只要保留定位感知通道,目标检测模型也能剪枝70%参数
作者 | Bbuf
 下面要介绍的论文发于2019,题为「Localization-aware Channel Pruning for Object Detection」
下面要介绍的论文发于2019,题为「Localization-aware Channel Pruning for Object Detection」
研究背景
研究背景
从AlexNet赢得ImageNet比赛:ILSVRC以来,卷积神经网络(CNN)已广泛应用于各种计算机视觉任务如图像分类,目标检测,语义分割等。在这些领域,基于深度学习的方法都实现了最先进的性能。
方法
方法
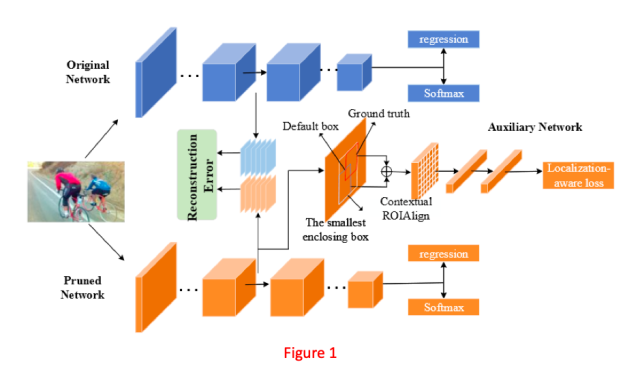
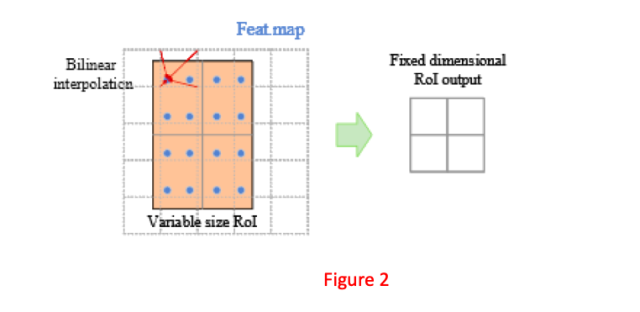
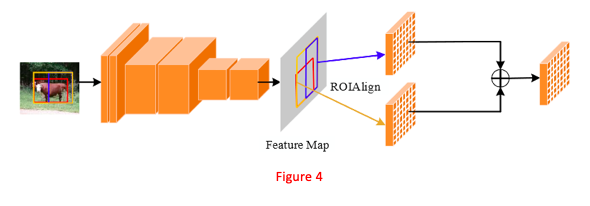
上下文 ROIAlign 层
 但是从Figure3我们可以看到,检测器生成的默认框(Anchor)并不总是完全覆盖到目标,默认框有时候会大于标注(GT)框,有时候会小于GT框。
因此,如果仅仅提取默认框的特征(尤其是在剪枝阶段),则感受野很可能不够。
为了解决这个问题,论文提出了上下文ROIAlign层,引入了更多的语义信息。
但是从Figure3我们可以看到,检测器生成的默认框(Anchor)并不总是完全覆盖到目标,默认框有时候会大于标注(GT)框,有时候会小于GT框。
因此,如果仅仅提取默认框的特征(尤其是在剪枝阶段),则感受野很可能不够。
为了解决这个问题,论文提出了上下文ROIAlign层,引入了更多的语义信息。
 为了更好的描述算法,需要先给一些定义。
对于一个训练实例,
为了更好的描述算法,需要先给一些定义。
对于一个训练实例,
 代表GT框A的坐标,
代表GT框A的坐标,
 表示和A匹配的默认框B的坐标。
同时,用
表示和A匹配的默认框B的坐标。
同时,用
 F 代表特征图
F 代表特征图
 代表
代表
 区域的特征。
区域的特征。
 操作代表ROIAlign层。
首先,利用公式(1)计算A和B的交并比(IOU):
操作代表ROIAlign层。
首先,利用公式(1)计算A和B的交并比(IOU):

 大于预先设定的阈值,则B是正样本,反之B是负样本。
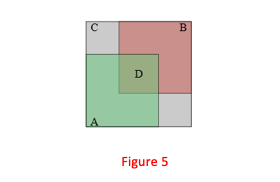
如果B是正样本,我们计算包含A和B的最小的凸多边形C(这个思路和GIoU Loss的思路一致),如下:
大于预先设定的阈值,则B是正样本,反之B是负样本。
如果B是正样本,我们计算包含A和B的最小的凸多边形C(这个思路和GIoU Loss的思路一致),如下:
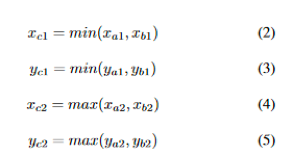
 是C的坐标。
最后上下文ROIAlign层的输出可以表示为:
是C的坐标。
最后上下文ROIAlign层的输出可以表示为:


 ,
和
,
和
 可以用等式(1)到等式(5)计算出来。
Figure5是GIoU的示意图。
可以用等式(1)到等式(5)计算出来。
Figure5是GIoU的示意图。
 表示第i个预测框和GT框的GIoU值,
表示第i个预测框和GT框的GIoU值,
 表示第
表示第
 个预测框的交叉熵。
那么,在剪枝阶段,
个预测框的交叉熵。
那么,在剪枝阶段,
 表示分类损失,
表示分类损失,
 表示回归损失,
表示回归损失,
 表示辅助网络的感知定位损失。
最后在剪枝阶段的正样本损失被定义为下面的等式:
表示辅助网络的感知定位损失。
最后在剪枝阶段的正样本损失被定义为下面的等式:



定位感知的通道剪枝
 代表原始网络模型第l+1层的输出特征图。
这里N,H,Y分别代表输出特征图的通道数和长宽。
最后,使用
代表原始网络模型第l+1层的输出特征图。
这里N,H,Y分别代表输出特征图的通道数和长宽。
最后,使用
 和
和
 代表剪枝网络的分类和回归损失。
为了找到对网络最有效的通道,应该对辅助网络和剪枝网络进行微调,并将微调后的损失定义为它们的损失之和,即:
代表剪枝网络的分类和回归损失。
为了找到对网络最有效的通道,应该对辅助网络和剪枝网络进行微调,并将微调后的损失定义为它们的损失之和,即:


 ,
C 代表选择的通道,
,
C 代表选择的通道,
 代表以
为索引的子矩阵。
考虑到重建误差,辅助网络的定位感知损失,可以指定通道剪枝的规则如下:
代表以
为索引的子矩阵。
考虑到重建误差,辅助网络的定位感知损失,可以指定通道剪枝的规则如下:
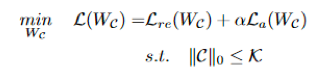
 是一个常量,
是一个常量,
 是选择的通道数量。
直接优化等式(13)是一个NP难问题。
论文仍然沿用DCP算法中的贪心策略,通过考虑等式(13)的梯度来执行通道剪枝。
具体来说,第k个通道的重要性被定义为:
是选择的通道数量。
直接优化等式(13)是一个NP难问题。
论文仍然沿用DCP算法中的贪心策略,通过考虑等式(13)的梯度来执行通道剪枝。
具体来说,第k个通道的重要性被定义为:
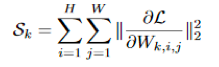 被更新为:
被更新为:
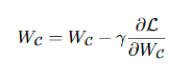
 代表学习率。
在我们更新了
之后,对单个网络层的剪枝就完成了。
代表学习率。
在我们更新了
之后,对单个网络层的剪枝就完成了。

实验
实验
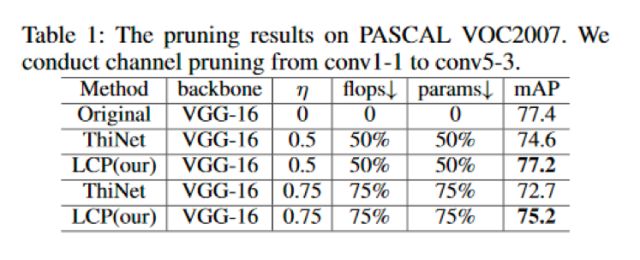
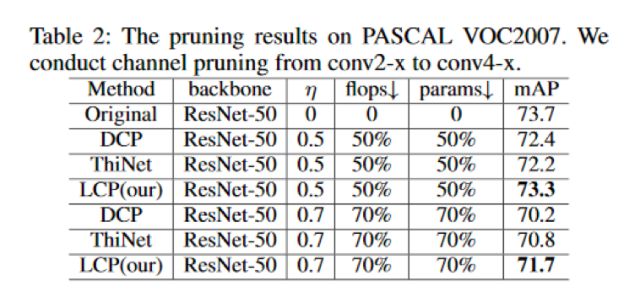
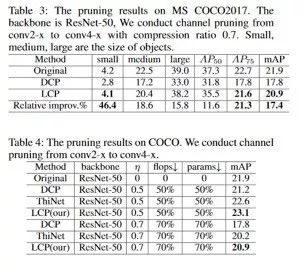
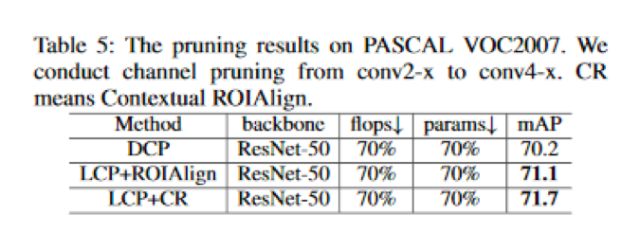
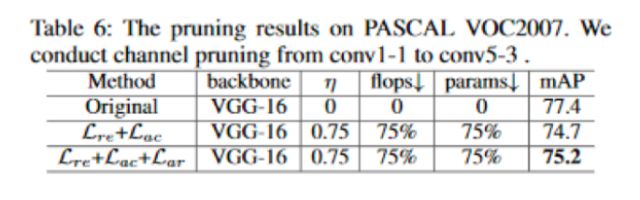
消融研究
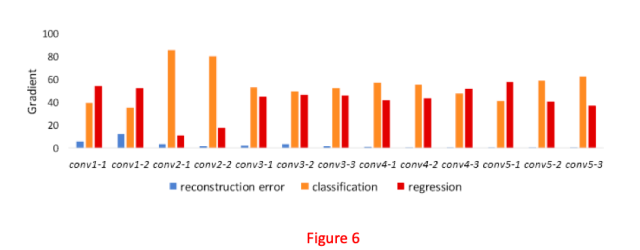
梯度研究

结论
结论
论文提出了一种定位感知的辅助网络,该网络可以让我们直接进行通道修剪以进行目标检测。首先论文设计了具有上下文感知的ROIAlign层的辅助网络,该层可以通过像素对齐获得默认框的精准位置信息,并在剪枝网络浅层时扩大默认框的感受野。然后,论文构造了一个用于目标检测的损失函数,该函数倾向于保留包含分类和回归关键信息的通道。

招 聘
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiawei@leiphone.com

登录查看更多
相关内容

专知会员服务
17+阅读 · 2019年11月17日
Arxiv
3+阅读 · 2019年2月28日
Arxiv
7+阅读 · 2018年5月25日


相关VIP内容
专知会员服务
17+阅读 · 2019年11月17日
相关资讯
相关论文
Arxiv
3+阅读 · 2019年2月28日
Arxiv
7+阅读 · 2018年5月25日