论文浅尝 | Wordly Wise(WoW) - 用于语音视觉知识问答的跨语言知识融合模型

笔记整理: 谭亦鸣,东南大学博士生
来源:NAACL’21
链接:https://aclanthology.org/2021.naacl-main.153.pdf
论文提出了一种新的知识图谱问答数据集命名为FVSQA,这是一种语音视觉知识问答类型的任务,即问题形式为音频,问题基于一个图片提出,答案是来自知识图谱的事实。FVSQA包含三个子任务:
1.基于语音转文本的问答;2.(不转文本情况下的)端到端模型;3.跨语言任务,即问题的音频语言与知识图谱语言不同情况下的问答。
背景与动机
基于事实的视觉问答(FVQA)要求问答系统依据针对图像提出的问题,从给定的知识图谱中找到对应的事实答案。该任务旨在使模型模仿人类回答视觉问题时如何利用背景知识。但是作者认为现有的问答任务未考虑到(多语言)音频接口的情况,考虑到目前逐渐成熟的语音识别系统,直接使用语音提问,构建一个直接使用语音信号的端到端问答模型是指的考虑的研究方向。
贡献
作者总结论文的主要贡献如下:
1.论文提出了一个新的基于事实的视觉音频问答任务,并建立了一个数据集FVSQA包含5小时长度的语音数据,覆盖英语,印地语以及土耳其语。2.作者训练了一个直接使用语音信号的端到端问答模型WoW,这是第一个不需要语音识别解析模块的语音知识图谱问答模型
方法
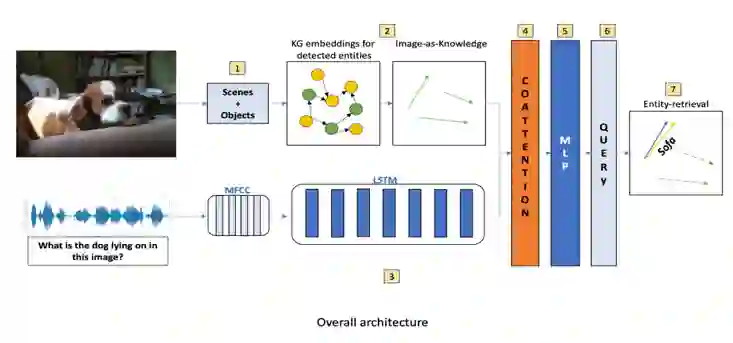
论文的方法的整体过程如图所示,首先问题和场景检测器是被图像中的实体构成,然后图像被表示为检测到的实体的KG embedding特征集合,语音问题的MFCC特征由LSTM编码并传递到co-attention层,与图像编码进行融合,经过一个全连接层后,到达查询层,最后与查询最接近的实体被获取作为问题的答案
co-attention层的结构如下图:
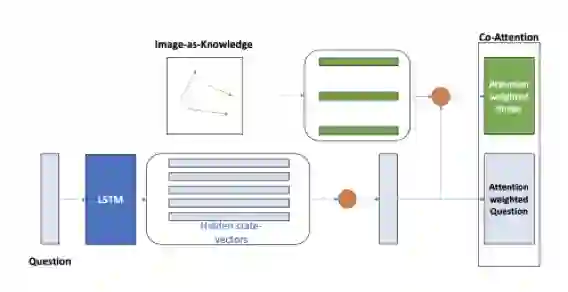
这个部分的目的是融合语音问题表示以及图像表示,首先由自注意力提供一个单独的语音信号的问题embedding,然后问题embedding引导视觉attention的权重(就像文本embedding做的那样)。
FVSQA数据集的统计信息如下表
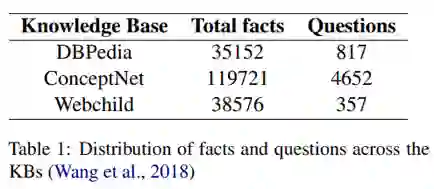
多语言数据借助了亚马逊翻译API完成,然后由人工校验,以确保问题的正确性。
实验
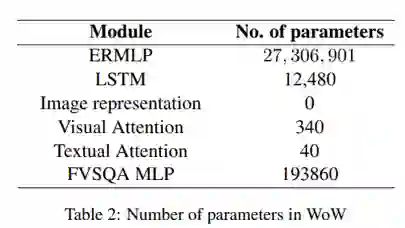
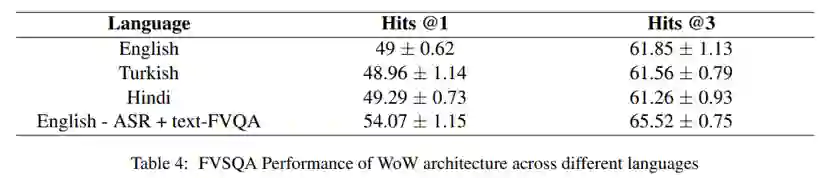
WoW模型的参数数量如表2所示 最终的实验结果如下表:
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。



