如何评测AI系统?
最近,随着MLPerf走进大家的视野,AI系统(这里指完成AI任务的软硬件系统)的Benchmark这个话题备受关注。从目前的进展来看,对于机器学习训练(Training)系统,MLPerf可以说基本解决了对比评测的问题;而对于推断(Inference)系统来说,设计Benchmark非常困难,很多问题目前还看不到答案。
之前我写过几篇关于AI系统如何做Benchmark的文章(给DNN处理器跑个分 - 设计篇,给DNN处理器跑个分 - 指标篇,给DNN处理器跑个分 - BenchIP),其重要性和基本概念就不在这里赘述。下面,我们通过MLPerf的设计和讨论看看如何评估Training和Inference系统的问题。
•••

自从MLPerf推出以来,相关的讨论非常活跃。用圈内一位大佬的话说,“一个小小的工作组会议,来了硅谷ai芯片的一半大佬,还有图灵奖得主坐镇...”。可见其受重视的程度。
MLPerf的概述是这样的:“The MLPerf effort aims to build a common set of benchmarks that enables the machine learning (ML) field to measure system performance for both training and inference from mobile devices to cloud services. We believe that a widely accepted benchmark suite will benefit the entire community, including researchers, developers, builders of machine learning frameworks, cloud service providers, hardware manufacturers, application providers, and end users.”
而MLPerf的目标(如下图)基本上和传统的Benchmark类似。

source:MLPerf.org
MLPerf的想法应该有两个来源,一个是哈佛大学的Fathom项目(Fathom: Reference Workloads for Modern Deep Learning Methods);另一个是斯坦福的DAWNBench(An End-to-End Deep Learning Benchmark and Competition)。MLPerf借鉴了前者在评价中使用的多种不同的机器学习任务,以保证Benchmark具有足够的代表性;同时借鉴了后者使用的对比评价指标,保证公平性。如下面两个图所示。


source:MLPerf.org
从评价指标(Metrics)来看,第一点基本是针对训练任务的,即训练一个模型达到一定精度所需的时间。第二点是给出一个综合评分(score),不过这个具体怎么执行好像还没有定论。第三个实际是一个成本的指标,这里也强调了对于Mobile主要给出功耗,而对于Cloud则直接给出使用的成本,应该是和DAWNBench类似。比如下图这样的结果,
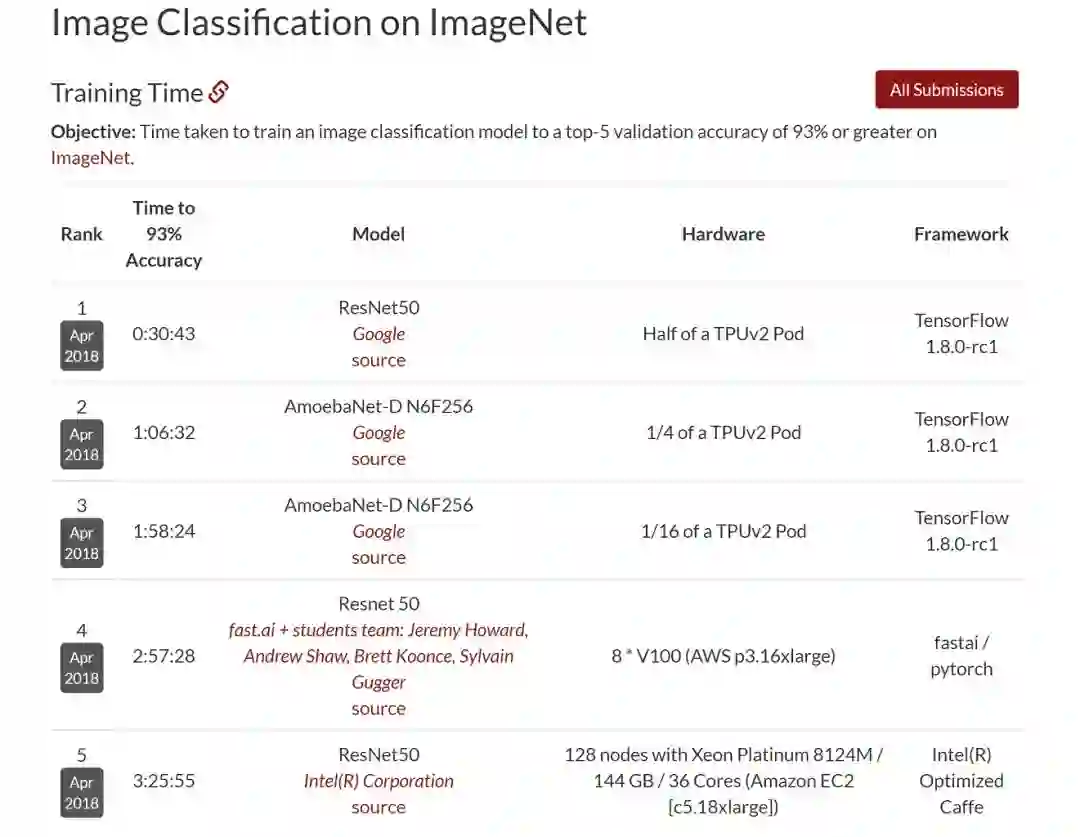
source: http://dawn.cs.stanford.edu/
另外,MLPerf还提出了一个Closed and Open Model Divisions的概念。Closed Model Division使用确定的模型和参数,以保证测试的公平性。而Open Model Division则会放宽一些限制,让大家可以有一定的发挥空间,鼓励软硬件的创新。

source:MLPerf.org
到此为止,我们可以认为,如果目前的机器学习方法不发生大的变化,对于训练系统的评估,MLPerf已经提供了一个相对完备和公平的方法。虽然目前MLPerf还不能称为一个大家公认的标准,从目前参与的玩家来看,还有很多巨头在“观望”,或者由于各种原因他们未来也不会支持这个Benchmark。但从技术上来说,我认为“如何评估机器学习训练系统”这个问题已经基本解决了(当然还有很多细节需要完善,未来也需要根据算法和模型的变化不断更新)。即使未来大家不会统一使用MLPerf,对于Training系统的基本的Benchmark思路也应该是差不多的。同时,在Training应用中,Intel的CPU,Nvidia的GPU和Google的TPU还可以作为很好的对比基线。
做训练系统软硬件的公司,现在有了一个比较公平的竞技场,好东西可以更容易证明自己,只要跑跑MLPerf的Benchmark,看看完成这些训练要多少时间,多大成本就行了。当然,PR公司和2VC公司能混的日子也不多了。

•••
不过,如果我们把视野转到Inference系统的评估,则情况要复杂很多。虽然MLPerf并没有把自己限制在Training任务上,也希望能够覆盖Inference系统的评估,但目前显然还没有找到很好的方法。因此,MLPerf工作组的主要成员,Google的Cliff Young,在MLPerf的论坛中专门提出了“Inference Benchmark”这个讨论的题目。在邮件开始他指出,最初他们也试图把Inference包括在Benchmark当中,但逐渐发现它和Training在很多方面都有所不同,很难在短期拿出一个比较理想的方案。关于具体的困难和值得讨论的问题,他也做了详细的说明。这部分非常值得思考,这里我引用一下:
What's the metric? Is there an equivalent to "time to target accuracy" in the inference space, such as "inferences per second at or above the threshold accuracy"? Do we measure both latency and throughput? What about power?
第一个是“使用什么指标的问题”。Training系统的性能可以使用“达到特定精度的时间”这个简单的标准来衡量。但Inference系统却很难找到一个简单的指标,这一点我在之前的文章中也有过讨论。Latency,Throughput,Power,Cost,等等,哪个指标合适?再放到不同的应用场景情况就更为复杂。
Does an inference set get distributed with already-trained weights? If not, how do you ensure comparability across measurements?
第二个问题关于模型使用什么参数,参数如果不同如何进行对比?
What does one do about quantized arithmetic, or other related implementation techniques?
第三个是实现优化带来的问题。比如,如果两个系统的量化比特不同,怎么对比?
What do we do about hardware variation? We're in an era where the underlying hardware might be vastly different. Do we allow retraining to help target the device? If a device can't support a feature (e.g., some activation function), what accommodations are allowed?
第四个是硬件差异性的问题。Inference系统的硬件往往有比较大的差异,Benchmark在设计的时候如何应对?
How many different inference markets or sub-benchmarks are there? For the moment, training seems to be unified, but inference already looks like it is splitting into Cloud and edge (mobile, IoT, battery-powered) segments. Do we need multiple inference benchmark suites?
最后一个问题非常关键,就是Inference的应用是千差万别的。和目前Training应用相对单一不同,Inference首先就可以分为Cloud和Edge端应用,而再细分又可以分成很多类别,而它们又有各自的特点。我们是否需要针对每个应用做不同的Benchmark呢?
除了上述问题,我还可以举出很多例子,而这些问题大部分是源于Inference应用领域的差异性和实现选择的多样性。再引用一位朋友的评论,“领域处理器的benchmark不好做,BDTI的DSP benchmark做了很久,也不是很成功”。这个问题确实非常困难,我觉得短期可能很难有统一的Benchmark出现。
未来Inference的Benchmark很可能要绑定应用。也许有这样一种可能,随着某个Inference应用的成功,逐渐形成一些公认的指标或者出现行业标准,那么Benchmark就比较容易了。在这之前,大家还是可以自说自话,我们也只能看得云里雾里。
- END-
题图来自网络,版权归原作者所有
本文为个人兴趣之作,仅代表本人观点,与就职单位无关


