腾讯新研究:看血条就能检测、识别王者荣耀里的英雄
选自arXiv
《王者荣耀》是一款拥有众多玩家和观众的手游,如何针对这些人群进行游戏视频的自动个性化推荐非常关键。准确的推荐会极大地激发用户的兴趣并提升游戏体验。而在内容理解和个性化推荐中,为内容打上标签又是关键的一环。要解决这个问题,首先要识别出游戏中的英雄。为此,腾讯的研究者提出了一种利用血条进行英雄检测和识别的简便方法。
论文地址:https://arxiv.org/pdf/1907.07854.pdf
两步走的《王者荣耀》英雄检测和识别
基于神经网络的图像目标检测和识别领域有两种流行的算法。一种是两步(two-stage)算法,即先检测出图像中的目标,为每个检测到的目标画出边界框,然后再识别每个边界框并对其中的目标进行分类。RNN、SPP Net、Fast R-CNN、Mask R-CNN 等是这种算法的代表。另一种是一步(one-stage)算法,即检测、识别一步到位,如 SSD、YOLO 等。
在仔细观看了《王者荣耀》的游戏视频后,腾讯研究人员发现了王者荣耀英雄的一些共同特征:无论属于哪个阵营,这些英雄的上方都有一个血条,显示其生命值。虽然不同英雄的血条大小、形状相同,但颜色、生命值和等级有所差别,这就为英雄的检测提供了一种简单的方法。
在本文中,研究者采用的是两步算法:
第一步:基于模板匹配的方法检测出游戏视频帧中所有英雄的血条,得到一系列边界框;
第二步:训练一个深度卷积神经网络来识别每个边界框,得到英雄的名字。
为什么要用两步算法
之所以采用两步的算法是因为每个英雄的血条具有固定的大小和形状。因此,采用这种算法能够高效、准确地检测出英雄。同时,识别阶段也会从准确的检测结果中受益。因此,在这一特定任务中,两步算法的效果要优于一步算法。
此外,做出这种选择还有一个原因:研究者拥有一组仅标注了自己英雄的游戏视频。因此,用于训练分类器的训练和测试样本可以使用检测算法进行自动标注,方法是限制视频帧中心附近的检测区域并将血条颜色限定为绿色。然而,对于主流的神经网络一步目标检测算法来说,手动标注每个英雄的位置和名字则非常困难。如果仅自动标注始终位于视频帧中心的英雄,则训练好的神经网络往往会记住自己英雄的位置,对其他英雄(队友和敌人)的检测结果会很差。
第一步:检测
血条模板匹配
英雄检测采用的方法是利用一个预定义的模板对英雄血条进行匹配。由于不同血条的生命值、颜色、等级不同,因此必须利用掩码图像,来表示用于或不用于匹配的区域。图 1 为血条模板图像及其对应的掩码图像。(b 中白色表示可用于匹配的像素,黑色表示不用于匹配的像素。)

对于 3 通道的输入视频帧,研究者首先将其转换为灰度图,并在灰度图上执行模板匹配。匹配后的图像是一个 32 位浮点图像,每个像素表示输入图像与模板在该位置的匹配程度。研究者试图检测出一个视频帧中的所有英雄,但每个帧中的英雄数量是不确定的。因此,他们无法在匹配图像上应用一个固定的阈值,也无法将匹配的值进行排序并挑出前几个值。为了解决这个问题,他们对原始视频帧和对应的匹配图像进行了观察,如图 2 所示:

图 2:原始视频帧及其对应的匹配图像。
从图 2 可以发现,对于每个血条,匹配图像的相应位置都有一个局部极大值。也就是说,在匹配图像中,每个亮像素的周围都围绕着几个暗像素组成的图案,如图 2(b) 红框区域所示。图 2(a) 中有 4 个血条,图 2(b) 中的对应位置有相应的四个图案。如此看来,只要找到匹配图像中的这些局部极大值,我们就能检测出血条。
研究者在这些匹配图像上使用具有适当半径的最大值滤波器(maximum filter)。图 2(c) 为最大值滤波器处理之后的图像。显然,四个局部极大值的位置对应四个血条。
研究者对匹配图像和最大值图像进行逐像素对比。两幅图像相同位置的像素值相等表示局部极大像素。用这种方法得到的局部极大像素多达数百个,但我们知道,一幅图像中至多有 10 个英雄,因此没有必要处理那么多。所以研究者将这些局部极大像素进行降序排列,只取其中的前 20 个进行处理。实验结果表明,这种做法几乎能保留所有血条,且检测速度大大提高。
找出前 20 位的局部极大像素后,研究者设计了一个函数来计算每个局部极大像素的得分:
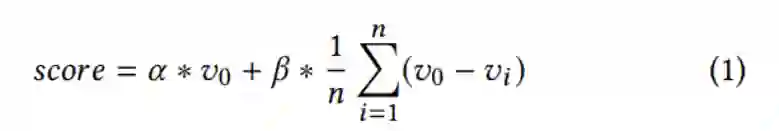
得分越高,模板匹配结果越好。研究者同样对这 20 个得分进行降序排列(为后续的非极大值抑制做准备)。由于不知道视频帧中的英雄数量,研究者仍然需要一个阈值来确定英雄的数量。固定阈值适用于一个视频中的不同帧,也适用于不同视频中的帧。图 2(a) 的血条检测结果如图 3 所示,所有的血条都被正确地检测出来。
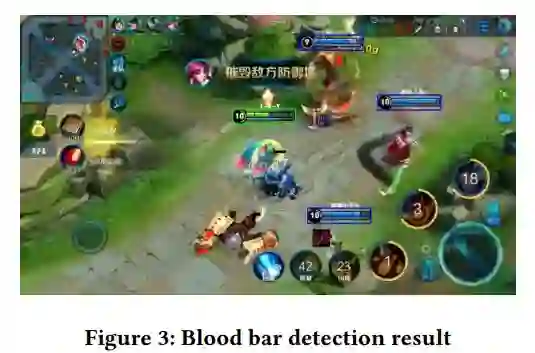
非极大值抑制
在这个游戏中,英雄的血条形状接近矩形,包含几条长水平线(如图 1 所示)。因此,在模板匹配步骤中,如果模板沿图像真实血条方向水平移动,则匹配结果不会大幅下降。因此,在真实血条周围通常会有多个检测结果,如图 4(a) 所示。

图 4(a):非极大值抑制之前的检测结果。
为了避免一个血条出现多个检测结果,研究者引入了非极大值抑制。在模板匹配阶段,研究者已经得到了得分排名前 20 的像素,而且已经对其做了降序排列。每个像素用 4 个属性 (x, y, score, is_real_detection) 进行描述。在非极大值抑制阶段,研究者设计了抑制算法,如下所示:

图 4(b) 展示了非极大值抑制之后的检测结果,所有错误的检测结果都已被移除。

图 4(b):非极大值抑制之后的检测结果。
英雄的阵营分类
通过估计血条的颜色可以将英雄分为三个阵营:自身、队友和敌人。研究者采用一种简单的算法,利用血条最左边位置的平均颜色对血条进行分类。
英雄阵营的分类结果可以在图 3 和图 9 中看到。图 5 展示了游戏商店界面的阵营分类。
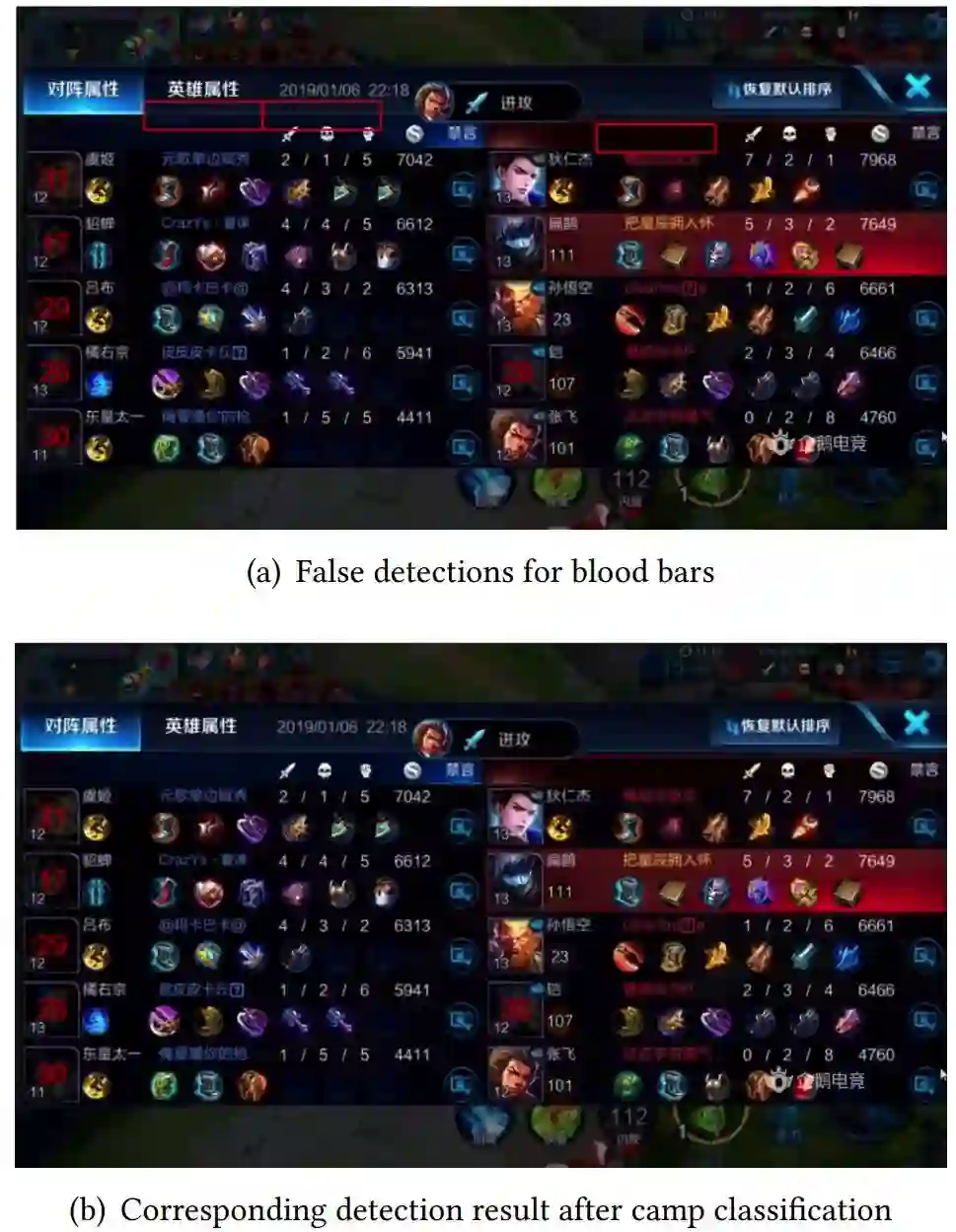
图 5:商店界面的英雄阵营分类。
第二步:识别
训练和测试样本
为了识别出游戏视频中的英雄,研究者训练了若干个分类器,他们使用血条检测算法收集训练和测试样本。
图 6 展示了用于训练分类器的典型训练和测试样本:

用于英雄识别的分类器
如上所述,研究者利用检测算法自动收集了训练和测试样本。对于每一个分类器,研究者收集了超过 10 万个样本。训练和测试样本的数量如表 1 所示。
研究者利用三个流行的深度卷积神经网络(Inception V3/V4 和 Inception-ResNet V2)训练分类器。Inception 网络采用一种并行降维方法,减小特征图大小和需要学习的参数。
英雄检测和识别完整方案
下图 7 展示了英雄检测和识别的完整方案。研究者在输入视频帧上运行英雄检测算法,检测出图像中的所有英雄。对于主英雄(leading/self hero),研究者将剪裁好的外观、技能区域和第一个技能区域图像分别发送到三个训练好的分类器中。最终的识别结果基于三个分类器的标签和置信度得分总和。对于其他英雄,由于没有可用的技能区域,如果置信度得分高于阈值,则识别结果为外观分类器的标签。

图 7:英雄检测和识别的完整方案。
实验结果
研究者利用平均准确率、marco-f1 和 micro-f1 作为三种样本和三种网络模型的评估标准。训练好的神经网络的性能如表 2 所示:
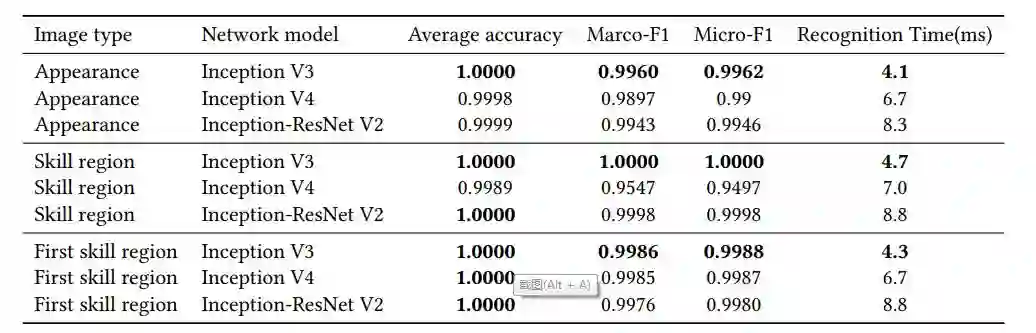
表 2:神经网络在测试集上的性能。
从表 2 可以看出,对于所有类型的图像,Inception V3 网络的性能都优于 Inception V4 和 Inception-ResNet V2,因为 Inception V3 网络足以处理这些人工合成的图像。
研究者还将该方法与 YOLOv3 进行了对比,如下图 8 所示:
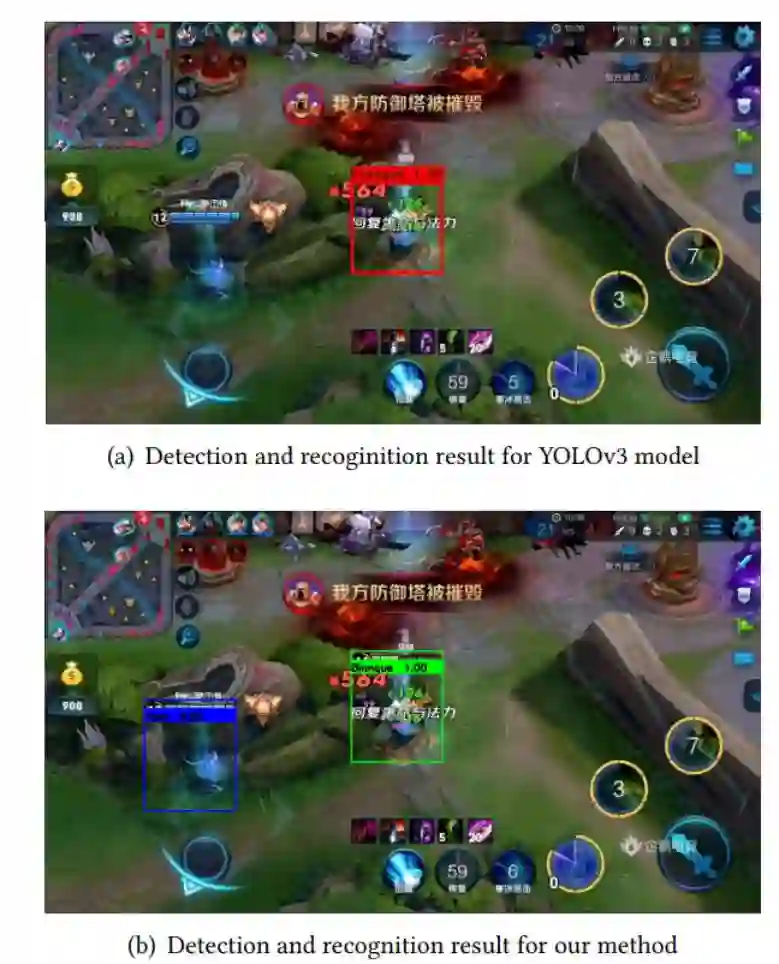
图 8:YOLOv3 和本文方法的比较。
如上所述,YOLOv3 模型倾向于只检测图像中心周围的英雄,其他位置的英雄则选择忽略,因为训练集中的主角都在图像中心位置附近。但本文提出的方法可以检测到画面中所有的英雄,如图 8(b) 所示。
方法局限
尽管本文提出的方法在实验中表现良好,但在某些情况下,该识别方法也会失败。其中最典型的就是无法识别出没有出现在训练集中的新皮肤(如图 9 所示)。而且,随着游戏版本的更新,英雄的数量也会增加。因此,模型还有待更新。
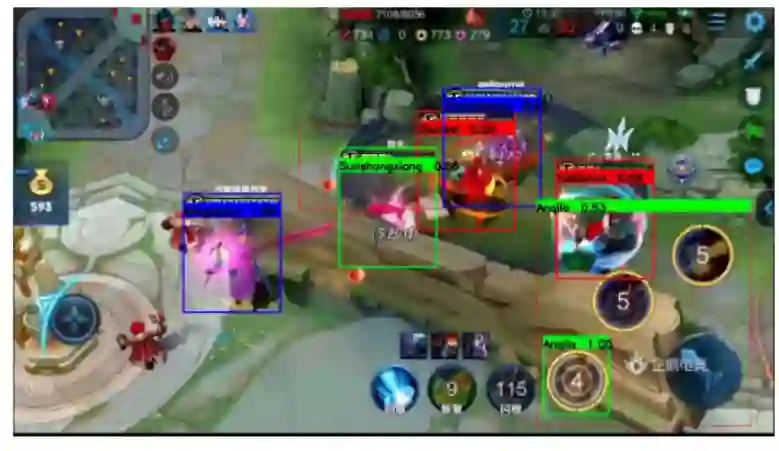
图 9:英雄外观识别的典型错误。