薪资不逊NLP算法岗, 边缘AI火了!
众所周知深度神经网络模型被广泛应用在图像分类、物体检测,目标跟踪等计算机视觉任务中,并取得了巨大成功。
然而随着时代发展,人们更加关注深度神经网络的实际应用性能,人工智能技术的一个趋势是在边缘端平台上部署高性能的神经网络模型,并能在真实场景中实时(>30帧)运行。
如移动端/嵌入式设备,这些平台的特点是内存资源少,处理器性能不高,功耗受限,这使得目前精度最高的模型根本无法在这些平台进行部署和达到实时运行。

随着网络深度的不断提升,网络模型性能的确是提高了,但是这些网络往往计算量巨大,依赖这些基础网络的检测算法很难达到实时运行的要求,尤其是在 ARM、FPGA以及 ASIC 等计算力有限的移动端硬件平台。
逐渐呈现了一种在移动设备平台上“算不好”,穿戴设备上“算不了”,数据中心“算不起”的无奈场面,如下图所示,因此如何将物体检测算法加速到满足工业应用要求,一直是关键性问题。
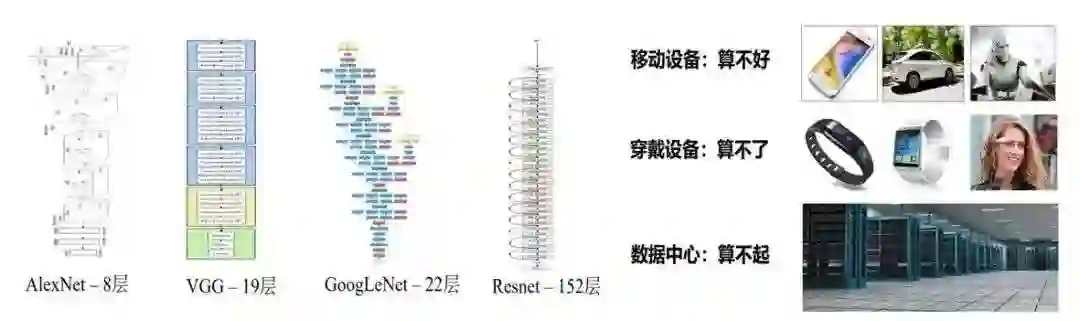
如何保持模型精度基础上近一步减少模型参数量和复杂度,逐渐成为一个研究热点。
为了全面系统的培养高性能神经网络人才,贪心学院重磅推出《高性能神经网络与AI芯片应用研修课程》,为想进入边缘AI行业的同学们提供一个可以大幅提升自身就业竞争力的选择。
本课程会讲解边缘AI相关知识、高性能网络设计、通用芯片及专用芯片计算加速方法等专业技能,并结合优秀编译器的架构和实现细节的讲解,为学生构建高性能AI算法的软硬件视角,能够解决应用落地时神经网络的优化和部署相关问题。
本计划申请制,择优录取,每月仅限20人;申请者提交简历通过审核后,可以进入项目。



对申请人的要求:
1
统招一本以上学历;
2
算法在职工程师或想要在边缘计算行业求职的同学;
3
计划未来6-12个月内挑战高薪边缘AI算法岗位;
01 适合人群
大学生
• 编程及深度学习基础良好,为了想进入边缘AI行业发展
在职人士
• 想进入边缘AI行业的算法或IT工程师
• 想通过掌握硬件技术,拓宽未来职业路径的AI算法工程师
入学基础要求
• 掌握python、C++开发,及深度学习的基础知识。
02 你将收获
• 掌握最前沿的边缘AI算法技术,顺利敲开边缘AI行业求职大门;
• 掌握神经网络高性能实现的算法及工具;
• 掌握通用芯片及专用AI芯片架构及网络加速技术;
• 掌握通用芯片及专用AI芯片神经网络部署应用的实际案例;
• 短期内对边缘AI技术有全面深入认知,大大节省学习时间;
• 进入边缘AI算法圈子,认识一群拥有同样兴趣的人。
03 内容亮点
• 全面技术讲解:课程涵盖了轻量化神经网络设计、神经网络部署前的优化方法、神经网络编译器的设计模式和具体实现、神经网络部署到芯片上的计算加速等全面的AI嵌入式芯片设计和应用相关人员就业必备的知识。

• 软硬件相结合:本课程除了全面讲解高性能神经网络相关的知识技术外,还会指导学员在硬件上进行实操。课程使用EAIDK310和嘉楠勘智K210开发板作为教学材料。

• 专家导师授课:课程导师为AI芯片行业专家,相关项目经验十分丰富。
04 课程研发及导师团队
王欢
主讲老师
• 肇观科技算法总监
• 华中科技大学模式识别与人工智能硕士
• 原拼多多、同盾科技等公司算法工程师,AI算法领域从业15+年
Jerry Yuan
课程研发顾问
美国微软(总部)推荐系统部负责人
美国亚马逊(总部)资深工程师
• 美国新泽西理工大学博士
• 14年人工智能, 数字图像处理和推荐系统领域研究和项目经验
• 先后在AI相关国际会议上发表20篇以上论文
李文哲
贪心科技CEO
美国南加州大学博士
• 曾任独角兽金科集团首席数据科学家、美国亚马逊和高盛的高级工程师
• 金融行业开创知识图谱做大数据反欺诈的第一人
• 先后在AAAI、KDD、AISTATS、CHI等国际会议上发表过15篇以上论文
韩老师
助教老师
浙江大学博士
• 曾在阿里巴巴浙江大学前沿技术研究中心做视觉算法实习
• 曾多次获得数字系统设计大赛FPGA低功耗AI赛道、研究生创“芯”大赛等相关竞赛奖项
05 授课方式
• 基础知识讲解
• 前沿论文解读
• 论文代码复现
• 该知识内容的实际应用
• 该知识的项目实战
• 该方向的知识延伸及未来趋势讲解
06 项目介绍
项目1
项目名称:模型轻量化
项目内容描述:mobilenet、shufflenet、squeezenet等,模型量化、剪枝和蒸馏技术,网络的计算量和内存分析的工具,主干网络的轻量化,检测网络的轻量化,分割网络的轻量化,不同框架提供的加速方案。
项目使用的数据集:COCO,ADE20k,ImageNet
项目使用的算法:模型量化,模型剪枝和模型蒸馏
项目使用的工具:python,c/c++,pytorch,tensorflow,distiller,ncnn
项目预期结果:学员掌握轻量化网络设计准则,模型轻量化技术,能够上手操作一 个网络部署前的优化。
项目对应第几周的课程:1~4周
项目2
项目名称:神经网络编译器
项目内容描述:tvm,ncnn,mnn,tnn 各自的特点,对于神经网络的优化方案,tvm的具体设备的优化方案,算子融合,路径优化,内存优化,ncnn的网络的表示数据结构,ncnn的一些优化计算的思路,量化方法,mnn中的数据结构,模型转换和量化方法,tnn和ncnn的区别,系统架构,量化方法。
项目使用的算法:离线量化,在线感知量化
项目使用的工具:python,c/c++,tvm,ncnn,tnn,mnn
项目预期结果:学员对于神经网络编译器有全面的了解,对于主流神经网络编译器能够实践使用,完成模型到芯片所需要格式的转换。
项目对应第几周的课程:5~8周
项目3
项目名称:通用芯片加速技术
项目内容描述:cpu,arm对应的指令集级别的加速,编译器中具体的优化策略,simd,avx,sse,openblas,neon和cpu中对于卷积的运算加速方案,cpu上的具体实例,arm上的具体实例,环境配置,神经网络的例子,加速方案的组合和实际效果。
项目使用的算法:simd,avs,sse,blas,winograd
项目使用的工具:nnpack,qnnpack,lowpgemm,tvm,ncnn
项目预期结果:学员深入掌握cpu,arm等芯片的神经网络加速技术,并且通过一个例子来看具体的加速效果 。
项目对应第几周的课程:9~12周
项目4
项目名称:专用芯片加速技术
项目内容描述:gpu和k210 npu及各自神经网络编译器中的加速优化技术,gpu上的cuda加速的方法,cublas,opencl,vulkan的开发例子,nncase上编译一个网络,k210开发板环境配置及人脸检测模型的部署
项目使用的算法:人脸检测
项目使用的工具(编程语言、工具、技术等):Python,C/C++,opencl,vulkan,nncase
项目预期结果:学员可以掌握gpu及npu上神经网络的编译加速,并且通过一个具体的例子来完成人脸检测模型在k210芯片上的部署 。
项目对应第几周的课程:13~16周
07 详细内容介绍
第一周:轻量化网络结构设计
本节课将讲解网络参数量、浮点运算数等模型评价指标、工具,以及分类网络, 检测网络,分割网络的轻量化设计。
课程提纲:
• 轻量化网络设计背景介绍
• 网络的计算量和内存分析工具
• 主干网络的轻量化
• 检测网络的轻量化
• 分割网络的轻量化
• 典型网络的设计思路
第二周:知识蒸馏优化、低秩分解优化
本节课将讲解神经网络知识蒸馏优化、神经网络计算低秩分解加速计算方法。
课程提纲:
• 知识蒸馏方法介绍
• 知识蒸馏原理和步骤介绍
• 知识蒸馏训练方法缩减网络的实际分类网络演示
• 低秩分解原理
• 低秩分解加速计算在神经网络推理中的应用
第三周:网络剪枝
本节课将讲解网络稀疏性原理,网络剪枝原则及剪枝的常见方法。
课程提纲:
• 网络剪枝的原理
• 常用的剪枝策略
• 神经网络框架中的剪枝功能介绍
• 剪枝的实际使用
第四周:网络量化
本节课将讲解网络的低比特化,以及在AI芯片中的计算,实现网络量化的离线和在线感知的量化方法。
课程提纲:
• 网络量化的技术发展
• 不同离线量化算法的实现原理
• 神经网络框架中在线感知量化算法的原理及实现
实际案例
第五周:神经网络编译器简介
本节课将讲解tvm、ncnn、tnn、mnn的简要对比,tvm relay和网络转换,网络的编译优化和推理加速。
课程提纲:
• tvm、ncnn、tnn、mnn的简要对比
• tvm relay和网络转换
• 网络的编译优化和推理加速
• tvm的实际案例
第六周:ncnn
本节课将讲解ncnn的系统架构图,数据结构,支持的框架,网络的表示,网络优化,量化,以及各平台的优化策略。
课程提纲:
• ncnn的系统架构图
• ncnn的数据结构及支持框架
• ncnn的网络表示
• ncnn网络优化,量化,及各平台的优化策略
第七周:tnn
本节课将讲解tnn的系统架构图,数据结构,支持的框架,网络的表示,网络优化,量化,以及各平台的优化策略。
课程提纲:
• tnn的系统架构图
• tnn的数据结构及支持框架
• tnn的网络表示
• tnn网络优化,量化,及各平台的优化策略
第八周:mnn
本节课将讲解mnn的系统架构图,数据结构,支持的框架,网络的表示,网络优化,量化,以及各平台的优化策略。
课程提纲:
• mnn的系统架构图
• mnn的数据结构及支持框架
• mnn的网络表示
• mnn网络优化,量化,及各平台的优化策略
第九周:cpu中的指令集优化
本节课将讲解cpu中的指令集优化,simd、avx、sse方法,及tvm中对于cpu上神经网络加速的位置。
课程提纲:
• cpu中的指令集优化:simd,avx,sse方法
• tvm中对于cpu上神经网络加速的位置
第十周:arm中的神经网络加速
本节课将讲解arm中的neon优化,及ncnn,tnn和mnn的实现,并结合实际例子来看具体的加速效果。
课程提纲:
• arm中的neon优化
• ncnn,tnn和mnn实现的讲解
• 具体加速效果的实际案例
第十一周:卷积计算的优化算法
本节课将讲解卷积计算的优化算法,包括winograd等。
第十二周:神经网络加速库
本节课将讲解openblas库的优化,nnpack/qnnpack的优化,及lowpgemm。
课程提纲:
• openblas库的优化
• nnpack/qnnpack的优化
• lowpgemm
第十三周:gpu上神经网络的运行和加速
本节课将讲解gpu与cpu计算加速的区别,英伟达gpu的原生cuda加速方法,及推理侧tensorrt的使用。
课程提纲:
• gpu与cpu计算加速的区别
• 英伟达gpu的原生cuda加速方法
• 推理侧tensorrt的使用
第十四周:gpu加速通用加速库
本节课将讲解通用加速库cublas,vulkan,opencl的使用。
课程提纲:
• 通用加速库cublas的使用
• Vulkan的使用
• opencl的使用
第十五周:dsp,fpga,npu专用加速计算
本节课将讲解dsp,fpga,npu的专用加速计算。
课程提纲:
• dsp计算加速
• fpga计算加速
• npu专用加速计算
第十六周:npu使用
本节课将以嘉楠科技的k210为例,实现一个人脸检测案例。
课程提纲:
• 嘉楠科技k210芯片介绍
• nncase人脸检测案例
关于我们:一切从信任开始
我们专注人工智能人才培养4年,在AI领域,国内属于最头部的人才培养黄埔院校。在AI人才培养上,已跟京东、腾讯等大厂一直建立良好的战略合作关系,学员也来自斯坦福、伯克利、清华、北大等世界级名校。

△点击logo△
职场成功案例
姓名:李**
学校专业:燕山大学 控制工程专业 2019级硕士毕业生
原工作单位:软通动力 算法工程师 年薪20万
跳槽方向:嵌入式算法工程师
匹配方案:技术研修+求职面试一篮子服务
最终跳槽公司:荣耀 年薪45万
学习服务时长:7个月
姓名:Jerry Zhao
学校专业:澳大利亚国立大学 计算机专业 2018级本科毕业生
原工作单位:鲁班软件 初级算法工程师 年薪18万
跳槽方向:ML算法工程师
匹配方案:技术研修+案例项目学习+求职面试一篮子服务
最终跳槽公司:网易 年薪40万
学习服务时长:4个月
姓名:钱**
学校专业:中国农业大学 计算机科学与技术 2018级本科毕业生
原工作单位:聚美国际 算法工程师 年薪22万
跳槽方向:算法工程师
匹配方案:技术研修+求职面试一篮子服务
最终跳槽公司:亚马逊电商 年薪47万
学习服务时长:11个月
姓名:蔡*
学校专业:中科院自动化所 智能控制与计算智能 2020级博士毕业生
原工作单位:中国科学院自动化研究所-智能系统与工程研究中心-实习 年薪5万
跳槽方向:边缘计算算法工程师
匹配方案:背景提升+求职面试一篮子服务
最终跳槽公司:比亚迪 年薪38万
学习服务时长:3个月
历届学员去向


