Ross、何恺明等人提出PointRend:渲染思路做图像分割,显著提升Mask R-CNN性能
机器之心报道
参与:魔王、一鸣
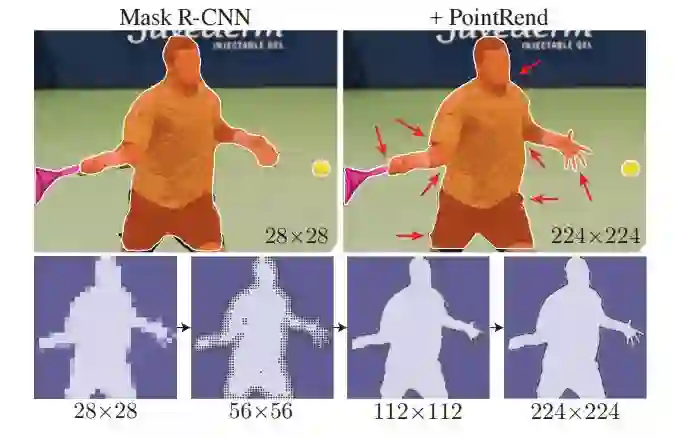
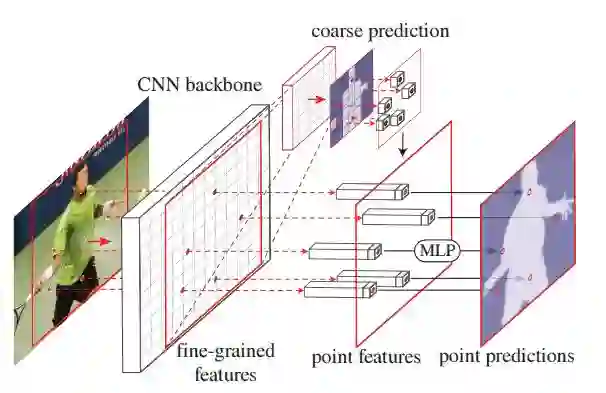
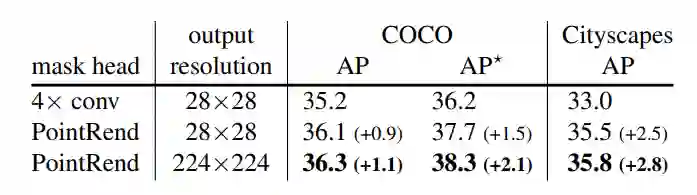
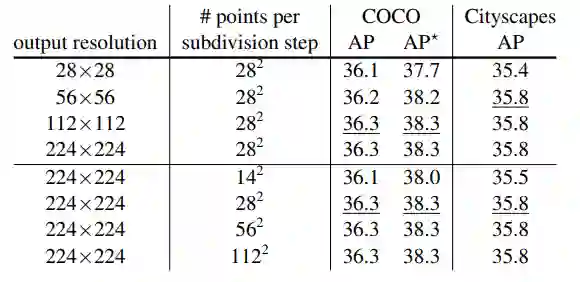
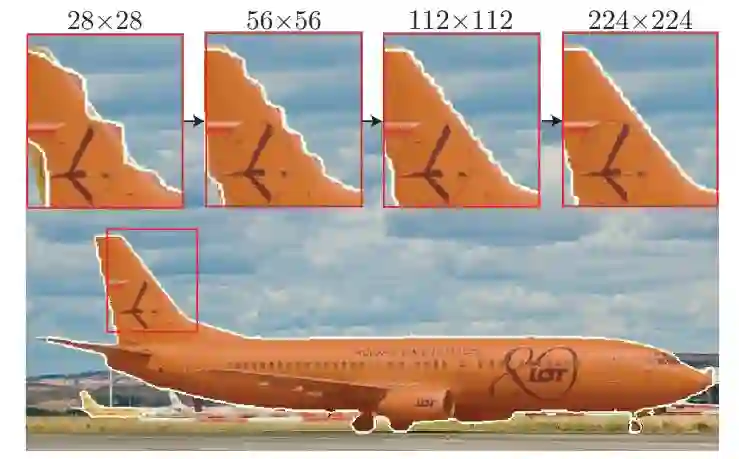
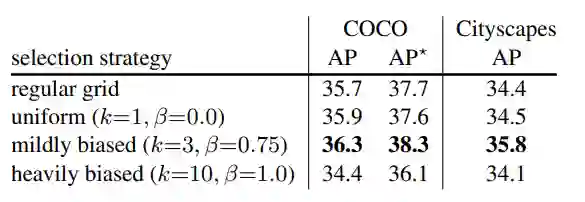
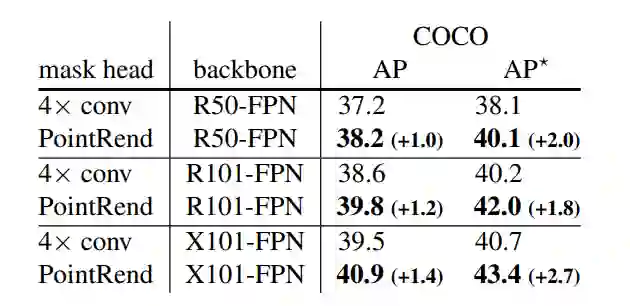
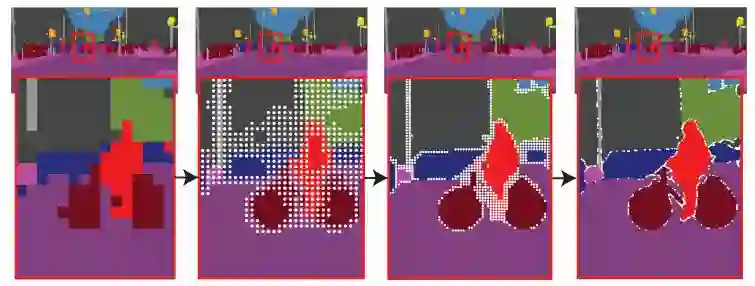
Facebook FAIR 实验室再次创新图像分割算法,这回使用的是图像渲染的思路。算法可作为神经网络模块集成,显著提升 Mask R-CNN 和 DeepLabV3 性能。








点击阅读原文报名参与。
登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文