学界 | 搜索一次就够了:中科院&图森提出通过稀疏优化进行一次神经架构搜索
选自 arXiv
作者:Xinbang Zhang, Zehao Huang, Naiyan Wang
机器之心编译
参与:李诗萌、张倩
近年来,神经架构搜索(NAS)引起了学界和业界的极大兴趣,但由于其搜索空间巨大且不连续,该方法仍具挑战性。本文提出了直接稀疏优化 NAS(DSO-NAS)方法。在 DSO-NAS 中,作者为 NAS 问题提供了一个新的模型修剪视角,总结出了有效且理论上合理的优化方法来解决这个问题。这种方法的优点是可微分、效率高,可以直接应用在 ImageNet 这样的大数据集上。在 CIFAR-10 数据集上,DSO-NAS 的平均测试误差只有 2.84%。DSO-NAS 用 8 个 GPU 在 18 个小时内以 600M FLOPs 在 ImageNet 数据集上得到的测试误差为 25.4%。该论文提交到了 ICLR 2019。
1.引言
毫无疑问,深度神经网络(DNN)近年来一直是 AI 复兴的引擎。早在 2012 年,基于 DNN 的方法就刷新了许多 AI 应用的记录,比如图像分类(Krizhevsky et al. (2012); Szegedy et al. (2015); He et al. (2016))、语音识别(Hinton et al. (2012); Graves et al. (2013))和围棋(Silver et al. (2016; 2017))。考虑到深度学习惊人的表征能力,DNN 已经将这些应用的范式从手动设计特征和分段流程转向端到端学习。尽管 DNN 已经将研究人员从特征工程(feature engineering)中解放出来,但另一件乏味的工作——「网络工程」出现了。多数情况下要根据特定任务设计神经网络,然后进入无穷尽的超参数调整和尝试。因此,设计合适的神经网络架构仍然需要大量专业知识和经验。
为了使技术更亲民,研究者们提出了神经架构搜索(NAS),或者更广泛的说法是 AutoML。NAS 主要有两个流派:第一个是遵循 Zoph&Le(2017)的开创性工作,他们提出了一种训练循环神经网络(RNN)控制器的强化学习算法,这个控制器可以生成编码架构(Zoph et al. (2018); Pham et al. (2018))。第二个是进化算法,它可以迭代地评估并提出新的评估模型(Real et al. (2017); Stanley & Miikkulainen (2002))。尽管这些模型的性能令人印象深刻,但对于像 ImageNet 这样的大数据集来说,它们的搜索过程非常耗费资源,而且很不实用。尽管已经提出了一些加速方法(Zhong et al. (2018); Pham et al. (2018))。近期,DARTS(Liu et al. (2018b))提出了一种基于梯度的方法,它通过 softmax 分类器选择连接。尽管 DARTS 在提升了速度的情况下还实现了良好性能,但与之前的工作一样,它的搜索空间仍局限于长度固定的编码和共享块的搜索。
本文从另一个角度解决这些问题。我们重新设计了 NAS,使它可以删除大型网络的无用连接。这种大型网络包含完整的网络架构假设空间,因此只要训练和评估一个单独的模型。由于在训练过程中直接优化了网络结构,所以我们的方法叫做直接稀疏优化 NAS(DSONAS)。我们还进一步证明,相对于低效的强化学习或革命性搜索,这种稀疏正则化问题可以通过改进的加速近端梯度方法得到有效优化。值得注意的是,DSO-NAS 比现有的搜索方法都更简单,因为它将神经网络权重学习和架构搜索结合到一个单优化问题中。DSO-NAS 不需要任何控制器(Zoph & Le (2017); Zoph et al. (2018); Pham et al. (2018))、性能预测器(Liu et al. (2018a))或搜索空间松弛化(Zoph & Le (2017); Zoph et al. (2018); Pham et al. (2018); Liu et al. (2018b))。由于其高效性和简单性,DSO-NAS 首次证明了 NAS 可以在不共享模块结构的情况下,直接用在像 ImageNet 这样的大数据集上。我们的实验表明,DSO-NAS 在 CIFAR-10 上的平均测试误差为 2.84%,而用 600M FLOPs 在 ImageNet 上得到了 25.4% 的 top-1 误差。
总而言之,我们的贡献总结如下:
我们提出了一个新模型,该模型基于稀疏优化,可以为神经架构搜索进行修剪。在搜索过程中只需训练一个模型
我们提出了一种理论上合理的优化方法来有效地解决这个具有挑战性的优化问题。
我们论证了我们提出的方法的结果极具竞争力,或者说它比其他 NAS 方法都更好,同时它还显著简化和加速了搜索过程。
论文:You Only Search Once: Single Shot Neural Architecture Search via Direct Sparse Optimization

论文链接:https://arxiv.org/abs/1811.01567
摘要:近年来,神经架构搜索(NAS)引起了学界和业界的极大兴趣,但由于其搜索空间巨大且不连续,该方法仍具挑战性。与以往应用进化算法和强化学习的方法不同,本文提出了直接稀疏优化 NAS(DSO-NAS)方法。在 DSO-NAS 中,我们为 NAS 问题提供了一个新的模型修剪视角。具体而言,我们从一个完全连接的模块开始,引入缩放因子来缩放运算之间的信息流。接着,我们强行加上了稀疏正则化来删除架构中无用的连接。最后,我们总结出了有效且理论上合理的优化方法来解决这个问题。这种方法具有可微分和高效率的优点,可以直接应用在像 ImageNet 这样的大数据集上。特别是在 CIFAR-10 数据集上,DSO-NAS 的平均测试误差只有 2.84%,而 DSO-NAS 用 8 个 GPU 在 18 个小时内以 600M FLOPs 在 ImageNet 数据集上得到的测试误差为 25.4%。
动机
DSO-NAS 的思想主要遵循的是可以用完全连接的有向无环图(DAG)表示神经网络(或其中的微小结构)的架构空间。在这个空间中的任何其他架构都可以用其子图表示。换句话说,可以从完整的图中选择边和节点的子集来获得特定的架构。之前的工作(Zoph & Le (2017), Liu et al. (2018a), Liu et al. (2018b))关注点主要在搜索拥有两类块的架构,分别是卷积块和 reduction 块。根据微小结构搜索的思想,我们用完整的图表示一个单独的块的搜索空间。然后可以用一堆有残差连接的模块表示最终的网络架构。图 1 所示是指定块的 DAG 示例,它的节点和边分别表示局部运算 O 和信息流。
对于一个有 T 个节点的 DAG 来说,可以用局部运算 O(i)转化所有前驱节点(h(j),j<i)输出的和来计算第 i 个节点 h(i)的输出,也就是说:
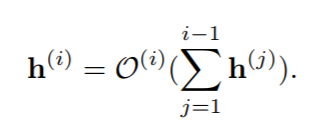
然后就可以将架构搜索问题转变成边缘删除问题。在搜索过程中,我们删除了完整 DAG 中无用的边和节点,留下了最重要的结构。为了实现这个目标,我们在每一条边上用缩放因子来缩放每个节点的输出。可以将等式 1 修改为:
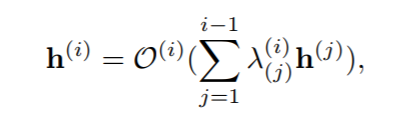
式中 λ(i)(j)是用在从节点 j 到 i 的信息流上的缩放因子。然后我们在缩放参数上用稀疏正则化在搜索时强制将部分因子变成 0。直观地说,如果 λ(i)(j)是 0,因为它没有任何贡献,所以可以安全地移除相关的边,并删除独立的节点。
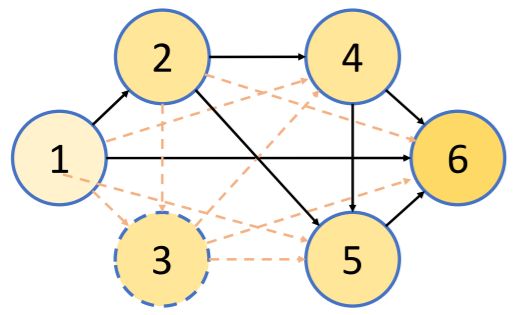
图 1:可以用完全连接的 DAG 表示整个搜索空间。节点 1 和 6 分别是输入节点和输出节点。虚线和虚线圆表示删除了与它们相关的节点和边。例如,可以通过 h(5)=O(5)(P4j=1h(j))计算节点 5 的初始输出,但对删除过的子图而言,变成了 h(5)=O(5)(h(2)+h(4))。
搜索空间
DSO-NAS 可以搜索 DNN 中每个构建块的结构,然后和 DNN 中所有的块共享,就像之前的工作一样。它也可以在不共享块的情况下直接搜索整个网络架构,同时还保持着极具竞争力的搜索时间。我们在下文中将先讨论每一个独立块的搜索空间,再讨论整个宏架构。
一个块由 M 个顺序层组成,这些顺序层又由 N 个不同运算组成。在每个块中,每个运算都和前面层的所有运算以及块的输入相连接。因此,块的输出也和块中的所有运算有关。对每一个连接来说,我们用乘数 λ 缩放了其输出,并强行加了稀疏正则化。优化后,删除了 λ 为 0 的相关连接和所有独立的运算得到最后的架构。块搜索的过程如图 2 所示。
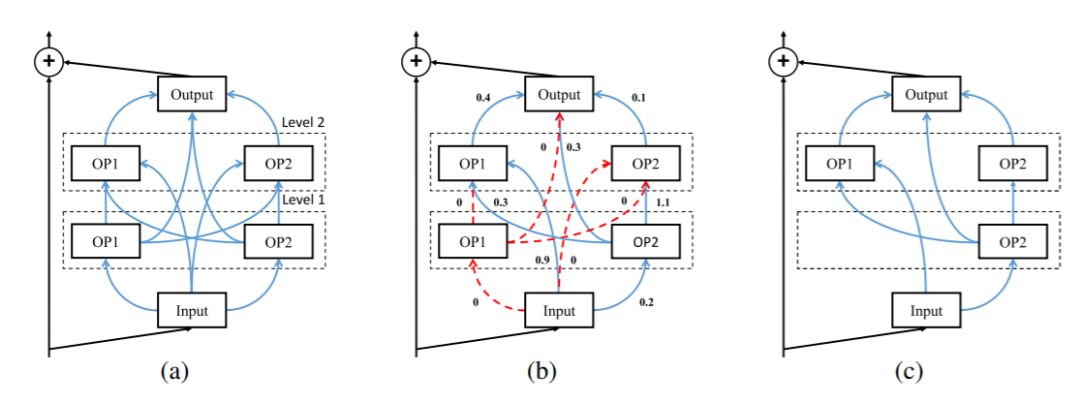
图 2:搜索块的例子,该例中有两个 level 和两步运算:(a)完全连接的块。(b)在搜索过程中,我们联合优化了神经网络的权重以及与每一个边都相关的 λ。(c)删除无用的连接和操作后的最终模型。
实验
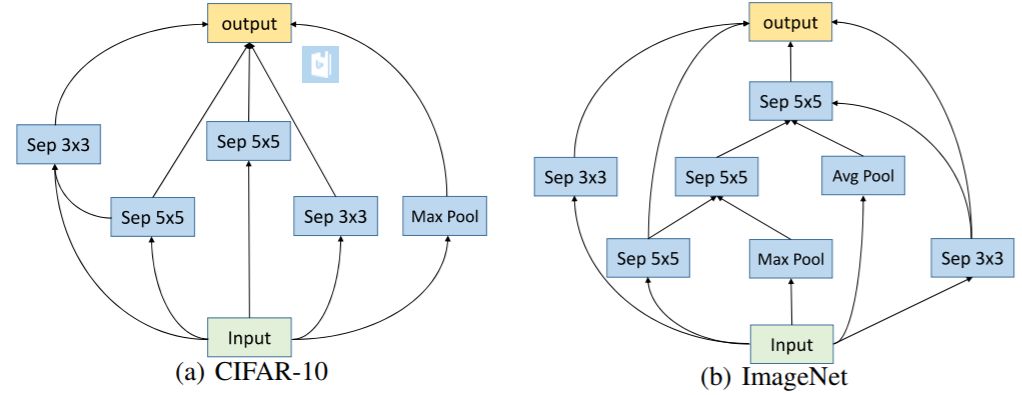
图 4:在不同数据集上学到的块结构。
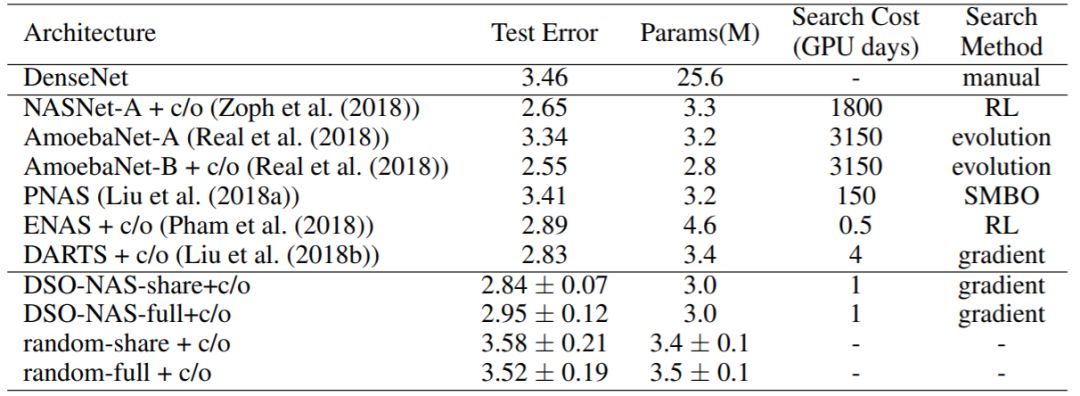
表 1:在 CIFAR-10 上与当前最佳的 NAS 方法的比较。
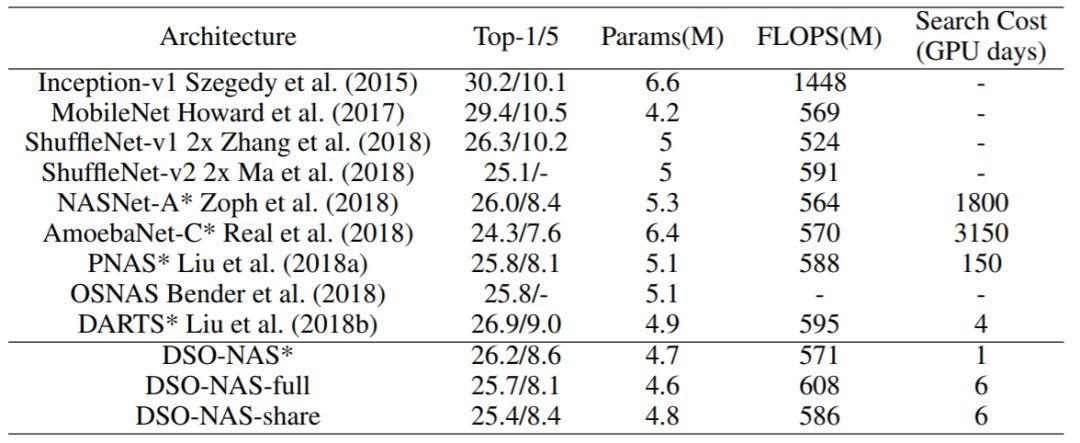
表 2:在 ImageNet 上与当前最佳的图像分类器的比较。
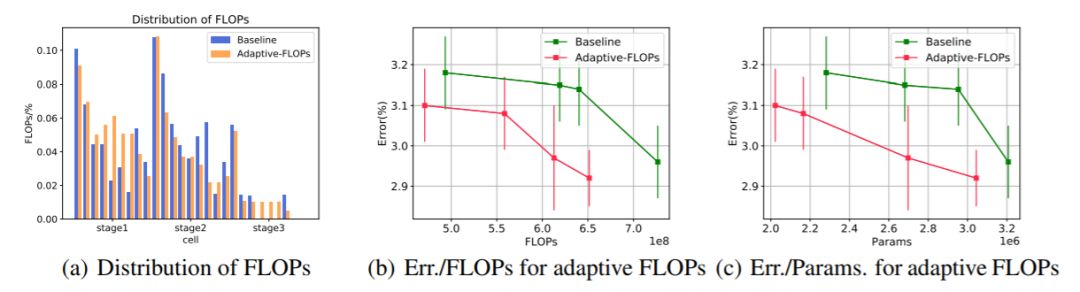
图 5:自适应 FLOPs 技术的性能。
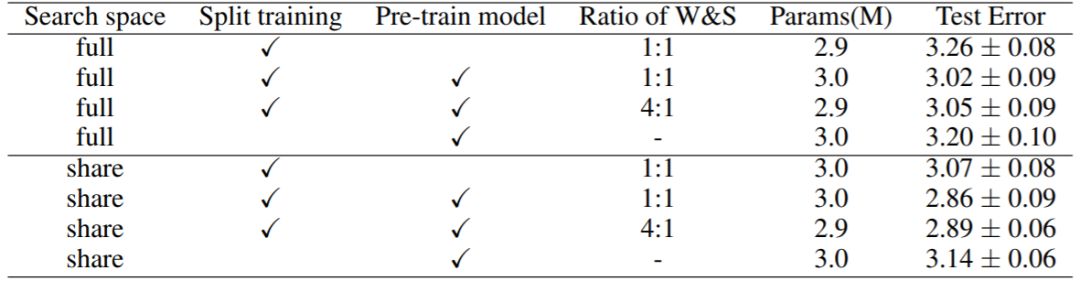
表 3:在 CIFAR-10 数据集上不同设置的比较。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

