想实现高可用?先搞定负载均衡原理
在互联网大行其道的今天,随着业务的迅猛增长,技术上我们常常要面对高并发,大流量。

图片来自 Pexels
为了实现高可用,高性能我们采用了很多的技术手段,负载均衡就是其中之一。作为外部流量与内部应用的“接引者”,它占据了重要的地位。
我们是否了解整个负载均衡技术?它的分类?它的原理?它的特点?今天让我们一起来漫谈负载均衡吧。
负载均衡的分类
谈到负载均衡,大家都会想到 Nginx,通常我们会用它做应用服务的负载均衡。
一般它的并发量在 5W 左右,如果并发量再高就需要做 Nginx 的集群了。但 Nginx 之上还有一层负载均衡器,是它把网络请求转发给 Nginx 的,同时还会肩负网络链路,防火墙等工作。
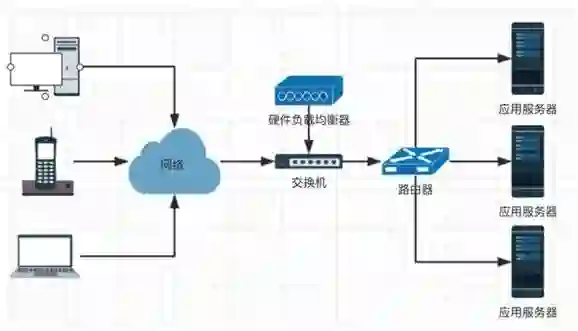
硬件负载均衡器在外网和内网之间
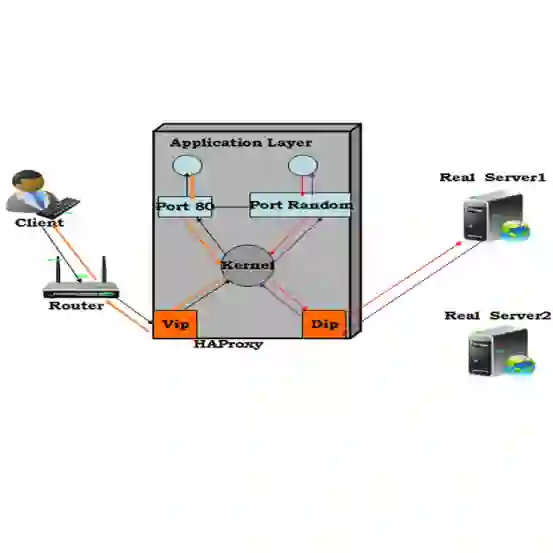
相对于“硬件负载均衡器”来说,对内网服务器进行负载均衡就属于“软件负载均衡器”。例如:LVS,HAProxy,Nginx。
硬件负载均衡工作在“接入层”,主要任务是多链路负载均衡,防火墙负载均衡,服务器负载均衡。
软件负载均衡工作在“代理层”,主要任务是反向代理,缓存,数据验证等等。
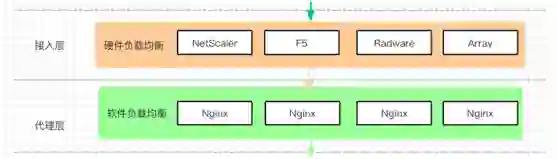
硬件负载均衡和软件负载均衡工作在不同的层
硬件负载均衡在接入层获得网络请求,然后转交给软件负载均衡,用同样的方式处理返回的请求。
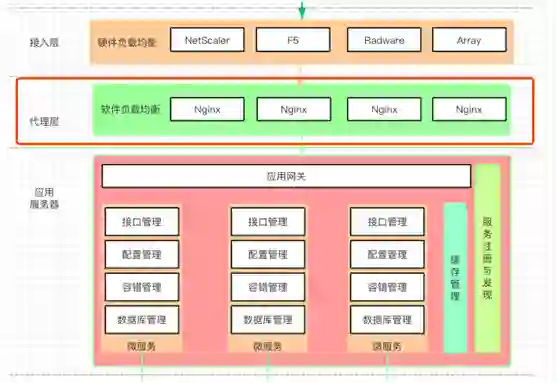
接入层,代理层,应服务器示意图
我们知道了负载均衡分为“硬件负载均衡”和“软件负载均衡”,那么来逐一看看他们是如何工作的吧。
硬件负载均衡
既然前面提到了负载均衡器的分类,那么我们就来聊聊他们的特点。硬件负载均衡技术只专注网络判断,不考虑业务系统与应用使用的情况。
看上去它对处理网络请求是非常专业的,但有趣的是,如果应用服务出现了流量瓶颈,而“接入层”的硬件负载均衡没有发现异常,还是让流量继续进入到应用服务器,并没有阻止,就会造成应用服务器流量过大。
所以,为了保证高可用,可以在“接入层”和“代理层”同时考虑限流的问题。
作为硬件负载均衡器,常在大企业使用。下面我们以 F5 公司的“F5 BIG-IP”产品为蓝本给大家介绍(下面简称 F5)。
实际上它是一个集成的解决方案,对于研发的同学来说,主要理解其原理。
硬件负载均衡器三大功能
上面谈到硬件负载均衡器的作用和特点,它具备哪三大功能?实现原理又是怎样的?
①多链路负载均衡
关键业务都需要安排和配置多条 ISP(网络服务供应商)接入链路来保证网络服务的可靠性。
如果某个 ISP 停止服务或者服务异常了,那么可以利用另一个 ISP 替代服务,提高了网络的可用性。
不同的 ISP 有不同自治域,因此需要考虑两种情况:
INBOUND
OUTBOUND
INBOUND,来自网络的请求信息。F5 分别绑定两个 ISP 服务商的公网地址,解析来自两个 ISP 服务商的 DNS 解析请求。
F5 可以根据服务器状况和响应情况对 DNS 进行发送,也可以通过多条链路分别建立 DNS 连接。
OUTBOUND,返回给请求者的应答信息。F5 可以将流量分配到不同的网络接口,并做源地址的 NAT(网络地址转换),即通过 IP 地址转换为源请求地址。
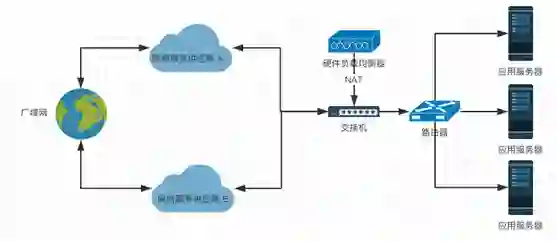
多路负载的方式增强了网络接入层的可靠性
②防火墙负载均衡
针对大量网络请求的情况,单一防火墙的能力就有限了,而且防火墙本身要求数据同进同出,为了解决多防火墙负载均衡的问题,F5 提出了防火墙负载均衡的“防火墙三明治"方案。
防火墙会对用户会话的双向数据流进行监控,从而确定数据的合法性。如果采取多台防火墙进行负载均衡,有可能会造成同一个用户会话的双向数据在多台防火墙上都进行处理。
而单个防火墙上看不到完成用户会话的信息,就会认为数据非法因此抛弃数据。
所以在每个防火墙的两端要架设四层交换机,可以在作流量分发的同时,维持用户会话的完整性,使同一用户的会话由一个防火墙来处理。而这种场景就需要 F5 负载均衡器协助才能完成转发。
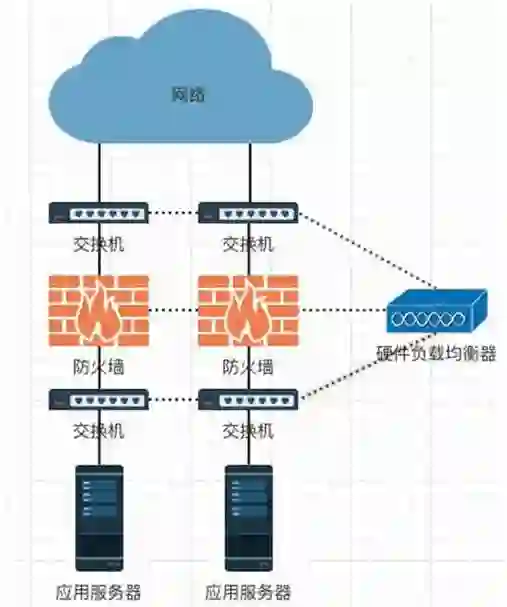
防火墙“三明治”
③服务器负载均衡
在硬件负载均衡器挂接多个应用服务器时,需要为这些服务做负载均衡,根据规则,让请求发送到服务器上去:
对于服务器的负载均衡的前提是,服务器都提供同样的服务,也就是同样的业务同时部署在多个服务器上。
对于应用服务器可以在 F5 上配置并且实现负载均衡,F5 可以检查服务器的健康状态,如果发现故障,将其从负载均衡组中移除。
F5 对于外网而言有一个真实的 IP,对于内网的每个服务器都生成一个虚拟 IP,进行负载均衡和管理工作。因此,它能够为大量的基于 TCP/IP 的网络应用提供服务器负载均衡服务。
根据服务类型不同定义不同的服务器群组。
根据不同服务端口将流量导向对应的服务器。甚至可以对 VIP 用户的请求进行特殊的处理,把这类请求导入到高性能的服务器使 VIP 客户得到最好的服务响应。
根据用户访问内容的不同将流量导向指定服务器。
优缺点总结
优点:直接连接交换机,处理网络请求能力强,与系统无关,负载性能强。可以应用于大量设施,适应大访问量、使用简单。
缺点:成本高,配置冗余。即使网络请求分发到服务器集群,负载均衡设施却是单点配置;无法有效掌握服务器及应使用状态。
软件负载均衡
功能描述和原理分析
①反向代理与负载均衡
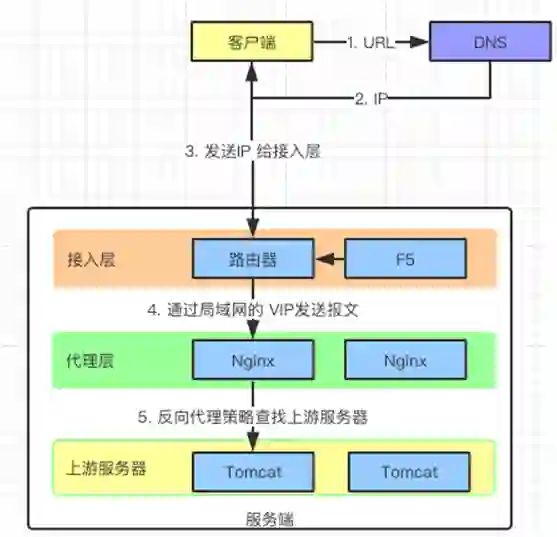
客户端请求 URL 给 DNS。
DNS 将 URL 转化成对应的 IP。
通过 IP 找到服务器。
服务器接受到请求的报文,转交给接入层处理,接入层由于采用了硬件负载均衡器,所以能够扛住大数据量。
接入层把报文再次转交给代理层(并发 5W),代理层的 Nginx 收到报文再根据反向代理的策略发送给上游服务器(应用服务器)。
负载均衡的算法/策略
Round-Robin:轮询算法,默认算法。对上游的服务器进行挨个轮询,这个算法是可以配合 Weight(权重)来实现的。
Weight:权重算法,给应用服务器设置 Weight 的值。Weight 默认值为 1,Weight 参数越大被访问的几率越大。可以根据服务器的配置和资源情况配置 Weight 值,让资源情况乐观的服务器承担更多的访问量。
IP-Hash:这个算法可以根据用户 IP 进行负载均衡,同一 IP 的用户端请求报文是会被同一台上游服务器响应的。也就是让同一客户端的回话(Session)保持一致。
Least_conn:把请求转发给连接数较少的后端服务器。轮询算法是把请求平均的转发给各个后端,使它们的负载大致相同;但是,有些请求占用的时间很长,会导致其所在的后端负载较高。这种情况下,Least_conn 这种方式就可以达到更好的负载均衡效果。
Hash Key:这个算法是对 Hash 算法的补充,主要是考虑当出现上游服务器增加/删除的情况,请求无法正确的被同一服务器处理。
所以对每个请求都设置 Hash Key,这样就算服务器发生了变化,Key 的值没有变,也可以找到对应的服务器。
②动态负载均衡
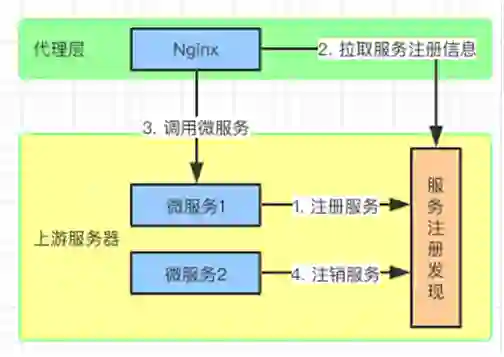
③限流
按照这个规则,需要设置限流的区域以及桶的容量,以及是否延迟。
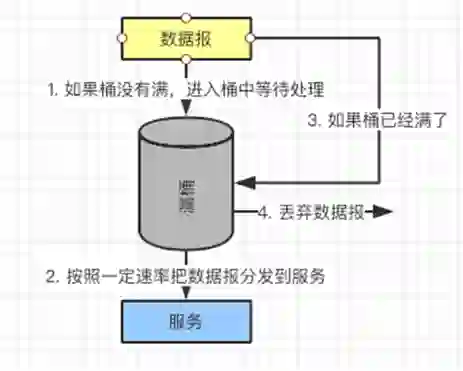
又例如:VIP 就可以直接把请求发往服务器,用不着经过令牌桶。
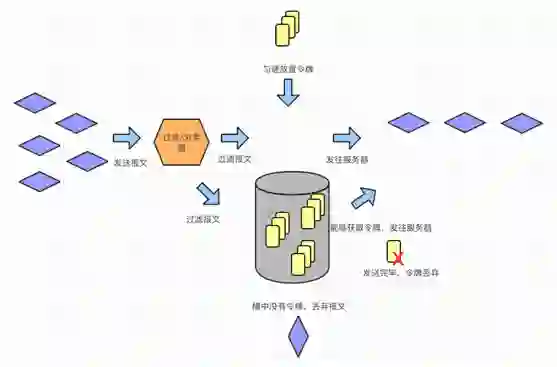
④缓存
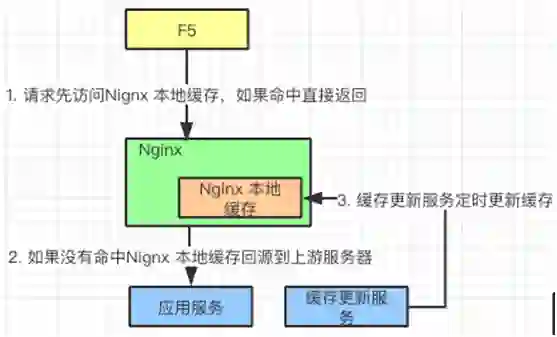
其他的几个功能如下:
客户端超时重试
DNS 超时重试
代理超时重试
失败重试
心跳检测
配置上有服务器
流行的软件负载均衡器
LVS
仅作分发之用,即把请求直接分发给应用服务器,因此没有流量的产生,对资源的消耗低。
配置简单,能够配置的项目少。
工作在第四层(传输层),支持 TCP/UDP,对应用的支持广泛。
HAProxy
支持虚拟主机。
支持 Session 保持,Cookie 引导。
通过指定的 URL 来检测应用服务器的状态。
支持 TCP/HTTP 协议转发。
Nginx
工作在网络的 4/7 层,对 HTTP 应用做负载均衡策略,如:域名、目录结构。
对网络的稳定性依赖小,可以区分内网和外网的访问。
安装和配置相对简单。
能承受很高负载且稳定,处理的流量依赖于按照 Nginx 服务器的配置。
可以检测服务器的问题,可以对服务器返回的信息进行处理和过滤,避免让无法工作的服务器响应请求。
对请求可以进行异步处理。
支持 HTTP、HTTPS 和 EMAIL。
网络负载均衡的技术选型
发展阶段
扩张阶段
成熟阶段
总结
-
硬件和软件负载均衡,分别工作在“接入层”和“代理层”。 -
一个专注于网络,负责多链路,防火墙以及服务器的负载均衡,例如:F5 BIG-IP。 -
另一个偏向于业务,主要功能是反向代理,动态代理,缓存,限流,例如:LVS,Nginx,HAProxy。
简介:十六年开发和架构经验,曾担任过惠普武汉交付中心技术专家,需求分析师,项目经理,后在创业公司担任技术/产品经理。善于学习,乐于分享。目前专注于技术架构与研发管理。
编辑:陶家龙、孙淑娟
征稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com

精彩文章推荐: