DeepMind发布难度更大的机器阅读理解数据集NarrativeQA(附论文)
与通常的信息检索相反,让机器学会做阅读理解(reading comprehension)需要整合整篇文档中所有的事件信息、人物关系。问题回答(question answering)通常用于评估机器或者儿童学习时的阅读理解能力。然而,现有的阅读理解(RC)数据集和相关任务中的大部分问题都可以通过很表面的信息解答,在阅读理解中却没有深层次、本质上的问题。
近日,DeepMind研究者提出了一种新的、难度更大的数据集NarrativeQA,读者必须阅读整本书或整个剧本才能回答有关故事的问题,也就是说必须彻底理解了故事内容后,才有可能成功回答深层次的问题。最后的结果表明,虽然人类能很容易地回答问题,但RC模型却面临很多挑战。在对话页面回复“qa”即可获取PDF版论文。

其他模型回顾
在NarrativeQA之前,也有很多用于训练阅读理解模型的数据集,例如MCTest、CNN/Daliy Mail、CBT、BookTest、SQuAD、NewsQA、MS MARCO以及SearchQA等。下表就展示了这几种数据集的基本情况和主要特点。
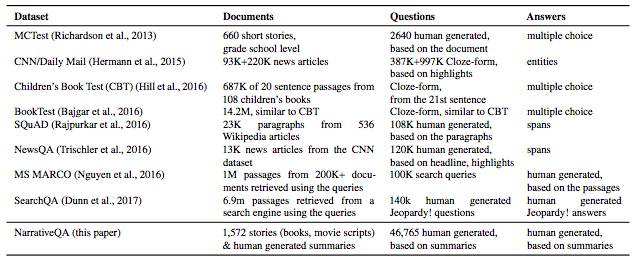
但是,这些数据集都存在着几个共同的问题:例如有些数据集很小或者不太自然(比如MCTest);在一些更自然的文本中,大多数问题的答案只在一个句子中就能找到;问题的答案趋向于利用源于局部上下文和问题本身的表示的跨距选取(这是问题在架构上的肤浅性的进一步证据)。
NarrativeQA:一个新的数据集
在发现了上述几种数据集的局限性后,研究人员决定建立一个新的数据集,对于这个新数据集,他们同样有几点要求:
希望该数据集基于大量的支持文档或少量的大型文档之上,以确保神经网络模型能在词嵌入上进行训练,同时还能覆盖大量词汇;
研究人员希望注释者(annotators)能用自己的话写出答案,能把握人物、地点、事件之间更高层次的关系,而不是简单的复制原文;
研究人员还将评估模型生成答案时是否流畅、是否正确,同时还要评估备选答案的干扰程度是否达标;
评估问答题的范围和复杂程度,这也是当前所有QA模型的共同难题。
数据收集方法
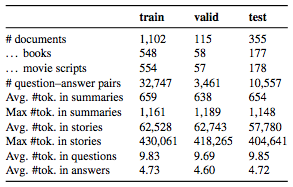
研究人员从Gutenberg网站上搜集了一些书籍,从其他网站搜集了电影剧本,最终汇集了1567个故事。与其他数据集相比,这个数据集里的样本比较少,但是每篇文档都很长,这就保证了用词的多样性。
然后,研究人员将其放到亚马逊的Mechanical Turk平台上,让注释者根据每篇故事的摘要,设计10个问题并写出答案,注意,这里的注释者没有看过完整的故事,他们只是根据给出的摘要设计问题。
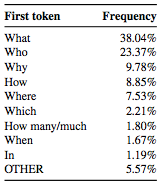
问题开头第一个最常见的token
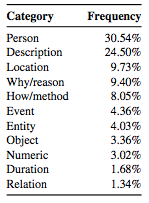
300个样本中的问题类型
最终,数据集中共有46765个问答题,每个摘要大约对应30个问答题。每个问题的平均token长度是9.8,大多数都以“WH-”开头。而答案的长度较短,平均为4.73个token。
实验过程
研究人员将模型应用于两个任务,一个是阅读摘要,另一个是阅读整个故事。
首先,阅读摘要与之前的阅读理解任务相似,其问题是根据上下文构建的。但是,有关故事情节的摘要往往包含更复杂的时间线和更多的人物。在这个意义上,阅读有情节的摘要往往要比维基百科的新闻文章或段落摘要难一些。结果如下:
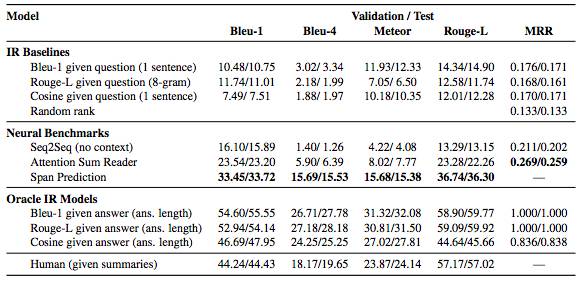
分数越高越好
神经跨度模型明显优于其他方法,然而与人类和数据集相比还有一定差距。
另外,阅读整篇故事后所得结果如下:
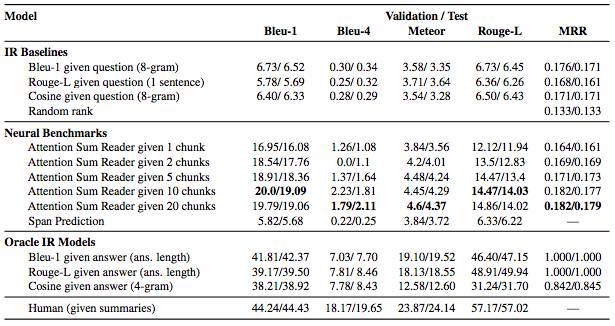
结果与人类的表现差距较大,这也表明该项目的目标,即创建对人类来说是现实、直接的数据库,是成功的。但是这对于当前的阅读理解模型来说却非常困难。
结语
新构建的NarrativeQA模型是在现有数据集和任务的局限性上建立起来的,虽然相较以往有了提高,但是又暴露出了新的问题:难以理解小说,与新闻相比,小说的人物、事件和关系更丰富。
在经过分析和评估后,研究人员希望这一研究方向能够缩小现有模型和人类水平之间的差距。他们希望这一数据集不仅能为机器阅读服务,而是成为新型神经模型发展的动力。






