深度学习中的知识蒸馏技术(上)
点击上方,选择星标或置顶,每天给你送干货!
来自:Microstrong
本文概览:
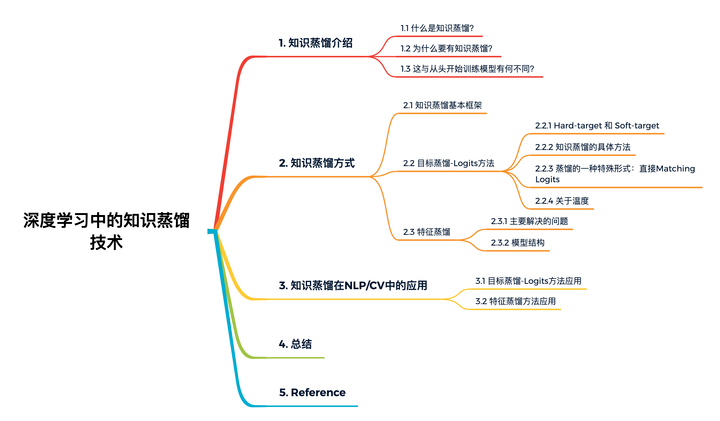
1. 知识蒸馏介绍
1.1 什么是知识蒸馏?
在化学中,蒸馏是一种有效的分离不同沸点组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。化学蒸馏条件:(1)蒸馏的液体是混合物;(2)各组分沸点不同。
蒸馏的液体是混合物,这个混合物一定是包含了各种组分,即在我们今天讲的知识蒸馏中指原模型包含大量的知识。各组分沸点不同,蒸馏时要根据目标物质的沸点设置蒸馏温度,即在我们今天讲的知识蒸馏中也有“温度”的概念,那这个“温度“代表了什么,又是如何选取合适的”温度“?这里先埋下伏笔,在文中给大家揭晓答案。
进入我们今天正式的主题,到底什么是知识蒸馏?一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。
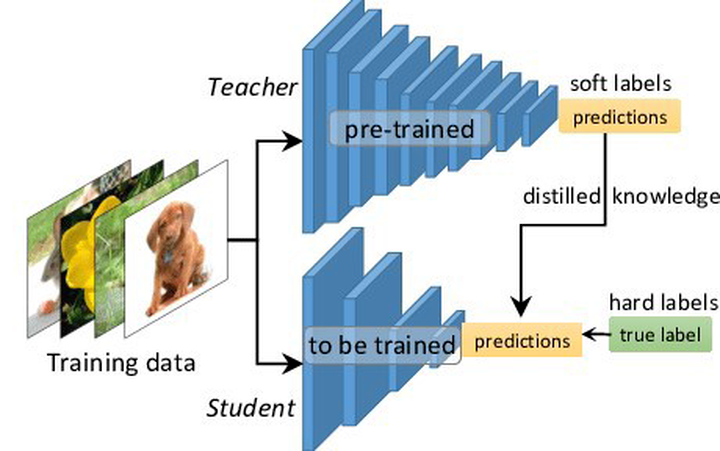
Hinton等人最早在文章《Distilling the Knowledge in a Neural Network》中提出了知识蒸馏这个概念,其核心思想是先训练一个复杂网络模型,然后使用这个复杂网络的输出和数据的真实标签去训练一个更小的网络,因此知识蒸馏框架通常包含了一个复杂模型(被称为Teacher模型)和一个小模型(被称为Student模型)。
1.2 为什么要有知识蒸馏?
深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,大多数模型在计算上过于昂贵,无法在移动端或嵌入式设备上运行。因此需要对模型进行压缩,且知识蒸馏是模型压缩中重要的技术之一。
1. 提升模型精度
如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的A模型。
2. 降低模型时延,压缩网络参数
如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A,从而达到降低时延的目的。
3. 标签之间的域迁移
假如使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B,那么就可以用这两个模型同时蒸馏出一个可以识别狗、猫、香蕉以及苹果的模型,将两个不同域的数据集进行集成和迁移。
因此,在工业界中对知识蒸馏和迁移学习也有着非常强烈的需求。
补充模型压缩的知识
模型压缩大体上可以分为 5 种:
-
模型剪枝:即移除对结果作用较小的组件,如减少 head 的数量和去除作用较少的层,共享参数等,ALBERT属于这种; -
量化:比如将 float32 降到 float8; -
知识蒸馏:将 teacher 的能力蒸馏到 student上,一般 student 会比 teacher 小。我们可以把一个大而深的网络蒸馏到一个小的网络,也可以把集成的网络蒸馏到一个小的网络上。 -
参数共享:通过共享参数,达到减少网络参数的目的,如 ALBERT 共享了 Transformer 层; -
参数矩阵近似:通过矩阵的低秩分解或其他方法达到降低矩阵参数的目的;
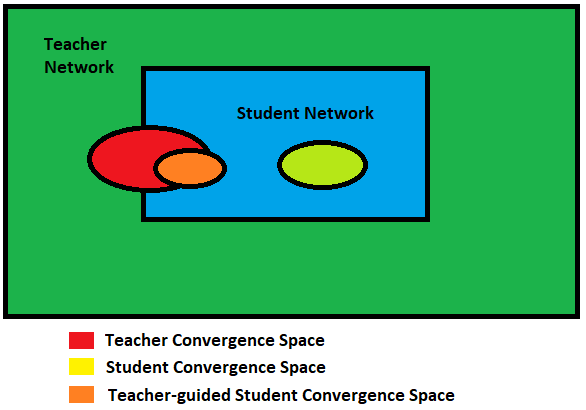
1.3 这与从头开始训练模型有何不同?
显然,对于更复杂的模型,理论搜索空间要大于较小网络的搜索空间。但是,如果我们假设使用较小的网络可以实现相同(甚至相似)的收敛,则教师网络的收敛空间应与学生网络的解空间重叠。
不幸的是,仅此一项并不能保证学生网络在同一位置收敛。学生网络的收敛可能与教师网络的收敛大不相同。但是,如果指导学生网络复制教师网络的行为(教师网络已经在更大的解空间中进行了搜索),则可以预期其收敛空间与原始教师网络收敛空间重叠。
2. 知识蒸馏方式
2.1 知识蒸馏基本框架
知识蒸馏采取Teacher-Student模式:将复杂且大的模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。
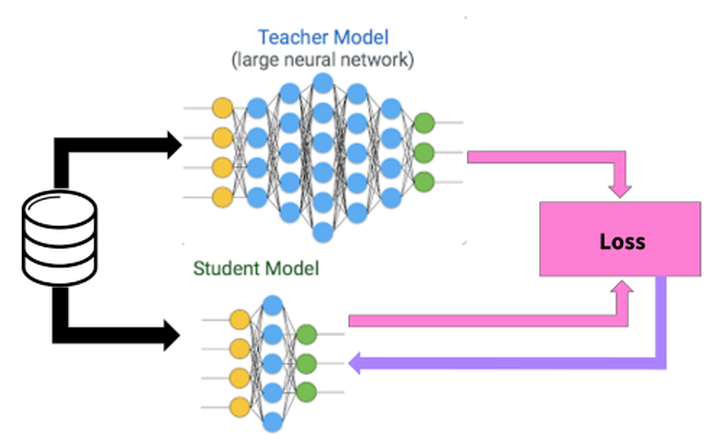
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向,下面我们对其进行介绍。
2.2 目标蒸馏-Logits方法
目标蒸馏方法中最经典的论文就是来自于2015年Hinton发表的一篇神作《Distilling the Knowledge in a Neural Network》。下面我们以这篇神作为例,给大家讲讲目标蒸馏方法的原理。
在这篇论文中,Hinton将问题限定在分类问题下,分类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。在知识蒸馏时,由于我们已经有了一个泛化能力较强的Teacher模型,我们在利用Teacher模型来蒸馏训练Student模型时,可以直接让Student模型去学习Teacher模型的泛化能力。一个很直白且高效的迁移泛化能力的方法就是:使用softmax层输出的类别的概率来作为“Soft-target” 。
2.2.1 Hard-target 和 Soft-target
传统的神经网络训练方法是定义一个损失函数,目标是使预测值尽可能接近于真实值(Hard- target),损失函数就是使神经网络的损失值和尽可能小。这种训练过程是对ground truth求极大似然。在知识蒸馏中,是使用大模型的类别概率作为Soft-target的训练过程。
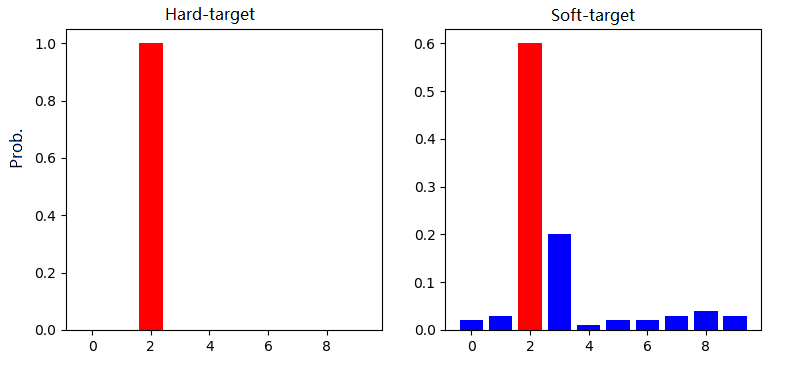
图:来源于参考文献2
-
Hard-target:原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。 -
Soft-target:Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高。
知识蒸馏用Teacher模型预测的 Soft-target 来辅助 Hard-target 训练 Student模型的方式为什么有效呢?softmax层的输出,除了正例之外,负标签也带有Teacher模型归纳推理的大量信息,比如某些负标签对应的概率远远大于其他负标签,则代表 Teacher模型在推理时认为该样本与该负标签有一定的相似性。而在传统的训练过程(Hard-target)中,所有负标签都被统一对待。也就是说,知识蒸馏的训练方式使得每个样本给Student模型带来的信息量大于传统的训练方式。
如在MNIST数据集中做手写体数字识别任务,假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率会比其他负标签类别高;而另一个"2"更加形似"7",则这个样本分配给"7"对应的概率会比其他负标签类别高。这两个"2"对应的Hard-target的值是相同的,但是它们的Soft-target却是不同的,由此我们可见Soft-target蕴含着比Hard-target更多的信息。
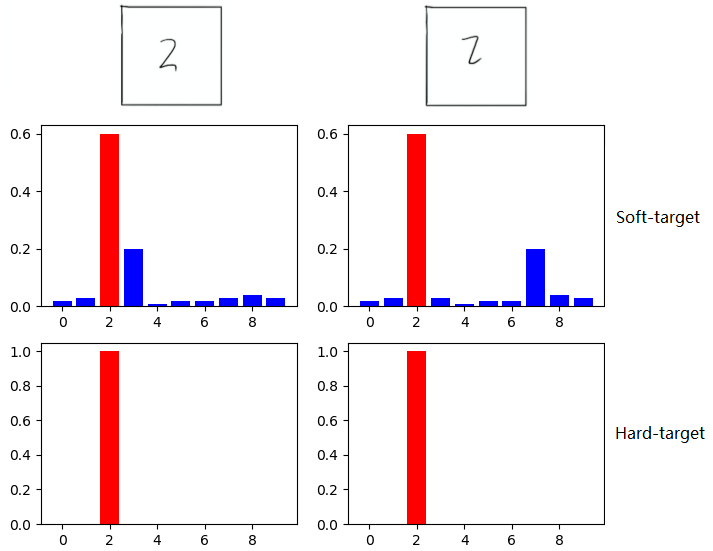
图:来源于参考文献2
在使用 Soft-target 训练时,Student模型可以很快学习到 Teacher模型的推理过程;而传统的 Hard-target 的训练方式,所有的负标签都会被平等对待。因此,Soft-target 给 Student模型带来的信息量要大于 Hard-target,并且Soft-target分布的熵相对高时,其Soft-target蕴含的知识就更丰富。同时,使用 Soft-target 训练时,梯度的方差会更小,训练时可以使用更大的学习率,所需要的样本也更少。这也解释了为什么通过蒸馏的方法训练出的Student模型相比使用完全相同的模型结构和训练数据只使用Hard-target的训练方法得到的模型,拥有更好的泛化能力。
2.2.2 知识蒸馏的具体方法
在介绍知识蒸馏方法之前,首先得明白什么是Logits。我们知道,对于一般的分类问题,比如图片分类,输入一张图片后,经过DNN网络各种非线性变换,在网络最后Softmax层之前,会得到这张图片属于各个类别的大小数值 ,某个类别的 数值越大,则模型认为输入图片属于这个类别的可能性就越大。什么是Logits? 这些汇总了网络内部各种信息后,得出的属于各个类别的汇总分值 ,就是Logits,i代表第i个类别, 代表属于第i类的可能性。因为Logits并非概率值,所以一般在Logits数值上会用Softmax函数进行变换,得出的概率值作为最终分类结果概率。Softmax一方面把Logits数值在各类别之间进行概率归一,使得各个类别归属数值满足概率分布;另外一方面,它会放大Logits数值之间的差异,使得Logits得分两极分化,Logits得分高的得到的概率值更偏大一些,而较低的Logits数值,得到的概率值则更小。
神经网络使用 softmax 层来实现 logits 向 probabilities 的转换。原始的softmax函数:
但是直接使用softmax层的输出值作为soft target,这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。下面的公式是加了温度这个变量之后的softmax函数:
其中 是每个类别输出的概率, 是每个类别输出的 logits, 就是温度。当温度 时,这就是标准的 Softmax 公式。 越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
知识蒸馏训练的具体方法如下图所示,主要包括以下几个步骤:
-
训练好Teacher模型; -
利用高温 产生 Soft-target; -
使用 和 同时训练 Student模型; -
设置温度 ,Student模型线上做inference。
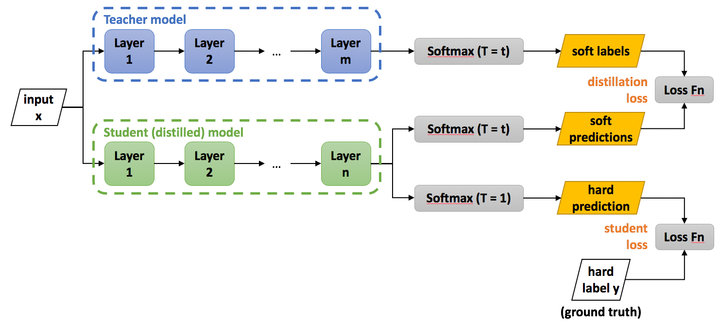
训练Teacher的过程很简单,我们把第2步和第3步过程统一称为:高温蒸馏的过程。高温蒸馏过程的目标函数由distill loss(对应Soft-target)和Student loss(对应Hard-target)加权得到。如下所示:
(1) Teacher模型和Student模型同时输入 transfer set (这里可以直接复用训练Teacher模型用到的training set),用Teacher模型在高温 下产生的softmax distribution来作为Soft-target,Student模型在相同温度 条件下的softmax输出和Soft-target的cross entropy就是Loss函数的第一部分 ,具体形式如下所示:
其中, 指Teacher模型在温度等于T的条件下softmax输出在第 类上的值。 指Student的在温度等于 的条件下softmax输出在第 类上的值。公式如下:
其中, 指Teacher模型的logits, 指Student模型的logits, 指总标签数量。
(2) Student模型在T=1的条件下的softmax输出和ground truth的cross entropy就是Loss函数的第二部分 。
其中, 指在第 类上的ground truth值, , 正标签取1,负标签取0。 形式如下:
第二部分Loss 的必要性其实很好理解:Teacher模型也有一定的错误率,使用ground truth可以有效降低错误被传播给Student模型的可能性。打个比喻,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
最后, 和 是关于 和 的权重,实验发现,当 权重较小时,能产生最好的效果,这是一个经验性的结论。文章《【经典简读】知识蒸馏(Knowledge Distillation) 经典之作》,地址:https://zhuanlan.zhihu.com/p/102038521 和 文章《【Knowledge Distillation】知识蒸馏学习》,地址:https://baihaoran.xyz/2020/05/04/Knowledge-Distillation.html 都进行了理论的推导,这里我直接给出结论:由于 贡献的梯度大约为 的 ,因此在同时使用Soft-target和Hard-target的时候,需要在 的权重上乘以 的系数,这样才能保证Soft-target和Hard-target贡献的梯度量基本一致。
2.2.3 蒸馏的一种特殊形式:直接Matching Logits
直接Matching Logits指的是,直接使用softmax层的输入logits(而不再是输出)作为Soft- target,需要最小化的目标函数是Teacher模型和Student模型的logits之间的平方差, ,对 求梯度可得:
再看一般蒸馏中 对 求梯度可得:
当 时,有 和 ,根据泰勒公式的一阶展开,当 时有 ,则有:
此时,假设 Logits 在每个样本上是零均值的,则进一步近似:
可见,经过Softmax的蒸馏方式和直接Matching Logits的方式,当温度 时Soft-target损失函数部分是等价的,即Matching Logits是一般知识蒸馏方法的一种特殊形式。
2.2.4 关于温度
这里消除关于温度的伏笔。在知识蒸馏中,需要使用高温将知识“蒸馏”出来,但是如何调节温度 呢,温度的变化会产生怎样的影响呢?
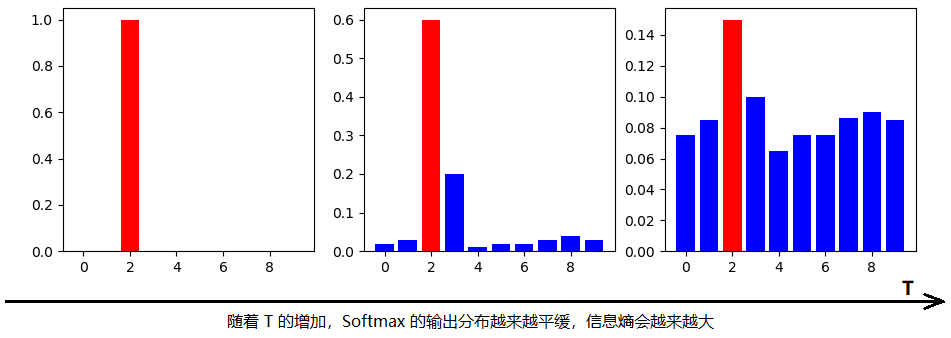
图:来源于参考文献2
温度 有这样几个特点:
-
原始的softmax函数是 时的特例; 时,概率分布比原始更“陡峭”,也就是说,当 时,Softmax 的输出值会接近于 Hard-target; 时,概率分布比原始更“平缓”。 -
随着 的增加,Softmax 的输出分布越来越平缓,信息熵会越来越大。温度越高,softmax上各个值的分布就越平均,思考极端情况,当 ,此时softmax的值是平均分布的。 -
不管温度 怎么取值,Soft-target都有忽略相对较小的 (Teacher模型在温度为T时softmax输出在第 类上的值)携带的信息的倾向。
温度的高低改变的是Student模型训练过程中对负标签的关注程度。当温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Student模型会相对更多地关注到负标签。
实际上,负标签中包含一定的信息,尤其是那些负标签概率值显著高于平均值的负标签。但由于Teacher模型的训练过程决定了负标签部分概率值都比较小,并且负标签的值越低,其信息就越不可靠。因此温度的选取需要进行实际实验的比较,本质上就是在下面两种情况之中取舍:
-
当想从负标签中学到一些信息量的时候,温度 应调高一些; -
当想减少负标签的干扰的时候,温度 应调低一些;
总的来说, 的选择和Student模型的大小有关,Student模型参数量比较小的时候,相对比较低的温度就可以了。因为参数量小的模型不能学到所有Teacher模型的知识,所以可以适当忽略掉一些负标签的信息。
最后,在整个知识蒸馏过程中,我们先让温度 升高,然后在测试阶段恢复“低温“( ),从而将原模型中的知识提取出来,因此将其称为是蒸馏,实在是妙啊。
2.3 特征蒸馏
另外一种知识蒸馏思路是特征蒸馏方法,如下图所示。它不像Logits方法那样,Student只学习Teacher的Logits这种结果知识,而是学习Teacher网络结构中的中间层特征。最早采用这种模式的工作来自于论文《FITNETS:Hints for Thin Deep Nets》,它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。这种情况下,Teacher中间特征层的响应,就是传递给Student的知识。在此之后,出了各种新方法,但是大致思路还是这个思路,本质是Teacher将特征级知识迁移给Student。因此,接下来我们以这篇论文为主,详细介绍特征蒸馏方法的原理。
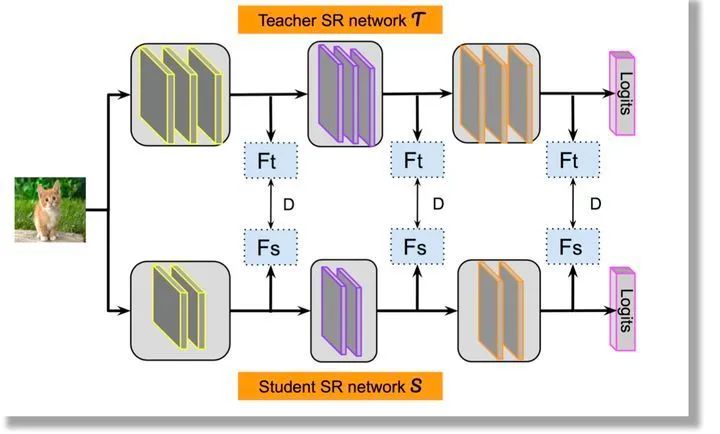
2.3.1 主要解决的问题
这篇论文首先提出一个案例,既宽又深的模型通常需要大量的乘法运算,从而导致对内存和计算的高需求。因此,即使网络在准确性方面是性能最高的模型,其在现实世界中的应用也受到限制。
为了解决这类问题,我们需要通过模型压缩(也称为知识蒸馏)将知识从复杂的模型转移到参数较少的简单模型。
到目前为止,知识蒸馏技术已经考虑了Student网络与Teacher网络有相同或更小的参数。这里有一个洞察点是,深度是特征学习的基本层面,到目前为止尚未考虑到Student网络的深度。一个具有比Teacher网络更多的层但每层具有较少神经元数量的Student网络称为“thin deep network”。
因此,该篇论文主要针对Hinton提出的知识蒸馏法进行扩展,允许Student网络可以比Teacher网络更深更窄,使用teacher网络的输出和中间层的特征作为提示,改进训练过程和student网络的性能。
2.3.2 模型结构
-
Student网络不仅仅拟合Teacher网络的Soft-target,而且拟合隐藏层的输出(Teacher网络抽取的特征); -
第一阶段让Student网络去学习Teacher网络的隐藏层输出(特征蒸馏); -
第二阶段使用Soft-target来训练Student网络(目标蒸馏)。
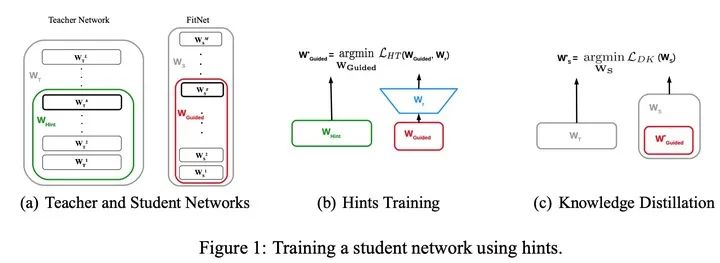
把“宽”且“深”的网络蒸馏成“瘦”且“更深”的网络,需要进行两阶段的训练:
第一阶段:首先选择待蒸馏的中间层(即Teacher的Hint layer和Student的Guided layer),如图中绿框和红框所示。由于两者的输出尺寸可能不同,因此,在Guided layer后另外接一层卷积层,使得输出尺寸与Teacher的Hint layer匹配。接着通过知识蒸馏的方式训练Student网络的Guided layer,使得Student网络的中间层学习到Teacher的Hint layer的输出.
就是根据Teacher模型的损失来指导预训练Student模型。记Teacher网络的前 层作为 ,意为指导的意思。Student网络的前 层作为 ,即被指导的意思,在训练之初Student网络进行随机初始化。需要学习一个映射函数 使得 的维度匹配 ,得到Student模型在下一阶段的参数初始化值,并最小化两者网络输出的MSE差异作为损失(特征蒸馏),如下:
其中, 是教师网络的部分层的参数(绿框); 是学生网络的部分层的参数(红框); 是一个全连接层,用于将两个网络输出的size配齐,因为学生网络隐藏层宽度比教师网络窄。
第二阶段: 在训练好Guided layer之后,将当前的参数作为网络的初始参数,利用知识蒸馏的方式训练Student网络的所有层参数,使Student学习Teacher的输出。由于Teacher对于简单任务的预测非常准确,在分类任务中近乎one-hot输出,因此为了弱化预测输出,使所含信息更加丰富,作者使用Hinton等人论文《Distilling knowledge in a neural network》中提出的softmax改造方法,即在softmax前引入 缩放因子,将Teacher和Student的pre-softmax输出均除以 。也就是上面我们讲的加了温度的softmax。此时的损失函数为:
其中, 指交叉熵损失函数; 是一个可调整参数,以平衡两个交叉熵;第一部分为Student的输出与Ground-truth的交叉熵损失;第二部分为Student与Teacher的softmax输出的交叉熵损失。
3. 知识蒸馏在NLP/CV中的应用
下面给出这两种蒸馏方式在自然语言处理和计算机视觉方面的一些顶会论文,方便大家扩展阅读。
3.1 目标蒸馏-Logits方法应用
-
《Distilling the Knowledge in a Neural Network 》,NIPS,2014。 -
《Deep Mutual Learning》,CVPR,2018。 -
《Born Again Neural Networks》,CVPR,2018。 -
《Distilling Task-Specific Knowledge from BERT into Simple Neural Networks》,2019。
3.2 特征蒸馏方法应用
-
《FitNets: Hints for Thin Deep Nets》,ICLR,2015。 -
《Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer》, ICLR,2017。 -
《A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning》,CVPR,2017。 -
《Learning Efficient Object Detection Models》,NIPS,2017。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

