可浏览的人类大脑皮层 PB 量级重建


发布者:Google 连接组学软件工程师 Tim Blakely 和研究员 Michał Januszewski
2020 年 1 月,我们发布了果蝇“半脑”连接组:一个提供果蝇 (Drosophila melanogaster) 大约一半大脑形态结构和突触连接的在线数据库。这个数据库及其支持的可视化,重新界定了研究和理解果蝇大脑神经回路的方式。尽管果蝇的大脑小到可以通过现代映射技术获得一个相对完整的图谱,但我们从中所获得的见解充其量只是为理解人脑这一神经科学中最有趣的研究对象提供了部分信息而已。
连接组
https://elifesciences.org/articles/57443
今天,我们与哈佛大学 Lichtman 实验室合作发布了 “H01” 数据集。这是一个 1.4PB 量的人类大脑组织小样本渲染图,与之同时发布的还有一篇配套论文:“人类大脑皮层 PB 量级片段的连接组学研究 (A connectomic study of a petascale fragment of human cerebral cortex)”。
“H01” 数据集
https://h01-release.storage.googleapis.com/landing.html
人类大脑皮层 PB 量级片段的连接组学研究
https://www.biorxiv.org/content/10.1101/2021.05.29.446289v1
H01 样本通过连续切片电子显微镜,以 4 纳米分辨率成像,利用自动计算技术进行重建和标注,然后进行分析,从而获得对人类大脑皮层结构的初步了解。该数据集由大约一立方毫米大脑组织的成像数据构成,其中包括数万个重建的神经元、数百万个神经元片段、1.3 亿个标注的突触、104 个经过勘校的细胞,以及许多其他的亚细胞标注和结构,所有这些都可以通过 Neuroglancer 浏览器界面轻松访问。迄今为止,H01 是所有物种中根据这种详细程度成像和重建的最大的脑组织样本。其也是对人类大脑皮层中突触连接的第一次大规模研究。其中突触连接跨越了大脑皮层中各层的多种细胞类型。这个项目的主要目标是为研究人脑提供一种新资源,改进并扩展基础连接组学技术。
Neuroglancer 浏览器界面
https://h01-release-dot-neuroglancer-demo.appspot.com/#!gs://h01-release/assets/neuroglancer_states/20210601/c3_library.json
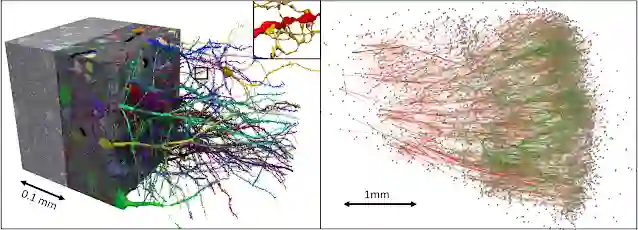
部分人脑新皮质样本的 PB 量级连接组学重建。左:数据集的小型子样本。右:数据集中 5000 个神经元以及兴奋性(绿色)连接和抑制性(红色)连接的子计算图。完整的计算图(连接组)可能会过于密集而无法可视化

大脑皮层 (Cerebral cortex) 是脊椎动物大脑的表面薄层,是最晚进化出来的部分,其面积大小在不同的哺乳动物中存在明显差异(人类的大脑皮层面积特别大)。大脑皮层的每个部分都有六层(如 L2),每层都有不同种类的神经细胞(如棘突星形细胞)。大脑皮层在大多数高级认知功能中起着至关重要的作用,例如思考、记忆、计划、感知、语言和注意力等。尽管在了解这一极其复杂的人体宏观组织方面已经取得一定进展,但在单个神经细胞层面的组织结构及其相互连接的突触方面,我们仍然知之甚少。
不同种类的神经细胞
https://h01-release.storage.googleapis.com/explore.html
棘突星形细胞
https://h01-dot-neuroglancer-demo.appspot.com/#!gs://h01-release/assets/neuroglancer_states/20210601/spiny_stellate.json
以单个突触的分辨率绘制大脑结构图谱需要高分辨率的显微镜技术,这样才能对生化特征稳定的(固定 (Fixation))组织进行成像。我们与波士顿麻省总医院 (MGH) 脑外科医生展开合作,他们在进行治疗癫痫 (Epilepsy) 的手术时,有时会切除几块正常的人类大脑皮层,以便找到大脑深处引起癫痫发作的部位。
患者以匿名方式将这些组织(切除的大脑皮层通常会被丢弃)捐赠给我们在 Lichtman 实验室的同事。哈佛大学的研究人员使用自动条带收集超微切片机将这些组织切割成约 5300 个独立的 30 纳米切片,将这些切片放置在硅片上,然后在自定义的 61-束并行扫描电子显微镜中以 4 纳米的分辨率对这些大脑组织进行成像,实现快速图像采集。
这些大约 5300 个物理切片的成像产生了 2.25 亿个独立的 2D 图像。然后,我们的团队通过计算,对这些数据进行拼接和对齐,从而生成一个单独的 3D 样本。虽然数据的质量普遍极好,但这些对齐流水线必须有效地应对一系列挑战,包括成像伪影、缺失部分、显微镜参数变化以及组织的物理拉伸和压缩。对齐之后,我们会应用多尺度泛洪填充网络流水线(使用数千个 Google Cloud TPU)生成组织中每一个细胞的 3D 分割。我们还会应用其他机器学习流水线来识别和描绘 1.3 亿个突触,将每个 3D 片段分类为不同的“子部分”(如轴突、树突或细胞体),并识别其他感兴趣的结构,如髓鞘和纤毛。
泛洪填充网络
https://ai.googleblog.com/2018/07/improving-connectomics-by-order-of.html
TPU
https://cloud.google.com/tpu
自动重建的结果并不完美,所以我们对数据中大约一百个细胞做了人工“勘校”。随着时间的推移,我们希望通过额外的手动工作和自动化的进一步发展,将更多细胞添加到这个已验证的数据集中。
一百个细胞
https://h01-dot-neuroglancer-demo.appspot.com/#!gs://h01-release/assets/neuroglancer_states/20210601/proofread_104.json
H01 样本:1.4PB 量的图像捕获了大约一立方毫米的人脑组织
这些成像数据、重建结果和标注可以通过基于网络的互动 3D 可视化界面查看,该界面名为 Neuroglancer,最初是为果蝇大脑的可视化而开发的。Neuroglancer 是一款开源软件,在更广泛的连接组学界得到广泛使用。为支持对 H01 数据集的分析,我们引入了几项新功能,尤其是针对在数据集中根据类型或其他属性来搜索特定的神经元,提供了支持。
开发
https://ai.googleblog.com/2019/08/an-interactive-automated-3d.html
开源软件
https://github.com/google/neuroglancer

样本涵盖了全部六层大脑皮层

突出显示的第 2 层中间神经元

兴奋性和抑制性传入突触

经过分类的神经元子部分
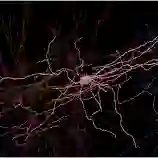
一个枝形细胞和受其抑制的数个锥体神经元

样本中跟踪到的血管

一对神经元之间的连续接触
具有复杂螺纹结构的轴突
一个具有异常自接触倾向的神经元(来源:Rachael Han)
Neuroglancer 界面中的 H01 样本和注释。用户可以根据所在层和类型选择特定的细胞,查看该细胞的传入突触和传出突触,以及更多其他部分
在配套发布的预印本中,我们展示了 H01 是如何用于研究人类大脑皮层组织的几个有趣方面。值得一提的是,我们发现了新的细胞类型和“离群”轴突输入的存在,后者与目标树突建立了强大的突触连接。这些发现是良好的开端,而对有兴趣探索人类大脑皮层的研究人员而言,H01 数据集的海量信息将为未来多年的更深入研究提供基础。
配套发布的预印本
https://www.biorxiv.org/content/10.1101/2021.05.29.446289v1
为加速对 H01 的分析,我们还提供了 H01 数据的嵌入向量 (Embeddings),这些嵌入是根据一个使用 SimCLR 自监督学习技术变体进行训练的神经网络生成的。这些嵌入向量提供了数据集局部的高度信息性表征,可用于快速标注新结构,并根据纯数据驱动标准,开发对大脑结构进行聚类和分类的新方法。我们使用 Google Cloud TPU Pod 训练这些嵌入,然后在分布于整个样本中、大约 40 亿个数据的位置执行推理。
SimCLR
https://mp.weixin.qq.com/s/KopkQY3RVvLhV_ooRcDD1w
这些嵌入向量
https://h01-release.storage.googleapis.com/embeddings.html
TPU Pod
https://cloud.google.com/tpu/docs/training-on-tpu-pods
H01 是一个 PB 量级的数据集,但其大小只是整个人脑容量的百万分之一。将突触级别的大脑映射扩展到整个小鼠大脑(比 H01 大 500 倍)仍然是严峻的技术挑战,更不用说整个人脑了。挑战之一就是数据存储:一个小鼠大脑可能产生艾字节级的数据量,存储成本很高。为解决这个问题,我们今天还发布了一篇论文,“用于连接组学的基于去噪的图像压缩 (Denoising-based Image Compression for Connectomics)”,详细介绍了如何使用基于机器学习的去噪策略来压缩数据,例如 H01 至少压缩 17 次(下图中的虚线),而自动重建的精度损失可以忽略不计。
用于连接组学的基于去噪的图像压缩
https://www.biorxiv.org/content/10.1101/2021.05.29.446289v1
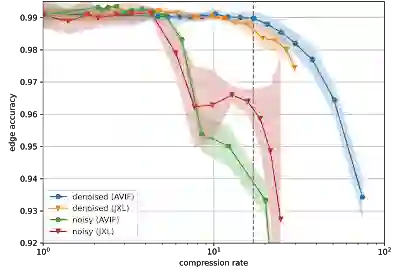
以 JPEG XL (JXL) 和 AV 图片格式 (AVIF) 编解码器的压缩率为函数,表示有噪和去噪图像的重建质量。点和线表示均值,阴影区域代表均值周围 ±1 个标准差的范围
电子显微镜成像过程中的随机变化会导致图像噪声。这些噪声在理论上很难压缩,因为它缺乏空间相关性或其他可以用于较少字节描述的结构。于是我们分别在“快”采集模式(导致大量噪声)和“慢”采集模式(导致少量噪声)下获取同一块组织的图像,然后训练神经网络从“快”扫描推断“慢”扫描。标准图像压缩编解码器能够(有损地)压缩“虚拟的”慢扫描图像,与原始数据相比,这些图像的伪影更少。我们相信这一进展可能会极大地缓解与未来大规模连接组学项目相关的成本压力。
存储并不是唯一的问题。鉴于未来数据集的庞大规模,必须为研究人员开发新的策略来整理和访问连接组数据中固有的丰富信息。这些挑战要求我们在人类与未来的大脑映射数据之间建立新的互动模式。

点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看



