0.42505908012390137),
('观测', 0.42501091957092285),
('照射', 0.42473116517066956),
('紫外线', 0.4216693639755249),
('吸收', 0.42144811153411865),
('污染', 0.4155428111553192),
('中子', 0.41216930747032166),
('光子', 0.41059693694114685),
('放射性', 0.40620461106300354)]
trainclassdict = subjectkeywords()
nb_labels = len(trainclassdict) # number of class labels
print(nb_labels)
from keras.layers import Embedding
# 根据不同的词嵌入模型来源来确定对应的嵌入层
#embedding_layer = w2v_model_wv.get_keras_embedding()
embedding_layer = w2v_model_wv2.get_keras_embedding()
# 创建一个1维卷积层来解决分类问题
sequence_input = Input(shape=(maxlen,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
x = Conv1D(filters=nb_filters, kernel_size=n_gram, padding='same', activation='relu', input_shape=(maxlen, vecsize))(embedded_sequences)
x = MaxPooling1D(pool_size=maxlen - n_gram + 1)(x)
x = Dropout(0.5)(x)
x = Flatten()(x)
preds = Dense(nb_labels, activation=final_activation, kernel_regularizer=l2(dense_wl2reg), bias_regularizer=l2(dense_bl2reg))(x)
classlabels, x_train, y_train = convert_trainingdata(trainclassdict)
len(x_train)
print(classlabels)
dict_keys(['物理', '哲学', '数学'])
看看训练实例。
x_train[:5]
看看训练数据的标签。
y_train[:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
接下来是文本预处理 -- 分词和语句长度填充。
text = [' '.join(list(jieba.cut(i))) for i in x_train]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x_train)
x_train = tokenizer.texts_to_sequences(x_train)
x_train = pad_sequences(x_train, maxlen=maxlen)
x_train.shape
(147, 6)
训练集的标签应该是1列。
np.array(y_train).shape
(147,)
训练模型。
model = Model(sequence_input, preds)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
fit_ret_val = model.fit(x=x_train, y=y_train, epochs=15)
Epoch 1/15
147/147 [==============================] - 1s 4ms/step - loss: 0.8571 - acc: 0.6599
Epoch 2/15
147/147 [==============================] - 0s 195us/step - loss: 0.7677 - acc: 0.7075
Epoch 3/15
147/147 [==============================] - 0s 237us/step - loss: 0.7609 - acc: 0.7755
....
Epoch 14/15
147/147 [==============================] - 0s 217us/step - loss: 0.3268 - acc: 0.9524
Epoch 15/15
147/147 [==============================] - 0s 243us/step - loss: 0.3106 - acc: 0.9728
input_text = '享乐主义'
matrix = process_text(input_text)
predictions = model.predict(matrix)
# 从输出结果中得到实际的分类
scoredict = {}
for idx, classlabel in zip(range(len(classlabels)), classlabels):
scoredict[classlabel] = predictions[0][idx]
print (scoredict)
{'物理': 0.4717972,
'哲学': 0.519271469
, '数学': 0.008931402}
input_text = '马尔科夫链'
matrix = process_text(input_text)
predictions = model.predict(matrix)
# 从输出结果中得到实际的分类
scoredict = {}
for idx, classlabel in zip(range(len(classlabels)), classlabels):
scoredict[classlabel] = predictions[0][idx]
print (scoredict)
{'物理': 0.642403487, '哲学': 0.005444402, '数学': 0.352152111}
input_text = '核函数'
matrix = process_text(input_text)
predictions = model.predict(matrix)
# 从输出结果中得到实际的分类
scoredict = {}
for idx, classlabel in zip(range(len(classlabels)), classlabels):
scoredict[classlabel] = predictions[0][idx]
print (scoredict)
{'物理': 0.452220142
, '哲学':
0.082149784
,
'数学': 0.465630074
}
-
conv网络的滤波器数量 -
词嵌入向量的训练数据数量 -
分类器的训练数据数量
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




