图森技术汇 | 聊聊Anchor的"前世今生"(上)

本文转自图森未来首席科学家王乃岩,感兴趣的同学可以移步首席的知乎号交流@Naiyan Wang
正如大家所见,最近一段时间各种所谓anchor-free的detection算法得到了很多的关注,我其实是一个非常不愿意蹭热点的人,技术上的东西更愿意“让子弹飞一会”,再发表看法。所以今天在这里,我们先来谈谈各种对于anchor based detection方法中anchor设置的改进。在正式开始介绍这些改进之前,先先来介绍一些我理解的anchor,以及它在detection系统中发挥的作用。
首先,我想说的第一个观点是绝大多数top-down detector都是在做某种意义上的refinement和cascade。区别无外乎在于,refine的次数以及每次refine的方法。在传统方法中从无论sliding window出发,不断去筛选正样本;还是后续使用Selective search或者Edgebox直接生成proposal都是基于这样的思路。后续基于Deep learning的方法也没有走出这个套路,在one stage算法中,主流的方法便是在refine预先指定的anchor;在two stage算法中,试图使用RPN来替代sliding window或者其他生成proposal的方法,再通过提取的region feature来refine这些proposal。
anchor这个概念最早出现在Faster RCNN的paper中,如果能理解前面提到的内容,其实anchor就是在这个cascade过程中的起点。由于在Faster RCNN那个年代还没有FPN这种显式处理scale variation的办法,anchor的一大作用便是显式枚举出不同的scale和aspect ratio。原因也很简单,只使用一个scale的feature map和同一组weight,要去预测出所有scale和aspect ratio的目标,本身就是很困难的一件事。通过anchor的引入,将scale和aspect ratio进行划分,针对某个特定的区间和组合,使用一组特定学习到的weight去处理,从而缓解这个问题。需要注意的是,anchor本身并不会参与到网络的运算中去,影响的只会是classification和bbox regression分支的target(训练阶段)和怎样decode box(测试阶段)。换句话说,网络其实预测的是相对于anchor的offset,只有在最终从offset转换到bbox时,才会使用。这样的想法也很自然被各种One stage方法所吸收,形成了anchor已经是detection标配的stereotype。说了这么多为什么现在anchor free的方法又卷土重来了呢?这个问题我会在下一篇文章中讲讲我个人的看法,下面言归正传,我们来看看这些尝试去学习和优化anchor的方法都具体做了什么。
在这几篇文章中,想法最为直接的是[1],想要解决的问题也最为简单,就是在一个dataset上,我怎么选择anchor shape。注意,在这个工作中区别于后续几个工作,学习出来的anchor是在整个dataset上共享的。一般而言,对于anchor shape的设定,除了手工拍拍脑袋随意设置几个scale和aspect ratio之外,对于ground-truth bbox进行一次聚类也是一个常用的方法。在[1]中,作者就是希望减少这部分hand-crafted的工作(虽然还是使用了kmeans作为初始化...)。具体做法也是非常地直接和直观,由于anchor shape在One stage方法中只影响bbox regression分支,我们可以在bbox regression的loss中,把anchor也作为一个优化的变量,求导优化。具体细节就不再赘述,有兴趣的读者可以参照原文。另外一些同时期的工作,在这个基础上更进一步,希望能够得到每张图,甚至是对于feature map上每个位置上都有不同的adaptive anchor,也可以针对不同的dataset泛化性能更强。MetaAnchor[2]算是在这个方向是最早的一个尝试。MetaAnchor希望从一些预设定的anchor出发,有可能再结合上图像本身的feature,生成一组新的anchor weight。如下图所示:
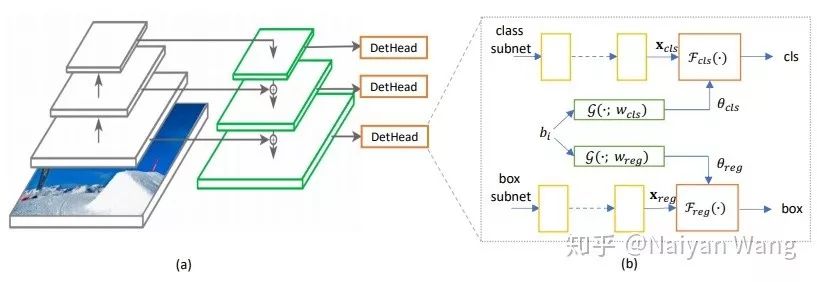
注意,在这里其实生成的并不是refine过的anchor本身,而是直接用于classification和bbox regression分支的weight。这也就是为什么这个工作叫做MetaAnchor的原因,因为这个思想其实源自于meta learning。具体实现上,生成函数G的选取就直接选择为两层的MLP,分别有依赖于图像自身的feature和不依赖于图像自身的feature的两种形式,即:
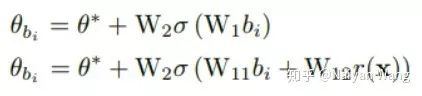
其中theta*为所有anchor共享的weight。b_i为anchor box自身的表示,作者在文中直接选择了normalized过的长和宽这两维作为anchor的feature。x很直接,即为这个feature map对应位置上的feature。回到上面整体的观点上看,MetaAnchor其实是implicit地多做了一次refinement,只不过不是explicit地生成了新的anchor,而是直接生成了对应的weight。下一个要介绍的工作[3]虽然介绍的motivation看上去和anchor本身无关,但实际的做法也算是某种refinement。在这里,我来讲一讲我自己的看法,而不再重复paper中讲的故事,有兴趣的读者可以直接参阅作者本人的解读:https://zhuanlan.zhihu.com/p/55416312。个人理解,这篇工作其实最想做的是在One stage的框架内,实现了一个两级的Cascade refinement。但是由于不像two stage的方法,可以通过region features来直接align anchor和提取出的feature,作者在文中尝试了下图(b)(c)(d)三种实现方式,测试得到的最终结果类似,便使用了最直接的办法:两个stage共享同一个head,使用一样的feature,直接去做两次预测。如下图。
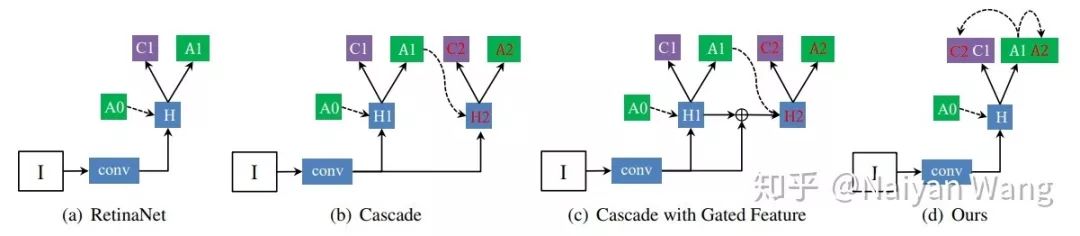
其中和原始的RetinaNet的区别在于,在分类和回归的两支上,分别加入对第一次refine之后的新anchor设置新的training target:

在分类的分支上,可以认为同样的一个预测(注意两个term里都是c_i)有两个监督信号,一个是原始anchor对应的label,一个是第一次refine过后的anchor对应的label。在回归分支上略有区别的是这两次refinement对应的regression weight不等,也就是两个term中一个是t_i^0,一个是t_i^1。个人觉得最起码回归这个branch的方法更合理一些,在这个分类branch中两个输入都不变,在cascade不同层之间只是变化anchor,也就是训练的target,这看上去是一个比较wired的方案。不过,作者在实验中也证明了,哪怕只训练refine之后的label,仍然可以得到可观的性能提升。最后一个要介绍的工作Guided Anchor算是我个人觉得在这几篇工作中完成度最高的一篇。同样,作者本人也有自己介绍过这个工作:https://zhuanlan.zhihu.com/p/55854246
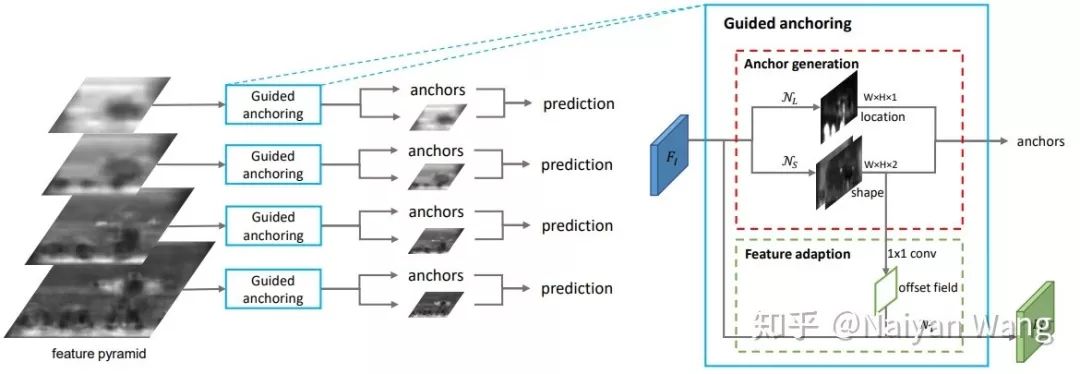
整个方法分为两个大的部分,第一部分是Anchor generation,这个部分并没有太多特别的地方,可以认为是一个特殊的RPN,分别预测这个位置是否存在物体,和以这个位置为中心的anchor的长和宽。和RPN的区别在于,没有中心点的回归,关于为什么这么做,作者自己在上面知乎专栏中已有回复。第二部分是Feature adaptation,个人觉得这是一个非常重要的模块,试图解决one stage中一个核心的问题:anchor和其对应的feature怎样align?这里作者的方案是Feature adaptation模块。作者使用生成的anchor的shape来预测给Deformable Conv使用的offset,这样可以使用deformable conv来aggregate anchor内的feature,可以算是某种简化版本的region feature。通过这个办法,使得最终预测的feature map和实际的anchor scale相关。
另外这篇文章中,比较有意思的一点是探究了对于two stage的方法,怎样使用更好的proposal?也就是说怎样把proposal中更高的recall转换成最终detection结果中的precision。这里作者给出了一些经验:1) 使用更少的proposal训练。 2) 使用更高的正样本IoU threshold。简单来说,在recall更高的时候,我们应该让后续的任务变得更“简单”和“专注”一些,这样避免一些困难样本对detection head的影响。虽然没有特别深入探究这个现象的原因,但这个发现也是很有指导意义的。
总结一下,除了第一篇工作以外,我们都可以从一个统一的视角下来理解这个事情:1) 用尽量低的代价,在one stage detector或者是two stage生成proposal的过程中引入一次额外的refinement,anchor其实只是refine这件事情的一个载体。2) 在detection的head上,有两个输入,即输入的feature和对应的网络weight,决定一个输出,即前面提到的和anchor相关的分类和回归目标,即变化了anchor其实变化的话head的输出。后三篇文章中,都变化了输出,但是对于输入的处理不同:MetaAnchor中变化的是weight,GuidedAnchor中,通过feature adaptation变化了输入的feature,Consistent optimization中全部固定。希望讲了这么多,能够帮助大家更好地理解这一系列的工作。下一篇当然是会来讲讲最近火爆的Anchor free方法啦,敬请期待!
[1] Zhong, Y., Wang, J., Peng, J., & Zhang, L. (2018). Anchor Box Optimization for Object Detection. arXiv preprint arXiv:1812.00469.
[2] Yang, T., Zhang, X., Li, Z., Zhang, W., & Sun, J. (2018). Metaanchor: Learning to detect objects with customized anchors. In NIPS2018.
[3] Kong, T., Sun, F., Liu, H., Jiang, Y., & Shi, J. (2019). Consistent Optimization for Single-Shot Object Detection. arXiv preprint arXiv:1901.06563.
[4] Wang, J., Chen, K., Yang, S., Loy, C. C., & Lin, D. (2019). Region proposal by guided anchoring. In CVPR2019.




