微软全新视频索引器:机器帮你轻松看懂视频

编者按:如何对海量的视频进行索引标记?微软的研究人员在Azure视频索引器中增加了“多模态主题推断”功能。利用基于监督深度学习的模型,以及无监督的维基百科知识图谱,使得视频索引器可以理解媒体文件中的内部关系,准确高效地提取视频中的关键词,帮助用户更好地挖掘内容的价值。本文编译自Azure博客文章 Multi-modal topic inferencing from videos。

对于拥有大型多媒体资料库的公司或者机构来说,如何能够有效地管理视频并发掘出内容中所蕴含的商业价值是一项极具挑战的工作。如果能够将视频按照主题进行分类,可以让人们更轻松、直观地搜索到所需内容。但是,由于视频中未必会明确地出现该视频的主题,例如有关“医疗保健”主题的视频内容中可能根本不会直白地出现“医疗保健”这四个字,这使得视频分类非常困难。不少机构对此的解决办法就是对内容进行人工标记,但这种做法不但昂贵耗时、容易出错、需要定期维护,而且无法大规模开展。
为了让这个过程变得更加高效和低成本,微软在Azure的视频索引器(Video Indexer)中增加了“多模态主题推断”功能。这项新功能可以借助“跨渠道模型”,将视频中的概念映射到三个不同的本体(ontology)类别(IPTC分类、维基百科分类、视频索引器的阶乘主题本体)上,自动推断视频主题,从而直接索引媒体内容。运行过程中,该模型模拟人类观看视频的行为,通过转录抄本(针对口语词汇)、OCR识别内容(针对视觉文本)、以及视频索引器的名人面部识别模型,基于这三类信息,以不同角度捕捉视频中的语义概念。

图1
Azure视频索引器原有的关键字提取模型对转录抄本和通过OCR识别出的重要词汇进行标记。关键字提取模型和主题推断模型之间的主要区别在于,关键字是视频中明确提及的字眼,而主题则是推断出来的——例如,利用知识图谱将检测到的相似概念聚类在一起,以推断更高层级的隐含概念。
我们以微软Build 2018开发者大会的开场主题演讲为例。在演讲中,微软介绍了许多产品、功能、以及对短期未来的愿景,演讲的主题是如何将AI和机器学习融入云端和边缘设备。整个视频的长度超过三个半小时,如果手动标记需要花费很长时间。但利用视频索引器可以快速地自动产生以下主题词:技术、Web开发、词嵌入、无服务器计算、启动建议和策略、机器学习、大数据、云计算、Visual Studio Code、软件、公司、智能手机、Windows 10、创新和媒体技术。
图3中,通过API获得的JSON格式数据所描述的“科学与技术”等IPTC主题词以及“软件”等维基百科类别主题词,在图2中视频索引器门户页面右侧的Insights标签页中展示。
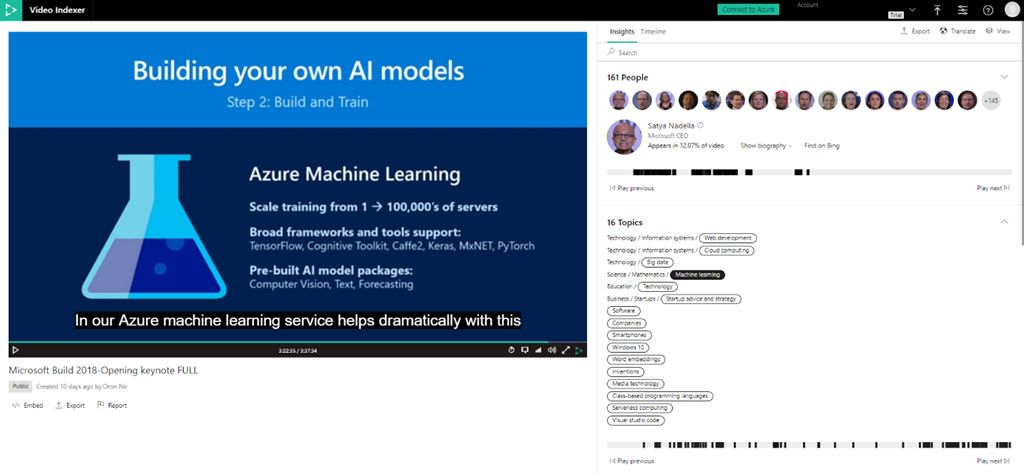
图2

图3
视频索引器内部所用的人工智能模型如图4所示。该图体现了对多媒体文件从上传(图片左侧)到得出洞见(图片最右侧)的整个分析过程。图表下方的视觉频道采用了多种计算机视觉算法、OCR和人脸识别技术。图表上方的音频频道以语言识别和语音-文本转换等基本算法为基础,兼有关键字提取和主题推断等自然语言处理的高级别模型。这张图清晰地展示了视频索引器如何以“搭积木”的方式对多个AI模型进行编排,并根据不同的独立输入信息来推断更高级别的概念。
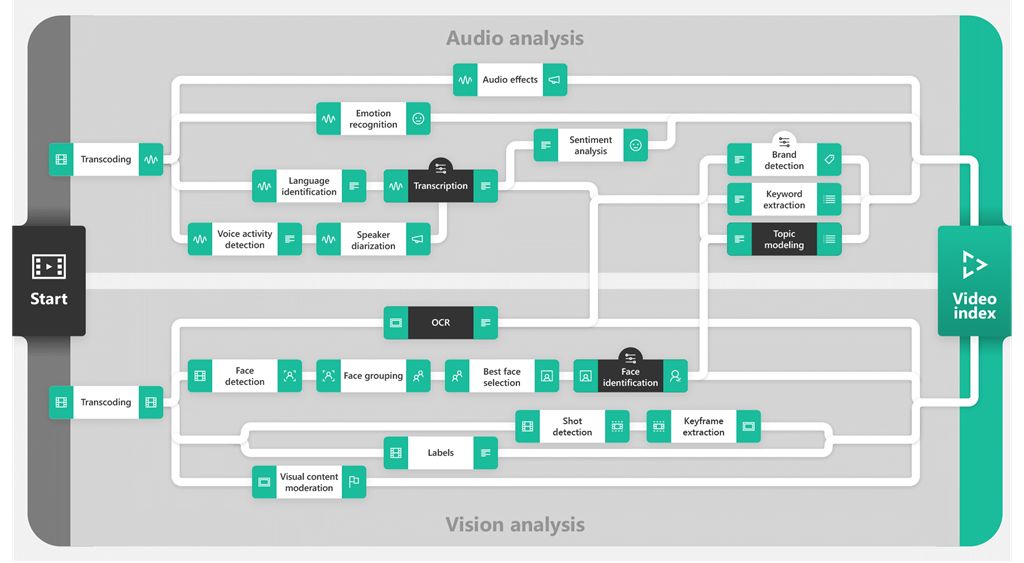
图4
视频索引器利用两个模型来提取主题:第一是深度神经网络,它基于大型专有数据集,直接根据原始文本对主题进行评分和排序。该模型对视频索引器、IPTC和转录抄本进行映射;第二个模型将频谱图算法应用于视频中提及的实体。该算法所采用的输入信号,既包括从视频中识别出的知名人士的维基百科资料等结构化数据,也包括OCR和转录抄本等非结构化数据。
为了提取文本中提及的实体,我们使用了微软亚洲研究院研发的“实体链接智能服务”(Entity Linking Intelligent Service, ELIS)。ELIS能够在自然语言文本中进行指代识别(mention detection),并从超过五百四十万实体的英文维基百科知识库中找出实际对应的实体。不同于其它的命名实体和消歧系统,ELIS会对特定类型的指代和实体进行相应的处理,如弱化“颜色”或者“人”这种普通概念性的实体,以及重点处理某些歧义性较强的指代。同时利用指代消解(coreference resolution)等具体技术,综合不同的上下文表示形式提升系统的可靠性。并且,在需要大量潜在指代信息的任务上,通过大量的工程调优以保证系统准确性。基于此,频谱图算法就可以使用结构化数据来获取主题。
然后,根据不同实体维基百科页面的相似程度构建图表,并将其聚类以捕获视频中的不同概念。最后,在每个聚类选择两个示例,根据维基百科类别成为合格主题词的后验概率,对它们进行排序。流程如图5所示。

图5
视频索引器的主题模型让多媒体用户得以使用直观方法对其内容进行分类,并优化其内容发掘。多模态是识别视频中高阶概念的关键。利用基于有监督深度学习的模型,以及无监督的维基百科知识图谱聚类,视频索引器可以理解媒体文件中的内部关系,进而提供比手动分类更准确、更高效且更便宜的解决方案。
如果你也希望将多媒体内容转换为商业价值,请点击阅读原文,查看视频索引器。
本体
维基百科类别:类别是可被用作主题的标签。这些类别都经过了精心的编辑,共计170万个。作为高度可辨识的本体,这些类别的价值既在于其具体性,又在于它们与文章和其它类别内容之间建立起的类似于知识图谱式的连接。
视频索引器本体:视频索引器本体是一种专有分层本体,具有超过20,000个条目,最大深度为三层。
IPTC:IPTC本体在多媒体公司中很受欢迎。这种分层结构的本体的详细内容可以参考IPTC’s NewsCode。对于来自IPTC第一层的大部分视频索引器本体主题,视频索引器都可以提供IPTC主题。
IPTC’s NewsCode网址:http://show.newscodes.org/
你也许还想看:


感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。