L1和L2正则先验分别服从什么分布


解析:
面试中遇到的,L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
引用自:@齐同学
先验就是优化的起跑线, 有先验的好处就是可以在较小的数据集中有良好的泛化性能,当然这是在先验分布是接近真实分布的情况下得到的了,从信息论的角度看,向系统加入了正确先验这个信息,肯定会提高系统的性能。
对参数引入高斯正态先验分布相当于L2正则化, 这个大家都熟悉:
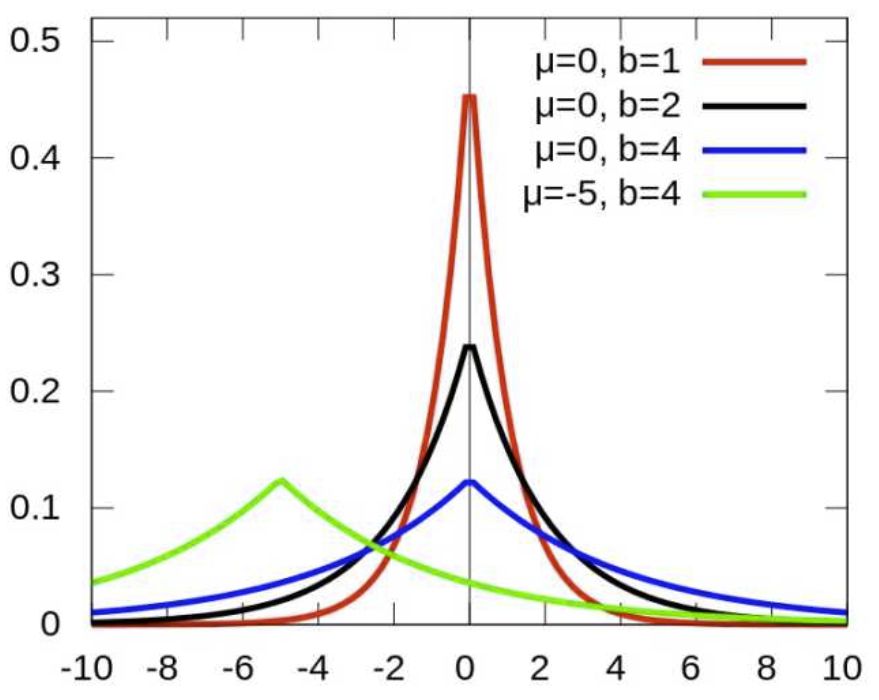
对参数引入拉普拉斯先验等价于 L1正则化, 如下图
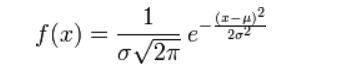
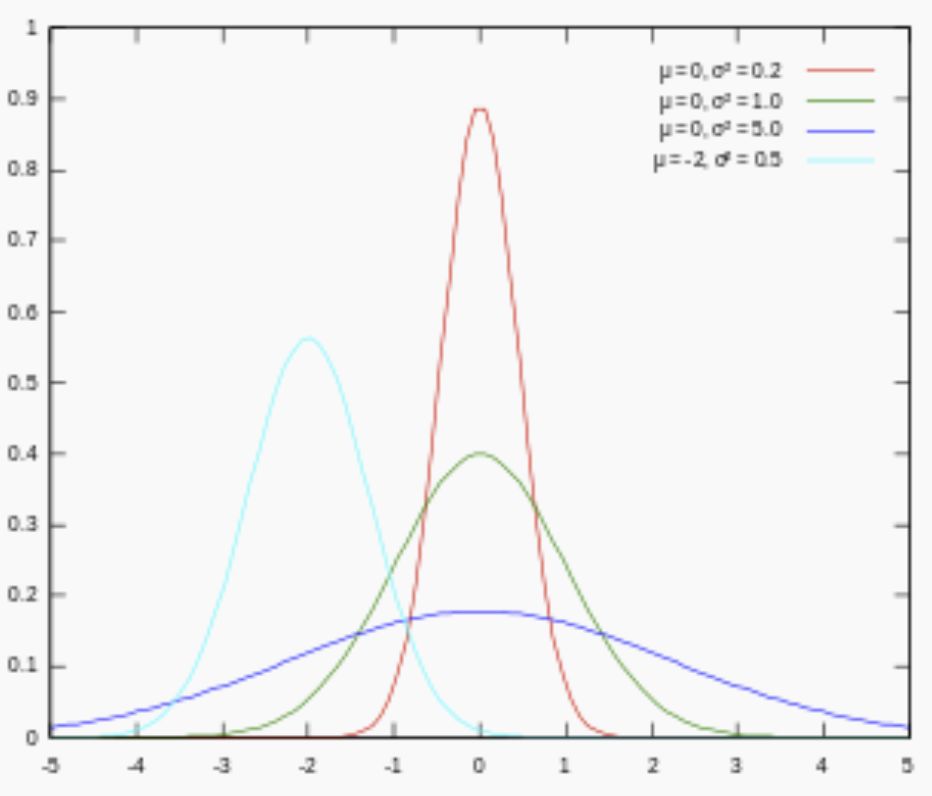
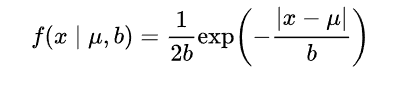
从上面两图可以看出, L2先验趋向零周围, L1先验趋向零本身。
引用自:@AntZ
END

相关课程+免费公开课推荐

火热报名中
原价:18000元
前180人特惠价:15599
且两人及两人以上组团还能各减500元
报名加送18VIP
[包2018全年在线课程和全年GPU]
咨询/报名/组团可添加微信客服
julyedukefu_02
扫码立刻查看详情

后台回复:“公开课” 免费领【近20门免费公开课】



后台回复:“100” 免费领【机器学习面试100题】
后台回复:“干货” 免费领【全体系人工智能学习资料】
后台回复:“领资料” 免费领【NLP工程师必备干货资料】



登录查看更多
相关内容

Arxiv
7+阅读 · 2018年11月4日



相关VIP内容
相关资讯