学界 | 生成的图像数据集效果不好?也许你需要考虑内容分布的差异

AI 科技评论按:大家都知道深度学习模型的表现会随着训练数据增加而提高,所以为了不断提高模型表现,模型本身的设计和训练数据扩增方面的研究也都非常多。对于图像相关的任务,传统上我们有基于变换的数据扩增方法,有谷歌式的暴力收集、有 Facebook 利用用户上传图像的标签,也有苹果的生成并微调。生成数据的方法当然是最理想的,毕竟许多任务中所有有关的图像加起来也没有多少,而且生成数据的同时也直接获得了真是标签。但生成数据的方法也有严重的问题,那就是生成数据集和真实数据集的数据分布之间会有差异,这些差异限制了生成数据方法的效果。

对生成数据集和真实数据集差异的探究目前也有不少成果,比如学习不同任务通用的图像特征、学习图像风格迁移等,这样可以让生成数据集中的图像看上去更像真实图像。不过这篇论文的作者们认为,图像风格的差异其实只是很小的因素,更重要的差异在于图像内容的差异,而且生成的图像应当对新的任务有帮助。以往的图像生成方法只能覆盖有限的场景、有限的物体、有限的变化,对真实世界物体的多变性和属性的分布刻画不足;而且作者们提出,以KITTI数据集为例,它的数据是在德国采集的,但也许别的研究人员使用这个数据集训练的系统是想要在日本使用的,场景内容一定会有所不同;甚至服务的任务目标也可以不同。这都是现有的数据生成方法没有解决,甚至没有考虑的方面。如果完全在虚拟环境中复制重现的话,资金和时间成本也都非常高昂。
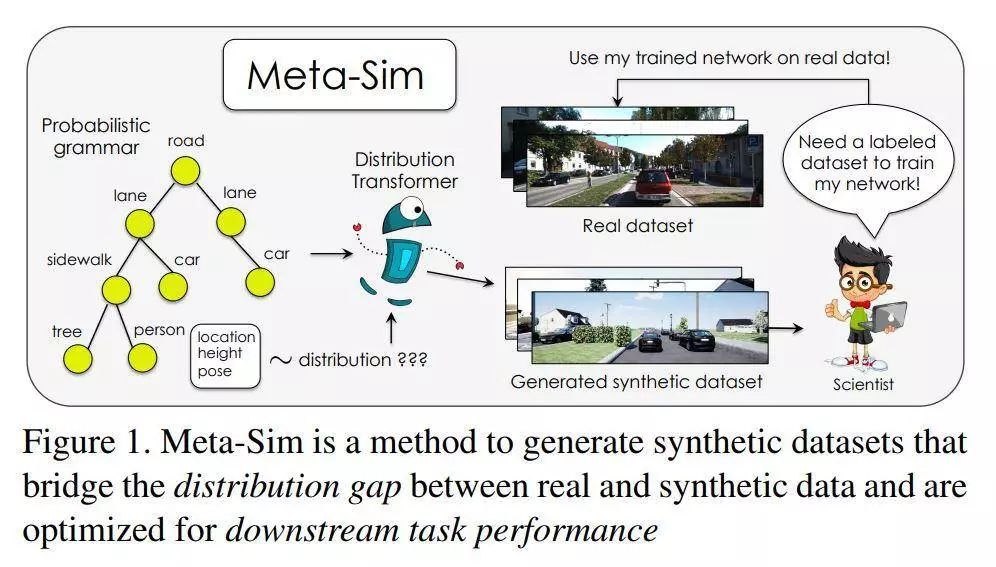
所以在论文《Meta-Sim: Learning to Generate Synthetic Datasets》中,作者们旗帜鲜明地提出,他们的研究目标是自动生成大规模标注数据集,而且这个数据集是对下游任务有帮助的(数据集中的内容分布能够符合目标使用场景)。作者们提出的方法是 Meta-Sim,它会学习到关于新合成的场景的生成式模型,而且可以通过一个图形引擎同步获得训练用的图形和对应的真实标签值。作者们接着用神经网络对数据集生成器进行参数化,使得它能够学会修改从场景内容分布概率中获得的场景结构图的属性,以便减小图像引擎输出的图像和目标数据集分布之间的差异。如果要模仿的真实数据集带有一个小的有标注验证集的话,作者们的方法还可以额外针对一个元目标进行优化,也就是说可以针对当前数据集任务的下游任务进行优化。实验表明,与人工设计的场景内容分布概率相比,他们提出的方法可以极大提高内容生成质量,可以在下游任务上定性以及定量地得到验证。更多具体细节可以参见论文原文。
这篇论文的作者们来自英伟达、多伦多大学、Vector 人工智能学院以及MIT。
项目主页参见: https: //nv-tlabs.github.io/meta-sim/
论文地址:https://arxiv.org/abs/1904.11621
备受大家期待的强化学习课程终于上线啦!
扫描下方邀请卡,解锁更多课时

![]()
点击
阅读原文
,查看更多内容



