「CVPR2020」分布传播图网络的小样本学习

点击蓝字,设为星标

❝本文来自知乎作者@「周大侠」,点击阅读原文可直达作者知乎首页。
❞
「CVPR2020」:Distribution Propagation GNN for FSL
DPGN:Distribution Propagation Graph Network for Few-shot Learning

摘要
目前大部分基于GNNs的元学习方法对实例级(instance-level)关系进行建模。本文扩展了此思想,用1-vs-N的方式将一个实例与所有其他实例对应的分布级(distribution-level)关系进行建模,提出了 distribution propagation graph network (DPGN)方法用于小样本学习。该方法同时利用了实例级(instance-level)关系和分布级(distribution-level )关系。构造了一个由一个点图( point graph)和一个分布图( distribution graph)组成的对偶完全图网络(dual complete graph network),其中每个节点代表一个实例。大量的实验表明DPGN能取得SOTA性能。原文和代码链接如下:
原文:
https://arxiv.org/pdf/2003.14247
代码:
https://github.com/megvii-research/DPGN
Introduction
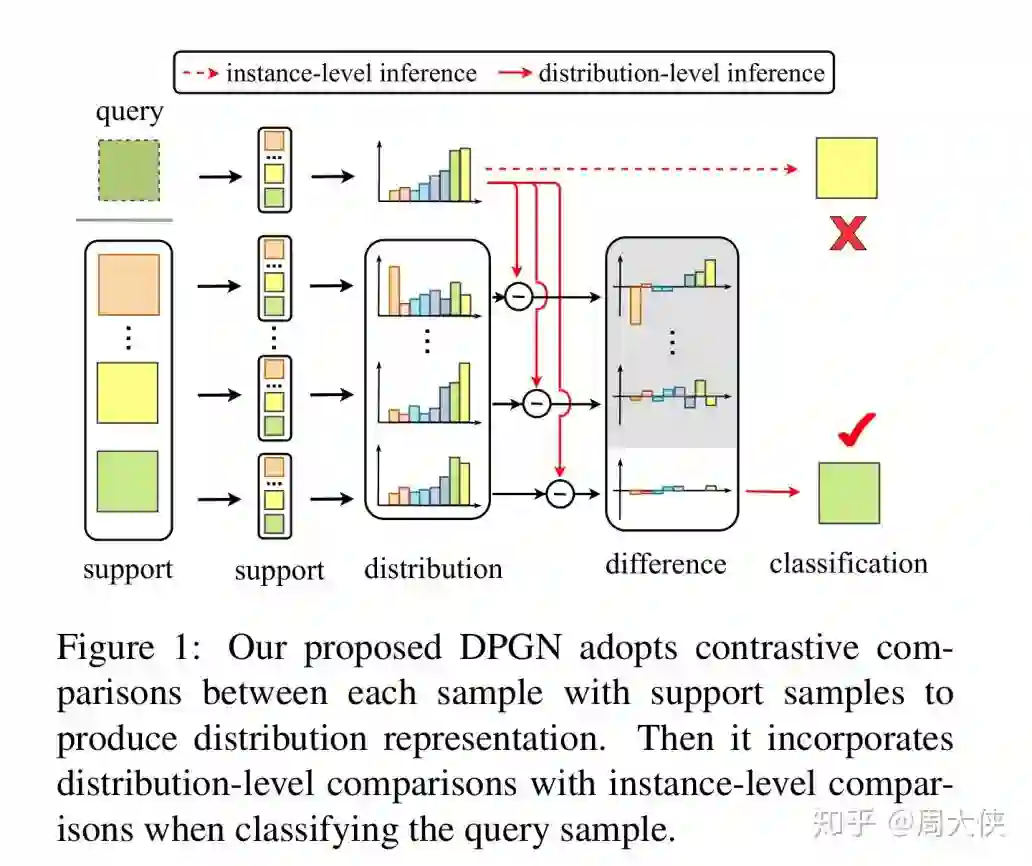
小样本学习(FSL)任务的目的是在给定少量标记数据(support set)的条件下,预测出未标记数据(query set)的标签。其中Fine-tuning容易导致过拟合;GNN类的方法关注于节点对之间的关系,而忽略了重要的分布关系;元学习的方法也没有直接利用整体关系(global relations)。
如图一所示,首先提取样本的 instance feature,然后通过计算样本之间的instance-level相似性得到distribution feature。为了能同时利用两种feature,提出了一种 dual-graph架构:点图( point graph,PG)和分布图( distribution graph,DG)。特别的,一个PG通过聚集每个节点的1-vs-n关系来产生一个DG;而DG通过传递每一对实例间的分布关系来调整PG。这种循环转换充分融合了实例级和分布级关系。该方法主要贡献如下:
-
DPGN是第一个显示的利用分布传播的GNN方法,用于解决FSL问题 -
提出 dual complete graph network,同时利用实例级(instance-level)关系和分布级(distribution-level )关系 -
大量的实验表明DPGN能取得SOTA性能
Method
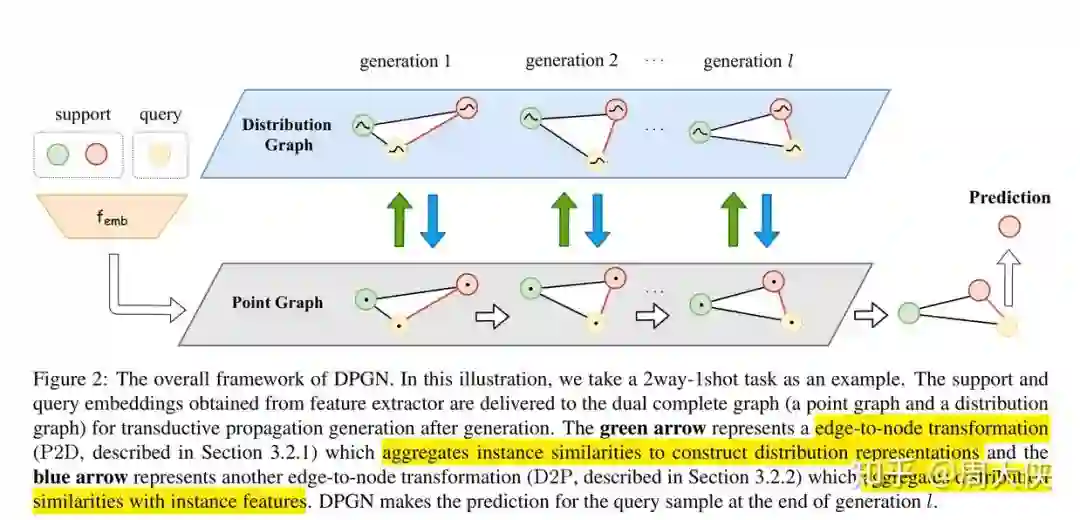
Distribution Propagation Graph Networks
图2展示了模型的主要过程。DPGN包含l轮的更新(generations),每一次更新包括一个点图(PG)

1. 首先通过convolutional backbone提出样本特征利
2. 利用



3. 最后,取得的
通过不断重复上述过程。上述循环过程可以总结成如下:



Point-to-Distribution Aggregation
「Point Similarity」点图中边




「P2D Aggregation」如图3所示,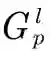






Distribution-to-Point Aggregation
「Distribution Similarity」 在分布图中,每条边




如图3所示,在每轮的更新结束时,在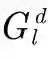


Objective
节点分类的通过将DPGN最后一次更新的边特征输入到softmax函数:
「Point Loss」该损失直接使用就是交叉熵:

「Distribution Loss」为了加快训练过程以及能学习到有判别力的特征,定义了分布损失如下:




Experiments
主要用了4个数据集,其具体数据集介绍和实验设置请查看原始论文。从结果可以看到,提出的DPGN方法确实是比较好的,达到了state-of-the-art的性能,同时领先的幅度是比较大的。
Personal Thoughts
「优点:」
首次提出利用了分布传播的GNN方法,方法比较新颖 同时了利用实例级(instance-level)关系和分布级(distribution-level )关系 实验部分非常充足,证明该算法能达到SOTA 同时也做了大量的消融实验,证明提出的分布传播是有效的
「Comments:」
个人感觉现在基于GNNs方法越来越复杂,更开始侧重更高级的表征,例如distribution-level,这种global的特征是非常重要的
往期精彩内容推荐

球分享

球点赞

球在看
点击下方“阅读原文”直达作者知乎首页


