近20年最全目标检测综述
点击蓝字关注我们

扫码关注我们
公众号 : 计算机视觉战队
扫码回复:目标检测,获取源码及论文链接
OBJECT DETECTION IN 20 YEARS
我们将从多个方面回顾对象检测的历史,包括里程碑检测器、目标检测数据集、指标和关键技术的发展。在过去的二十年中,人们普遍认为,目标检测的发展大致经历了两个历史时期:“ 传统的目标检测时期 ” ( 2014年以前 ) 和 “ 基于深度学习的检测时期 ” ( 2014年以后 ),如下图所示。

01
传统检测器
如果我们把今天的物体检测看作是深度学习力量下的一种技术美学,那么回到20年前,我们将见证“冷兵器时代的智慧”。早期的目标检测算法大多是基于手工特征构建的。由于当时缺乏有效的图像表示,人们别无选择,只能设计复杂的特征表示,以及各种加速技术来用尽有限的计算资源。
(1)Viola Jones Detectors
18年前,P. Viola和M. Jones在没有任何约束条件(如肤色分割)的情况下首次实现了人脸的实时检测。在700MHz Pentium III CPU上,在同等的检测精度下,检测器的速度是其他算法的数十倍甚至数百倍。这种检测算法,后来被称为“维奥拉-琼斯”(VJ)检测器”,在此以作者的名字命名,以纪念他们的重大贡献。
VJ检测器采用最直接的检测方法,即,滑动窗口:查看图像中所有可能的位置和比例,看看是否有窗口包含人脸。虽然这似乎是一个非常简单的过程,但它背后的计算远远超出了计算机当时的能力。VJ检测器结合了 “ 积分图像 ”、“ 特征选择 ” 和 “ 检测级联 ” 三种重要技术,大大提高了检测速度。
积分图像:积分图像是一种计算方法,以加快盒滤波或卷积过程。与当时的其他目标检测算法一样,在VJ检测器中使用Haar小波作为图像的特征表示。积分图像使得VJ检测器中每个窗口的计算复杂度与其窗口大小无关。
特征选择:作者没有使用一组手动选择的Haar基过滤器,而是使用Adaboost算法从一组巨大的随机特征池 ( 大约180k维 ) 中选择一组对人脸检测最有帮助的小特征。
检测级联:在VJ检测器中引入了一个多级检测范例 ( 又称“检测级联”,detection cascades ),通过减少对背景窗口的计算,而增加对人脸目标的计算,从而减少了计算开销。
(2)HOG Detector
方向梯度直方图(HOG)特征描述符最初是由N. Dalal和B.Triggs在2005年提出的。HOG可以被认为是对当时的尺度不变特征变换(scale-invariant feature transform)和形状上下文(shape contexts)的重要改进。为了平衡特征不变性 ( 包括平移、尺度、光照等 ) 和非线性 ( 区分不同对象类别 ),将HOG描述符设计为在密集的均匀间隔单元网格上计算,并使用重叠局部对比度归一化 ( 在“块”上 ) 来提高精度。虽然HOG可以用来检测各种对象类,但它的主要动机是行人检测问题。若要检测不同大小的对象,则HOG检测器在保持检测窗口大小不变的情况下,多次对输入图像进行重新标度。多年来,HOG检测器一直是许多目标检测器[13,14,36]和各种计算机视觉应用的重要基础。
(3)Deformable Part-based Model (基于可变形部件的模型,DPM)
DPM作为voco -07、-08、-09检测挑战的优胜者,是传统目标检测方法的巅峰。DPM最初是由P. Felzenszwalb提出的,于2008年作为HOG检测器的扩展,之后R. Girshick进行了各种改进。
DPM遵循“分而治之”的检测思想,训练可以简单地看作是学习一种正确的分解对象的方法,推理可以看作是对不同对象部件的检测的集合。例如,检测“汽车”的问题可以看作是检测它的窗口、车身和车轮。工作的这一部分,也就是“star model”由P.Felzenszwalb等人完成。后来,R. Girshick进一步将star model扩展到 “ 混合模型 ”,以处理更显著变化下的现实世界中的物体。
一个典型的DPM检测器由一个根过滤器(root-filter)和一些零件滤波器(part-filters)组成。该方法不需要手动指定零件滤波器的配置 ( 如尺寸和位置 ),而是在DPM中开发了一种弱监督学习方法,所有零件滤波器的配置都可以作为潜在变量自动学习。R. Girshick将这个过程进一步表述为一个多实例学习的特殊案例,“硬负挖掘”、“边界框回归”、“上下文启动”等重要技术也被用于提高检测精度。为了加快检测速度,Girshick开发了一种技术,将检测模型 “ 编译 ” 成一个更快的模型,实现了级联结构,在不牺牲任何精度的情况下实现了超过10倍的加速度。
02
CNN based Two-stage Detectors
随着手工特征的性能趋于饱和,目标检测在2010年之后达到了一个稳定的水平。R.Girshick说:“ ... progress has been slow during 2010-2012, with small gains obtained by building ensemble systems and employing minor variants of successful methods ”。2012年,卷积神经网络在世界范围内重生。由于深卷积网络能够学习图像的鲁棒性和高层次特征表示,一个自然的问题是我们能否将其应用到目标检测中?R. Girshick等人在2014年率先打破僵局,提出了具有CNN特征的区域(RCNN)用于目标检测。从那时起,目标检测开始以前所未有的速度发展。
在深度学习时代,目标检测可以分为两类:“ two-stage detection ” 和 “ one-stage detection ”,前者将检测框定为一个 “ 从粗到细 ” 的过程,而后者将其定义为 “ 一步完成 ”。
(1)RCNN
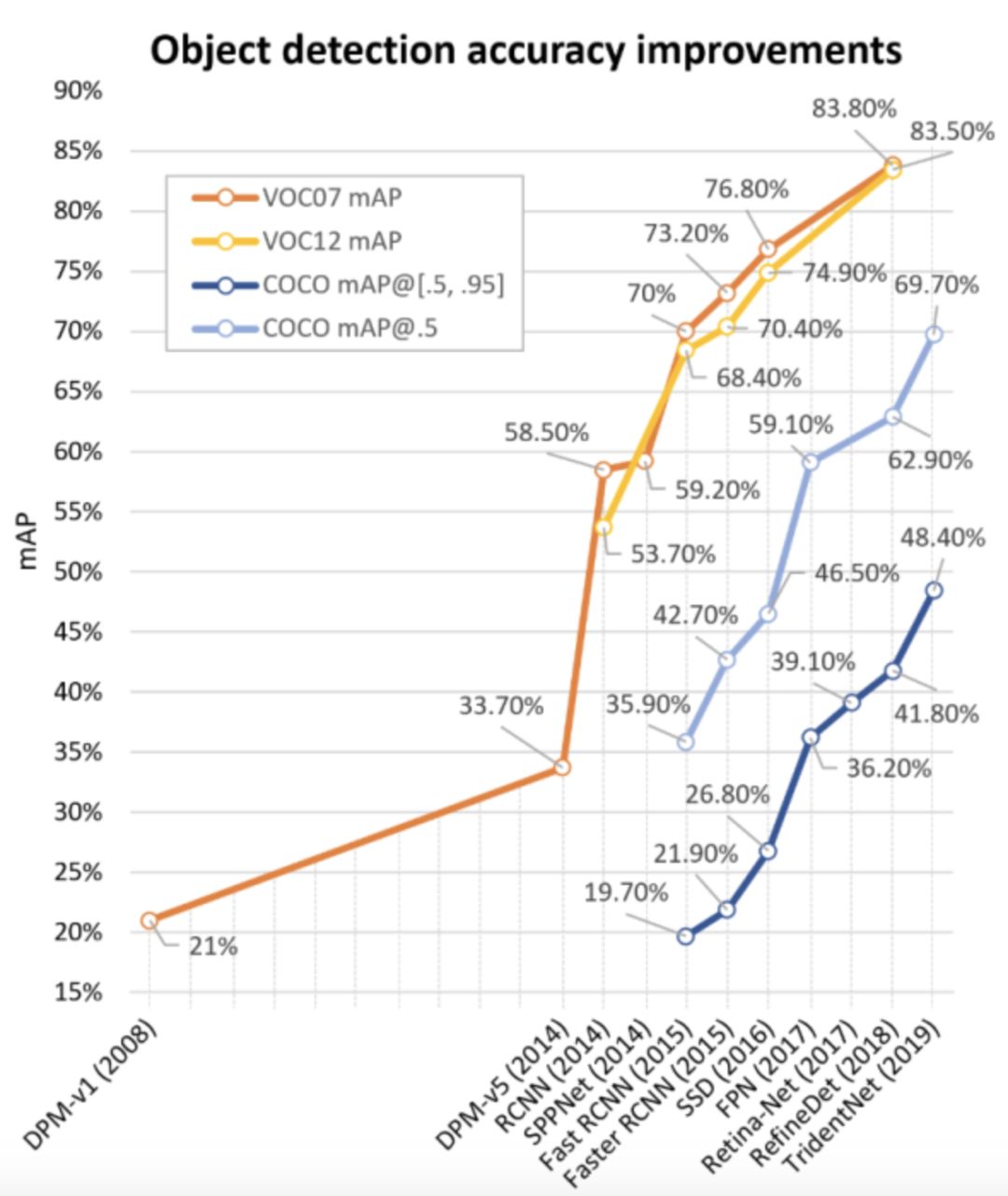
RCNN背后的想法很简单:它首先通过选择性搜索提取一组对象建议(对象候选框)。然后,每个提案都被重新调整成一个固定大小的图像,并输入到一个在ImageNet上训练得到的CNN模型(例如,AlexNet) 来提取特征。最后,利用线性SVM分类器对每个区域内的目标进行预测,识别目标类别。RCNN在VOC07上产生了显著的性能提升,平均平均精度(mean Average Precision,mAP)从33.7%(DPM-v5) 大幅提高到58.5%。
虽然RCNN已经取得了很大的进步,但它的缺点是显而易见的:在大量重叠的提案上进行冗余的特征计算 ( 一张图片超过2000个框 ),导致检测速度极慢(GPU下每张图片14秒)。同年晚些时候,SPPNet被提出并克服了这个问题。
(2)SPPNet
2014年,K. He等人提出了空间金字塔池化网络( Spatial Pyramid Pooling Networks,SPPNet)。以前的CNN模型需要固定大小的输入,例如,AlexNet需要224x224图像。SPPNet的主要贡献是引入了空间金字塔池化(SPP)层,它使CNN能够生成固定长度的表示,而不需要重新缩放图像/感兴趣区域的大小。利用SPPNet进行目标检测时,只对整个图像进行一次特征映射计算,然后生成任意区域的定长表示,训练检测器,避免了卷积特征的重复计算。SPPNet的速度是R-CNN的20多倍,并且没有牺牲任何检测精度(VOC07 mAP=59.2%)。
SPPNet虽然有效地提高了检测速度,但仍然存在一些不足:第一,训练仍然是多阶段的,第二,SPPNet只对其全连接层进行微调,而忽略了之前的所有层。次年晚些时候,Fast RCNN被提出并解决了这些问题。
(3)Fast RCNN
2015年,R. Girshick提出了Fast RCNN检测器,这是对R-CNN和SPPNet的进一步改进。Fast RCNN使我们能够在相同的网络配置下同时训练检测器和边界框回归器。在VOC07数据集上,Fast RCNN将mAP从58.5%( RCNN)提高到70.0%,检测速度是R-CNN的200多倍。
虽然Fast-RCNN成功地融合了R-CNN和SPPNet的优点,但其检测速度仍然受到提案/建议检测的限制。然后,一个问题自然而然地出现了:“ 我们能用CNN模型生成对象建议吗? ” 稍后,Faster R-CNN解决了这个问题。
(4)Faster RCNN
2015年,S. Ren等人提出了Faster RCNN检测器,在Fast RCNN之后不久。Faster RCNN 是第一个端到端的,也是第一个接近实时的深度学习检测器(COCO mAP@.5=42.7%,COCO mAP@[.5,.95]=21.9%, VOC07 mAP=73.2%,VOC12 mAP=70.4%,17fps with ZFNet)。Faster RCNN的主要贡献是引入了区域建议网络 (RPN),使几乎cost-free的区域建议成为可能。从RCNN到Faster RCNN,一个目标检测系统中的大部分独立块,如提案检测、特征提取、边界框回归等,都已经逐渐集成到一个统一的端到端学习框架中。
虽然Faster RCNN突破了Fast RCNN的速度瓶颈,但是在后续的检测阶段仍然存在计算冗余。后来提出了多种改进方案,包括RFCN和 Light head RCNN。
(5)Feature Pyramid Networks(FPN)
2017年,T.-Y.Lin等人基于Faster RCNN提出了特征金字塔网络(FPN)。在FPN之前,大多数基于深度学习的检测器只在网络的顶层进行检测。虽然CNN较深层的特征有利于分类识别,但不利于对象的定位。为此,开发了具有横向连接的自顶向下体系结构,用于在所有级别构建高级语义。由于CNN通过它的正向传播,自然形成了一个特征金字塔,FPN在检测各种尺度的目标方面显示出了巨大的进步。在基础的Faster RCNN系统中使用FPN,在MSCOCO数据集上实现了最先进的单模型检测结果,没有任何附加条件(COCO mAP@.5=59.1%,COCO mAP@[.5,.95]= 36.2%)。FPN现在已经成为许多最新探测器的基本组成部分。
03
CNN based One-stage Detectors
(1)You Only Look Once (YOLO)
YOLO由R. Joseph等人于2015年提出。它是深度学习时代[20]的第一个单级检测器。YOLO非常快:YOLO的一个快速版本运行速度为155fps, VOC07 mAP=52.7%,而它的增强版本运行速度为45fps, VOC07 mAP=63.4%, VOC12 mAP=57.9%。YOLO是 “ You Only Look Once ” 的缩写。从它的名字可以看出,作者完全抛弃了之前的 “ 提案检测+验证 ” 的检测范式。相反,它遵循一个完全不同的哲学:将单个神经网络应用于整个图像。该网络将图像分割成多个区域,同时预测每个区域的边界框和概率。后来R. Joseph在 YOLO 的基础上进行了一系列改进,提出了其 v2 和 v3 版本,在保持很高检测速度的同时进一步提高了检测精度。
尽管与两级探测器相比,它的探测速度有了很大的提高,但是YOLO的定位精度有所下降,特别是对于一些小目标。YOLO的后续版本和后者提出的SSD更关注这个问题。
(2)Single Shot MultiBox Detector (SSD)
SSD由W. Liu等人于2015年提出。这是深度学习时代的第二款单级探测器。SSD的主要贡献是引入了多参考和多分辨率检测技术,这大大提高了单级检测器的检测精度,特别是对于一些小目标。SSD在检测速度和准确度上都有优势(VOC07 mAP=76.8%,VOC12 mAP=74.9%, COCO mAP@.5=46.5%,mAP@[.5,.95]=26.8%,快速版本运行速度为59fps) 。SSD与以往任何检测器的主要区别在于,前者在网络的不同层检测不同尺度的对象,而后者仅在其顶层运行检测。
(3)RetinaNet
单级检测器速度快、结构简单,但多年来一直落后于两级检测器的精度。T.-Y.Lin等人发现了背后的原因,并在2017年提出了RetinaNet。他们声称,在密集探测器训练过程中所遇到的极端的前景-背景阶层不平衡(the extreme foreground-background class imbalance)是主要原因。为此,在RetinaNet中引入了一个新的损失函数 “ 焦损失(focal loss)”,通过对标准交叉熵损失的重构,使检测器在训练过程中更加关注难分类的样本。焦损耗使得单级检测器在保持很高的检测速度的同时,可以达到与两级检测器相当的精度。(COCO mAP@.5=59.1%,mAP@[.5, .95]=39.1% )。
04
Object Detection Datasets
建立具有更少的偏置的更大的数据集,是开发先进的计算机视觉算法的关键。在目标检测方面,在过去10年中,已经发布了许多著名的数据集和基准测试,包括PASCAL VOC挑战的数据集(例如,VOC2007, VOC2012)、ImageNet大尺度视觉识别挑战(例如,ILSVRC2014)、MS-COCO检测挑战等。下表1给出了这些数据集的统计数据。
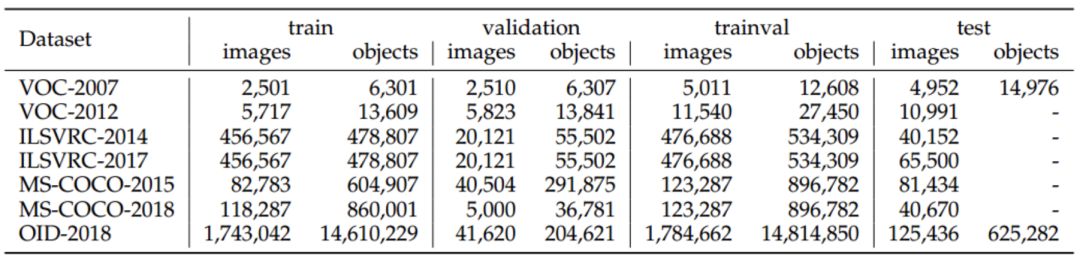
(a)VOC,(b)ILSVRC,(c)COCO,(d)Open Images
下图显示了从2008年到2018年对VOC07、VOC12和MS-COCO数据集检测精度的提高。
具体介绍如下:
(1)Pascal VOC
PASCAL可视化对象类(Visual Object Classes,VOC)挑战(2005-2012)是早期计算机视觉界最重要的比赛之一。PASCAL VOC中包含多种任务,包括图像分类、目标检测、语义分割和动作检测。两种版本的Pascal-VOC主要用于对象检测:VOC07和VOC12,前者由5k tr. images + 12k annotated objects组成,后者由11k tr. images + 27k annotated objects组成。这两个数据集中注释了生活中常见的20类对象(Person: person; Animal: bird, cat, cow, dog, horse, sheep; Vehicle: aeroplane, bicycle, boat, bus, car, motor-bike, train; Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor)。近年来,随着ILSVRC、MS-COCO等大型数据集的发布,VOC逐渐淡出人们的视野,成为大多数新型检测器的试验台。
(2)ILSVRC
ImageNet大规模视觉识别挑战(Large Scale Visual Recognition Challenge,ILSVRC)推动了通用目标检测技术的发展。ILSVRC从2010年到2017年每年举办一次。它包含一个使用ImageNet图像的检测挑战。ILSVRC检测数据集包含200类视觉对象。它的图像/对象实例的数量比VOC大两个数量级。例如ILSVRC-14包含517k图像和534k带注释的对象。
(3)MS-COCO
MS-COCO是目前最具挑战性的目标检测数据集。自2015年以来一直保持一年一度的基于MS-COCO数据集的比赛。它的对象类别比ILSVRC少,但是对象实例多。例如,MS-COCO-17包含来自80个类别的164k图像和897k带注释的对象。与VOC和ILSVRC相比,MS-COCO最大的进步是除了边框标注外,每个对象都进一步使用实例分割进行标记,以帮助精确定位。此外,MS-COCO包含更多的小对象 ( 其面积小于图像的1% ) 和比VOC和ILSVRC更密集的定位对象。所有这些特性使得MSCOCO中的对象分布更接近真实世界。就像当时的ImageNet一样,MS-COCO已经成为对象检测社区的实际标准。
(4)Open Images
继MS-COCO之后,开放图像检测(OID)技术在2018年迎来了前所未有的挑战。在开放图像中有两个任务:1) 标准目标检测,2) 视觉关系检测,检测特定关系中成对的目标。对于目标检测任务,数据集由1,910k张图像和15,440k个带注释的边界框组成,这些边界框位于600个对象类别上。
05
Datasets of Other Detection Tasks
在过去的20年里,除了一般的目标检测外,在行人检测、人脸检测、文本检测、交通标志/灯光检测、遥感目标检测等特定领域的检测应用也十分繁荣。下面一系列表列出了这些检测任务的一些流行数据集。有关这些任务的检测方法的详细介绍可在后期分享中找到。
pedestrian detection

face detection

text detection

traffic light and sign

remote sensing target detection

06
Object DetectionMetrics
我们如何评估目标探测器的有效性? 这个问题甚至可能在不同的时间有不同的答案。
在早期的检测社区中,对于检测性能的评价标准并没有得到广泛的认可。例如,在行人检测的早期研究中,“每个窗口的漏报率与误报率(FPPW)” 通常用作度量。然而,逐窗测量(FPPW)可能存在缺陷,在某些情况下无法预测的完整图像特性。2009年,加州理工学院(Caltech)建立了行人检测基准,从那时起,评估指标从每窗口(per-window,FPPW)改为每图像的伪阳性(false positive per-image,FPPI)。
近年来,对目标检测最常用的评估方法是 “ 平均精度(AP) ”,该方法最早是在VOC2007中引入的。AP定义为不同召回情况下的平均检测精度,通常以类别特定的方式进行评估。为了比较所有对象类别的性能,通常使用所有对象类别的平均AP(mAP)作为性能的最终度量。为了测量目标定位精度,使用Union上的交集(Intersection over Union,IoU)来检查预测框和地面真实框之间的IoU是否大于预定义的阈值,比如0.5。如果是,则将该对象标识为 “ 成功检测到 ”,否则将标识为 “ 未检测到 ”。因此,基于mAP的0.5 -IoU多年来已成为用于目标检测问题的实际度量。
2014年以后,由于MS-COCO数据集的普及,研究人员开始更加关注边界框位置的准确性。MS-COCO AP没有使用固定的IoU阈值,而是在多个IoU阈值上取平均值,阈值介于0.5(粗定位)和0.95(完美定 )之间。这种度量的变化鼓励了更精确的对象定位,并且对于一些实际应用可能非常重要 ( 例如,假设有一个机器人手臂试图抓住扳手 )。
近年来,对开放图像数据集的评价有了进一步的发展,如考虑了组框(group-of boxes)和非穷举的图像级类别层次结构。一些研究者也提出了一些替代指标,如 “ 定位回忆精度 ”。尽管最近发生了一些变化,基于VOC/COCO的mAP仍然是最常用的目标检测评估指标。




