必读!2018最具突破性计算机视觉论文Top 10

新智元报道
新智元报道
来源; topbots.com
编辑:肖琴、三石
【新智元导读】本文总结了2018年以来最重要的10篇计算机视觉/图像生成相关的研究,包括许多新颖的架构设计,图像生成方面的突破等。
自从卷积神经网络在特定的图像识别任务上开始超越人类以来,计算机视觉领域的研究一直在飞速发展。
CNN(或ConvNets)的基本架构是在20世纪80年代开发的。Yann LeCun在1989年通过使用反向传播训练模型识别手写瘦子,改进了最初的设计。
自那以后,这个领域取得了长足的进步。
在2018年,我们看到计算机视觉领域出现了许多新颖的架构设计,这些设计改进性能基准,也扩大了机器学习的模型可以分析的媒介范围。
在图像生成方面,我们也看到了一些突破,包括逼真的风格转换、高分辨率的图像生成和视频到视频的合成。
我们在不久前总结了2018年的顶级机器学习论文。由于计算机视觉和图像生成对于AI应用的重要性和普及性,本文中,我们总结了2018年最重要的10篇视觉相关的研究。
以下是我们精选的2018必读计算机视觉论文Top 10:
Spherical CNNs
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
A Closed-form Solution to Photorealistic Image Stylization
Group Normalization
Taskonomy: Disentangling Task Transfer Learning
Self-Attention Generative Adversarial Networks
GANimation: Anatomically-aware Facial Animation from a Single Image
Video-to-Video Synthesis
Everybody Dance Now
Large Scale GAN Training for High Fidelity Natural Image Synthesis
标题:Spherical CNNs
作者:Taco S. Cohen, Mario Geiger, Jonas Koehler, Max Welling
https://arxiv.org/abs/1801.10130
论文摘要
卷积神经网络(CNN)可以很好的处理二维平面图像的问题。然而,对球面图像进行处理需求日益增加。例如,对无人机、机器人、自动驾驶汽车、分子回归问题、全球天气和气候模型的全方位视觉处理问题。将球形信号的平面投影作为卷积神经网络的输入的这种天真做法是注定要失败的,因为这种投影引起的空间扭曲会导致CNN无法共享权重。
这篇论文介绍了球形CNN的基本构建块。我们提出了利用广义傅里叶变换(FFT)进行快速群卷积(互相关)的操作。我们证明了球形CNN在三维模型识别和分子能量回归分析中的计算效率、数值精度和有效性。
概要总结
汽车、无人机和其他机器人使用的全向摄像机能够捕捉到它们周围环境的球形图像。我们可以通过将这些球形信号投射到平面上并使用CNN来分析它们。然而,球形信号的任何平面投影都会导致失真。为了解决这个问题,来自阿姆斯特丹大学的研究小组引入了球形CNN的理论,这种网络可以分析球形图像,而不会被扭曲所欺骗。该方法在3D形状和球形MNIST图像的分类以及分子能量回归分析(计算化学中的一个重要问题)中都有很好的效果。
核心思想
球形信号的平面投影会导致严重的失真,因为有些区域看起来比实际面积大或小。
传统的CNN对于球形图像来说是无效的,因为当物体在球体周围移动时,它们也会出现收缩和拉伸(试想一下,地图上格陵兰岛看起来比它实际要大得多)。
解决方案是使用球形CNN,它对输入数据中的球形旋转具有稳健性。球形神经网络通过保持输入数据的原始形状,平等地对待球面上的所有对象而不失真。
最重要的成果
提出了构建球形CNN的数学框架。
提供了易于使用、快速且内存高效的PyTorch代码来实现这些CNN。
为球形CNN在旋转不变学习问题中的应用提供了第一个经验支持:
球形MNIST图像的分类
3D形状分类,
分子能量回归分析。
AI社区的评价
这篇论文获得了ICLR 2018年的最佳论文奖,ICLR是一个领先的机器学习会议。
未来研究方向
为球体开发一个可操纵的CNN来分析球体上向量束的截面(例如,风向)。
将数学理论从2D球面扩展到3D点云,用于在反射和旋转下不变的分类任务。
可能的应用
能够分析球面图像的模型可以应用于以下问题:
无人机、机器人和自动驾驶汽车的全向视觉;
计算化学中的分子回归问题
全球天气和气候模型。
代码
作者在GitHub上提供了这篇论文的原始实现:
https://github.com/jonas-koehler/s2cnn
标题:Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
作者:Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow, Jascha Sohl-Dickstein
https://arxiv.org/abs/1802.08195
论文摘要
机器学习模型很容易受到对抗性样本(adversarial examples)的影响:图像中的微小变化会导致计算机视觉模型出错,比如把一辆校车误识别成鸵鸟。然而,人类是否容易犯类似的错误,这仍然是一个悬而未决的问题。在这篇论文中,我们通过利用最近的技术来解决这个问题,这些技术可以将具有已知参数和架构的计算机视觉模型转换为具有未知参数和架构的其他模型,并匹配人类视觉系统的初始处理。我们发现,在计算机视觉模型之间强烈转移的对抗性样本会影响有时间限制的人类观察者做出的分类。
概要总结
谷歌大脑的研究人员正在寻找这个问题的答案:那些不是特定于模型的对抗样本,并且可以在不访问模型的参数和架构的情况下欺骗不同的计算机视觉模型,是否同时也可以欺骗有时间限制的人类?他们利用机器学习、神经科学和心理物理学的关键思想,创造出对抗性样本,这些样本确实在时间有限的设置下影响人类的感知。因此,这篇论文介绍了一种人类和机器之间共享的错觉。

核心思想
在第一步中,研究人员使用黑盒对抗性样本构建技术,在不访问模型架构或参数的情况下创建对抗性示例。
然后,他们调整计算机视觉模型来模拟人类最初的视觉过程,包括:
在每个模型前面加上视网膜层,视网膜层对输入进行预处理,从而结合人眼执行的一些转换;
对图像进行偏心依赖的模糊处理,以接近受试者的视觉皮层通过其视网膜晶格接收到的输入。
人类的分类决策在一个有时间限制的环境中进行评估,以检测人类感知中的细微影响。
最重要的成果
表明在计算机视觉模型之间传递的对抗性样本也成功地影响了人类的感知。
证明了卷积神经网络与人类视觉系统的相似性。
AI社区的评价
这篇论文在AI社区得到广泛讨论。尽管大多数研究人员对这些结果感到震惊,但一些人认为,我们需要对对抗性图像进行更严格的定义,因为如果人类将受到干扰的猫图像归类为狗,那么它很可能已经是狗,而不是猫了。
未来研究方向
研究哪些技术对于将对抗性样本转移到人类身上是至关重要的(视网膜预处理,模型集成)。
可能的应用
从业者应该考虑这样一种风险,即图像可能被操纵,导致人类观察者产生不寻常的反应,因为对抗性样本可能会在我们意识不到的情况下影响我们。
标题:A Closed-form Solution to Photorealistic Image Stylization
作者:Yijun Li, Ming-Yu Liu, Xueting Li, Ming-Hsuan Yang, Jan Kautz
https://arxiv.org/abs/1802.06474
论文摘要
照片级逼真的图像风格化涉及到将参考照片的风格转换为内容照片,其约束条件是,经过风格化的照片应保持照片级逼真程度。虽然存在多种逼真的图像风格化方法,但它们往往会产生具有明显伪影的空间不一致。在这篇论文中,我们提出一种解决这些问题的方法。
该方法由风格化步骤(stylization step)和平滑步骤(smoothing step)组成。当风格化步骤将引用照片的样式转换为内容照片时,平滑步骤确保空间上一致的样式化。每个步骤都有一个封闭的解决方案,可以有效地计算。我们进行了广泛的实验验证。结果表明,与其他方法相比,该方法生成的逼真风格输出更受受试者的青睐,同时运行速度更快。源代码和其他结果可在https://github.com/NVIDIA/FastPhotoStyle获得。
概要总结
英伟达(NVIDIA)和加州大学默塞德分校的研究团队提出了一种新的解决照片级图像风格化的方法——FastPhotoStyle。该方法包括两个步骤:风格化和平滑化。大量的实验表明,该方法生成的图像比以前的最先进的方法更真实、更引人注目。更重要的是,由于采用封闭式的解决方案,FastPhotoStyle生成风格化图像的速度比传统方法快49倍。

核心思想
照片级真实的图像风格化的目标是在保持输出图像逼真的同时,将参考照片的风格转换为内容照片。
任务分为风格化和平滑化两个步骤:
风格化步骤是基于增白和着色变换(WCT),通过特征投影处理图像。然而,由于WCT是为艺术图像的风格化而开发的,因此,它常常会生成用于照片级真实图像风格化的结构构件。为了解决这个问题,本文引入了PhotoWCT方法,将WCT中的上采样层替换为非池化层,从而保留了更多的空间信息。
平滑步骤用于解决第一步之后可能出现的空间不一致的样式。平滑基于流形排序算法。
这两个步骤都具有封闭形式的解决方案,这意味着可以通过固定数量的操作(即,卷积、最大池化、增白等)。因此,计算比传统方法更有效。
最重要的成果
提出了一种新的图像风格化化方法:FastPhotoSyle,其中:
通过渲染更少的结构伪影和不一致样式,从而比艺术风格化算法表现更好;
通过不仅合成风格照片中色彩,而且合成风格照片的图案,从而优于照片级真实的风格化算法。
实验表明,在风格化化效果(63.1%)和光真实感(73.5%)方面,用户更喜欢FastPhotoSyle的结果,而不是之前的最先进的技术。
FastPhotoSyle可以在13秒内合成一张分辨率为1024 x 512的图像,而之前最先进的方法需要650秒才能完成相同的任务。
AI社区的评价
该论文在欧洲计算机视觉会议ECCV 2018上发表。
未来研究方向
找到一种从风格照片迁移小图案的方法,因为这篇论文提出的方法可以将它们平滑化。
探索进一步减少风格化照片中的结构伪影数量的可能性。
可能的应用
内容创建者可以从照片级真实的图像风格化技术中获得很大的好处,因为该技术基本上允许你根据适合的内容自动更改任何照片的风格。
摄影师们也将受到这项技术的影响。
代码
NVIDIA团队提供了该论文在GitHub上的原始实现:
https://github.com/NVIDIA/FastPhotoStyle
标题:Group Normalization
作者:吴育昕, 何恺明
https://arxiv.org/abs/1803.08494
论文摘要
批标准化(Batch Normalization, BN)是深度学习进展中的一项里程碑式技术,它使各种网络都能进行训练。但是,沿batch dimension进行标准化会带来一些问题——由于批统计估计不准确,当batch size变小时,BN的误差会迅速增大。这限制了BN用于训练更大模型和将特征迁移到计算机视觉任务(包括检测、分割和视频)的用途,这些任务受内存消耗限制,需要小的batch size。
在这篇论文中,我们提出了组标准化(Group Normalization ,GN),作为BN的简单替代。GN将通道划分为组,并在每个组内计算均值和方差以进行标准化。GN的计算独立于batch sizes,在各种范围的batch sizes精度稳定。
在ImageNet上训练的ResNet-50,当batch size 为2时,GN的误差比BN小10.6%;在使用典型 batch size时,GN与BN一般好,并且优于其他标准化变体。此外,GN可以很自然地从预训练过渡到 fine-tuning。GN在COCO的目标检测和分割任务,以及在Kinetics的视频分类任务中都优于基于BN的同类算法,这表明GN可以在各种任务中有效地替代强大的BN。GN可以通过现代库中的几行代码轻松实现。
概要总结
Facebook AI研究团队建议使用Group Normalization (GN)代替Batch Normalization (BN)。这篇论文的作者是FAIR的吴育昕和何恺明,他们认为,对于small batch sizes,BN的错误会急剧增加。这限制了BN的使用,因为当使用大型模型来解决计算机视觉任务时,由于内存限制而需要小的batch sizes。相反,Group Normalization与batch sizes无关,因为它将通道划分为组,并计算每个组内标准化的均值和方差。实验证实,GN在目标检测、分割、视频分类等多种任务中都优于BN。
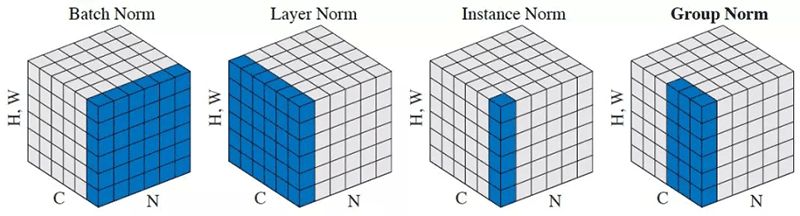
核心思想
Group Normalization是Batch Normalization的一个简单替代方法,特别是在batch size较小的场景中,例如需要高分辨率输入的计算机视觉任务。
GN只探索层的维数,因此它的计算是独立于batch size的。具体地说,GN将通道或特征映射划分为组,并在每个组内对特征标准化。
Group Normalization可以通过PyTorch和TensorFlow中的几行代码轻松实现。
最重要的成果
提出了Group Normalization,一种新的有效的归一化方法。
评估了GN在各种应用中的表现,并表明:
GN的计算独立于batch sizes,在大范围的batch sizes中精度稳定。例如,对于batch size为2的ImageNet训练的ResNet-50, GN的错误率比基于BN的模型低10.6%。
GN也可以转移到fine-tuning。实验表明,在COCO数据集的目标检测和分割任务,以及Kinetics数据集的视频分类任务,GN优于BN。
AI社区的评价
该论文在ECCV 2018上获得了最佳论文提名。
根据Arxiv Sanity Preserver,这篇论文也是2018年第二受欢迎的论文。
未来研究方向
将group normalization应用到序列模型或生成模型。
研究GN在强化学习的学习表示方面的表现。
探索GN与合适的正则化项相结合能否改善结果。
可能的应用
依赖基于BN的模型进行对象检测、分割、视频分类和其他需要高分辨率输入的计算机视觉任务的应用可能会受益于基于GN的模型,因为它们在这些设置中更准确。
代码
FAIR团队提供Mask R-CNN基线结果和使用Group normalize训练的模型:
https://github.com/facebookresearch/Detectron/tree/master/projects/GN
GitHub上也提供了使用PyTorch实现的group normalization:
https://github.com/chengyangfu/pytorch-groupnormalization
标题:Taskonomy: Disentangling Task Transfer Learning
By Amir R. Zamir,Alexander Sax,William Shen,Leonidas J. Guibas,Jitendra Malik,Silvio Savarese(2018)
https://arxiv.org/abs/1804.08328
论文摘要
视觉任务之间有关联吗?例如,表面法线可以简化对图像深度的估计吗?直觉回答了这些问题,暗示了视觉任务中存在结构。了解这种结构具有显著的价值;它是迁移学习的基本概念,提供了一种原则性的方法来识别任务之间的冗余。
我们提出了一种完全计算的可视化任务空间结构建模方法。 这是通过在潜在空间中的二十六个2D,2.5D,3D和语义任务的字典中查找(一阶和更高阶)传递学习依赖性来完成的。该产品是用于任务迁移学习的计算分类映射。我们研究这种结构的结果,例如出现的非平凡关系,并利用它们来减少对标记数据的需求。例如,我们展示了在保持性能几乎相同的情况下,解决一组10个任务所需的标记数据点的总数可以减少大约2/3(与独立训练相比)。我们提供了一组用于计算和探测这种分类结构的工具,包括一个解决程序,用户可以使用它来为他们的用例设计有效的监督策略。
概览
自现代计算机科学的早期以来,许多研究人员就断言视觉任务之间存在一个结构。现在Amir Zamir和他的团队试图找到这个结构。他们使用完全计算的方法建模,并发现不同可视化任务之间的许多有用关系,包括一些重要的任务。他们还表明,通过利用这些相互依赖性,可以实现相同的模型性能,标记数据要求大约减少2/3。
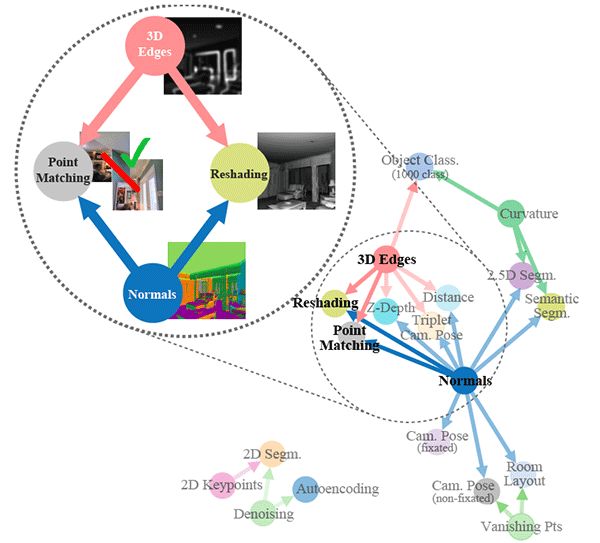
核心思想
了解不同可视化任务之间关系的模型需要更少的监督、更少的计算和更可预测的行为。
一种完整的计算方法来发现视觉任务之间的关系是可取的,因为它避免了强加的、可能是不正确的假设:先验来自于人类的直觉或分析知识,而神经网络可能在不同的原理上运作。
最重要的成果
识别26个常见视觉任务之间的关系,如目标识别、深度估计、边缘检测和姿态估计。
展示这个结构如何帮助发现对每个视觉任务最有效的迁移学习类型。
AI社区的评价
该论文在计算机视觉与模式识别重要会议CVPR 2018上获得了最佳论文奖。
结果非常重要,因为对于大多数实际任务,大规模标记数据集不可用。
未来研究方向
从一般的视觉任务完全由人类定义的模型,转向将人类定义的视觉任务视为由计算发现的潜在子任务组成的观察样本的方法。
探索将发现转化为不完全是视觉任务的可能性。
可能的应用
在本文中发现的关系可以用来构建更有效的视觉系统,这个系统将需要更少的标记数据和更低的计算成本。
代码
https://github.com/StanfordVL/taskonomy/tree/master/taskbank
标题:Self-Attention Generative Adversarial Networks
作者:Han Zhang, Ian Goodfellow, Dimitris Metaxas, Augustus Odena
https://arxiv.org/abs/1805.08318
论文摘要
在这篇论文中,我们提出了自注意力生成对抗网络(SAGAN),它允许对图像生成任务进行注意力驱动、长期依赖关系建模。
在低分辨率特征图中,传统的卷积GAN只根据空间局部点生成高分辨率细节。在SAGAN中,可以使用来自所有特征位置的线索生成细节。此外,该鉴别器还可以检查图像中较远部分的细节特征是否一致。
最近的研究表明,生成器的调节会影响GAN的性能。利用这一点,我们将频谱归一化应用于GAN发生器,并发现这改善了训练的动态性。
在具有挑战性的ImageNet数据集上,提出的SAGAN实现了最佳的结果,将最佳Inception分数从36.8提高到52.52,并将Frechet Inception距离从27.62降低到18.65。注意力层的可视化显示,生成器利用的是与对象形状对应的邻域,而不是固定形状的局部区域。
概要总结
传统的卷积神经网络在图像合成方面显示了较为优秀的结果。然而,它们至少有一个重要的弱点——单独的卷积层无法捕捉图像中的几何和结构模式。由于卷积是一种局部操作,所以左上方的输出几乎不可能与右下方的输出有任何关系。
本文介绍了一个简单的解决方案 - 将自注意力机制纳入GAN框架。 该解决方案与几种稳定技术相结合,有助于自注意力生成对抗网络(SAGAN)在图像合成中实现最佳的结果。

核心思想
单独的卷积层在计算图像中的长程依赖关系计算时效率低。相反,将自注意机制融入到GAN框架中,将使生成器和鉴别器都能够有效地建模广泛分离的空间区域之间的关系。
自注意力模块将一个位置的响应计算为所有位置特征的加权和。
以下技术有助于在具有挑战性的数据集上稳定GAN的训练:
对发生器和鉴别器应用光谱归一化。研究人员认为,鉴别器和发生器都能从光谱归一化中受益,因为它可以防止参数幅度的增大,避免异常梯度。
对发生器和鉴别器使用单独的学习速率来补偿正则化鉴别器中慢学习的问题,并使每个鉴别器步骤使用更少的发生器步骤成为可能。
最重要的成果
事实上,将自注意力模块合并到GAN框架中可以有效地建模长期依赖关系。
验证了所提出的稳定化技术在GAN训练中的有效性。特别是表明:
应用于生成器的频谱归一化稳定了GAN训练;
利用不均衡的学习速率可以加快正规化鉴别器的训练。
通过将Inception的分数从36.8提高到52.52,并将Frechet Inception的距离从27.62降低到18.65,从而在图像合成方面获得最先进的结果。
AI社区的评价
威斯康星大学麦迪逊分校统计学助理Sebastian Raschka教授表示:“这个想法简单直观,却非常有效,而且易于实施。”
未来研究方向
探索减少GAN产生的奇怪样本数量的可能性
可能的应用
使用GAN进行图像合成可以替代用于广告和电子商务目的的昂贵手工媒体创建。
代码
GitHub上提供了自注意力GAN的PyTorch和TensorFlow实现。
PyTorch:
https://github.com/heykeetae/Self-Attention-GAN
TensorFlow:
https://github.com/brain-research/self-attention-gan
标题:从单个图像中获取具有人脸解剖结构的面部动画
作者:Albert Pumarola, Antonio Agudo, Aleix M. Martinez, Alberto Sanfeliu, Francesc Moreno-Noguer
https://arxiv.org/abs/1807.09251
论文摘要
若是能单凭一张图像就能自动地将面部表情生成动画,那么将会为其它领域中的新应用打开大门,包括电影行业、摄影技术、时尚和电子商务等等。随着生成网络和对抗网络的流行,这项任务取得了重大进展。像StarGAN这样的结构不仅能够合成新表情,还能改变面部的其他属性,如年龄、发色或性别。虽然StarGAN具有通用性,但它只能在离散的属性中改变面部的一个特定方面,例如在面部表情合成任务中,对RaFD数据集进行训练,该数据集只有8个面部表情的二元标签(binary label),分别是悲伤、中立、愤怒、轻蔑、厌恶、惊讶、恐惧和快乐。
为达到这个目的,我们使用EmotioNet数据集,它包含100万张面部表情(使用其中的20万张)图像。并且构建了一个GAN体系结构,其条件是一个一维向量:表示存在/缺失以及每个动作单元的大小。我们以一种无监督的方式训练这个结构,仅需使用激活的AUs图像。为了避免在不同表情下,对同一个人的图像进行训练时出现冗余现象,将该任务分为两个阶段。首先,给定一张训练照片,考虑一个基于AU条件的双向对抗结构,并在期望的表情下呈现一张新图像。然后将合成的图像还原到原始的样子,这样可以直接与输入图像进行比较,并结合损失来评估生成图像的照片级真实感。此外,该系统还超越了最先进的技术,因为它可以在不断变化的背景和照明条件下处理图像。
概要总结
本文介绍了一种新的GAN模型,该模型能够在不断变化的背景和光照条件下,从单个图像生成具有解剖学感知的面部动画。而在此之前,只能解决离散情感类编辑和人像图像的问题。该方法通过将面部变形编码为动作单元来呈现多种情绪。即使在具有挑战性的光照条件和背景,得到的动画演示了一个非常平滑和一致的转换帧。

核心思想
面部表情可以用动作单元(AU)来描述,其在解剖学上描述特定面部肌肉的收缩。 例如,“恐惧”的面部表情通常通过以下激活产生:Inner Brow Raiser(AU1),Outer Brow Raiser(AU2),Brow Lowerer(AU4),Upper Lid Raiser(AU5),Lid Tightener(AU7) ,Lip Stretcher(AU20)和Jaw Drop(AU26)。 每个AU的大小定义了情绪的程度。
合成人脸动画的模型是基于GAN架构的,它以一维向量为条件,表示每个动作单元的存在/不存在和大小。
为了避免同一人在不同表情下的训练图像对的需要,使用双向发生器将图像转换成所需的表情,并将合成的图像转换回原始姿态。
为了在不断变化的背景和光照条件下处理图像,该模型包括一个注意力层,该注意力层只将网络的动作集中在图像中与表达新表情相关的区域。
最重要的成果
引入一种全新的GAN模型用于野外人脸动画,该模型可以在完全无监督的情况下进行训练,并在具有挑战性的光照条件和非真实世界数据的情况下,通过帧间非常平滑和一致的转换生成具有视觉吸引力的图像。
演示如何通过在GAN已经看到的情绪之间进行插值来生成更丰富的情绪。
AI社区的评价
该论文在欧洲计算机视觉会议(ECCV 2018)上获得了荣誉奖。
未来研究方向
将该方法应用于视频序列。
可能的应用
这项技术可以从一张图片中自动生成面部表情动画,可以应用于时尚界和电子商务、电影行业、摄影技术等多个领域。
代码
作者提供了本研究论文在GitHub上的原始实现地址:
https://github.com/albertpumarola/GANimation
标题:视频到视频的合成Video-to-Video Synthesis
作者:Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, Bryan Catanzaro
https://arxiv.org/abs/1808.06601
论文摘要
本文研究的问题是视频到视频(Video-to-Video)的合成,其目标是学习一个映射函数从一个输入源视频(例如,语义分割掩码序列)到一个输出逼真的视频,准确地描述了源视频的内容。
与之对应的图像到图像的合成问题是一个热门话题,而视频到视频的合成问题在文献中研究较少。在不了解时间动态的情况下,直接将现有的图像合成方法应用于输入视频往往会导致视频在时间上不连贯,视觉质量低下。
本文提出了一种在生成对抗学习框架下的视频合成方法。通过精心设计的生成器和鉴别器架构,再加上时空对抗目标,可以在一组不同的输入格式(包括分割掩码、草图和姿势)上获得高分辨率、逼真的、时间相干的视频结果。
在多个基准上的实验表明,与强基线相比,本文的方法具有优势。特别是该模型能够合成长达30秒的街道场景的2K分辨率视频,大大提高了视频合成的技术水平。最后,将该方法应用于未来的视频预测,表现优于几个最先进的系统。
概要总结
英伟达的研究人员引入了一种新的视频合成方法。该框架基于条件甘斯。具体地说,该方法将精心设计的发生器和鉴别器与时空对抗性目标相结合。实验表明,所提出的vid2vid方法可以在不同的输入格式(包括分割掩码、草图和姿势)上合成高分辨率、逼真、时间相干的视频。它还可以预测下一帧,其结果远远优于基线模型。

核心思想
视频帧可以按顺序生成,每个帧的生成只取决于三个因素:
电流源帧;
之前的两个源帧;
之前两个生成的帧。
使用多个鉴别器可以缓解GAN训练过程中的模式崩溃问题:
条件图像鉴别器确保每个输出帧类似于给定相同源图像的真实图像;
条件视频鉴别器确保连续输出帧类似于给定相同光流的真实视频的时间动态。
在生成器设计中,前背景先验进一步提高了模型的综合性能。
使用软遮挡掩码代替二进制可以更好地处理“放大”场景:我们可以通过逐渐混合扭曲像素和新合成像素来添加细节。
最重要的成果
在视频合成方面优于强基线:
生成高分辨率(2048х2048)、逼真、时间相干视频30秒;
根据采样不同的特征向量,输出多个具有不同视觉外观的视频。
在未来的视频预测中优于基线模型:
开源了一个PyTorch技术的实现。此代码可用于:
将语义标签转换为现实世界的视频;
从边缘映射生成正在说话的人的多个输出;
在给定的姿势下生成整个人体。
AI社区的评价
艺术家兼程序员吉恩·科根(Gene Kogan)说:“英伟达的新vid2vid是第一个开源代码,它可以让你从一个源视频中令人信服地伪造任何人的脸。”
这篇论文也受到了一些批评,因为有人担心它可能被用来制作深度伪造或篡改的视频,从而欺骗人们。
未来研究方向
使用对象跟踪信息,确保每个对象在整个视频中具有一致的外观。
研究是否使用较粗糙的语义标签训练模型将有助于减少在语义操纵之后出现的可见伪像(例如,将树木变成建筑物)。
添加额外的3D线索,如深度地图,以支持汽车转弯的合成。
可能的应用
市场营销和广告可以从vid2vid方法创造的机会中获益(例如,在视频中替换面部甚至整个身体)。然而,这应该谨慎使用,需要想到道德伦理方面的一些顾虑。
代码
英伟达团队提供了本研究论文在GitHub上的原始实现的代码:
https://github.com/NVIDIA/vid2vid
标题:人人都在跳舞
作者:Caroline Chan, Shiry Ginosar, Tinghui Zhou, Alexei A. Efros
https://arxiv.org/abs/1808.07371
论文摘要
本文提出了一种简单的“按我做”的动作转移方法:给定一个人跳舞的源视频,我们可以在目标对象执行标准动作几分钟后将该表演转换为一个新的(业余)目标。
本文提出这个问题作为每帧图像到图像的转换与时空平滑。利用位姿检测作为源和目标之间的中间表示,我们调整这个设置为时间相干视频生成,包括现实的人脸合成。学习了从位姿图像到目标对象外观的映射。视频演示可以在https://youtu.be/PCBTZh41Ris找到。
概要总结
加州大学伯克利分校的研究人员提出了一种简单的方法,可以让业余舞蹈演员像专业舞蹈演员一样表演,从而生成视频。如果你想参加这个实验,你所需要做的就是录下你自己表演一些标准动作的几分钟的视频,然后拿起你想要重复的舞蹈的视频。
神经网络将完成主要工作:它将问题解决为具有时空平滑的每帧图像到图像的转换。通过将每帧上的预测调整为前一时间步长的预测以获得时间平滑度并应用专门的GAN进行逼真的面部合成,该方法实现了非常惊人的结果。
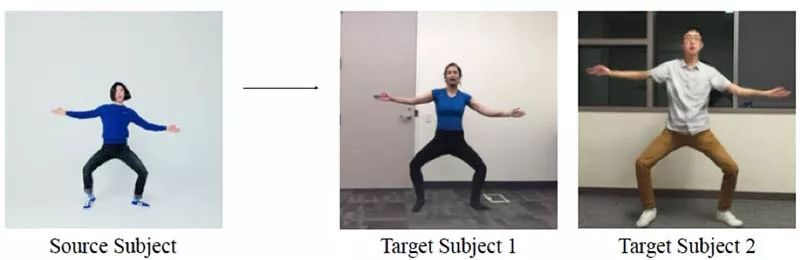
核心思想
“跟我做”动传递被视为每帧图像到图像的平移,姿势棒图作为源和目标之间的中间表示:
预先训练的最先进的姿势检测器根据源视频创建姿势棒图;
应用全局姿势标准化来解释框架内的体形和位置中的源和目标主体之间的差异;
标准化的姿势棒图被映射到目标对象。
为了使视频流畅,研究人员建议在先前生成的帧上调节发生器,然后将两个图像提供给鉴别器。 姿势关键点上的高斯平滑允许进一步减少抖动。
为了生成更逼真的面部,该方法包括额外的面部特定GAN,其在主生成完成之后刷新面部。
最重要的成果
根据定性和定量评估,提出了一种优于强基线(pix2pixHD)的运动传输新方法。
演示特定于人脸的GAN为输出视频添加了相当多的细节。
AI社区的评价
谷歌大脑的技术人员汤姆·布朗(Tom Brown)说:“总的来说,我觉得这真的很有趣,而且执行得很好。期待代码的公布,这样我就可以开始训练我的舞步了。”
Facebook人工智能研究工程师Soumith Chintala说:“卡洛琳·陈(Caroline Chan)、阿廖沙·埃夫罗斯(Alyosha Efros)和团队将舞蹈动作从一个主题转移到另一个主题。只有这样我才能跳得好。了不起的工作! ! !”
未来研究方向
用时间相干的输入和专门为运动传输优化的表示来替换姿态棒图。
可能的应用
“跟我做”在制作营销和宣传视频时,可能会应用动作转移来替换主题。
代码
本研究论文的PyTorch实现可在GitHub上获得:
https://github.com/nyoki-mtl/pytorch-EverybodyDanceNow
标题:Large Scale GAN Training For High Fidelity Natural Image Synthesis
By Andrew Brock,Jeff Donahue,Karen Simonyan(2018)
https://arxiv.org/abs/1809.11096
论文摘要
尽管生成图像建模最近取得了进展,但从ImageNet等复杂数据集成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,我们在最大的规模下进行了生成对抗网络的训练,并研究了这种规模下的不稳定性。我们发现,将正交正则化应用于发生器,使其服从于一个简单的“截断技巧”,可以允许通过截断潜在空间来精细控制样本保真度和多样性之间的权衡。 我们的修改使得模型在类条件图像合成中达到了新的技术水平。 当我们在ImageNet上以128×128分辨率进行训练时,我们的模型(BigGAN)的初始得分(IS)为166.3,Frechet初始距离(FID)为9.6。
概览
DeepMind团队发现,当前的技术足以从现有数据集(如ImageNet和JFT-300M)合成高分辨率、多样化的图像。他们特别指出,生成对抗网络(GANs)可以生成看起来非常逼真的图像,如果它们在非常大的范围内进行训练,即使用比以前实验多2到4倍的参数和8倍的批处理大小。这些大规模的GAN,或BigGAN,是类条件图像合成的最新技术。

核心思想
随着批(batch)大小和参数数量的增加,GAN的性能更好。
将正交正则化应用到生成器中,使模型响应特定的技术(“截断技巧”),该技术提供了对样本保真度和多样性之间的权衡的控制。
最重要的成果
证明GAN可以从scaling中获益;
构建允许显式、细粒度地控制样本多样性和保真度之间权衡的模型;
发现大规模GAN的不稳定性;
BigGAN在ImageNet上以128×128分辨率进行训练:初始得分(IS)为166.3,之前的最佳IS为52.52;Frechet Inception Distance (FID)为9.6,之前最好的FID为18.65。
AI社区的评价
该论文正在为ICLR 2019做准备;
自从Big Hub上线BigGAN发生器之后,来自世界各地的AI研究人员正在玩BigGAN,来生成狗,手表,比基尼图像,蒙娜丽莎,海滨以及更多主题。
未来研究方向
迁移到更大的数据集以减少GAN稳定性问题;
探索减少GAN产生的奇怪样本数量的可能性。
可能的应用
取代昂贵的手工媒体创作,用于广告和电子商务的目的。
更多阅读
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。


