【KDD22】DICE: 域攻击不变的因果学习以保护数据隐私、提升攻击迁移性和对抗鲁棒性
本文介绍我们被KDD 2022接收的新工作:DICE: Domain-attack Invariant Causal Learning for Improved Data Privacy Protection and Adversarial Robustness。我们利用因果推断来建模分析和改善了当前攻击和防御算法各自的局限性。
作者:任麒冰,陈奕廷,莫易川,吴齐天,严骏驰
关键词:数据隐私,对抗鲁棒性,因果推断,攻击迁移性
论文链接:https://dl.acm.org/doi/10.1145/3534678.3539242
代码链接:https://github.com/Thinklab-SJTU/DICE
背景介绍和研究动机:
1)对抗攻击和虚假攻击:
对抗攻击 (adversarial attack) 发生在模型部署阶段,通过对测试集的数据注入恶意的而人眼不可见的噪声,来降低模型在攻击后的测试样本上的表现。虚假攻击 (delusive attack) 则发生在模型训练阶段,可看作数据投毒的一种,通过对训练集的数据进行恶意且不可见的扰动,大大降低模型在干净的测试数据上的表现。其中虚假攻击可以用于数据隐私保护:如果数据拥有者在公开隐私数据前主动对数据进行虚假攻击,可以防止数据被未经授权或者非法使用,因为虚假攻击后的数据对于模型训练是有害的。
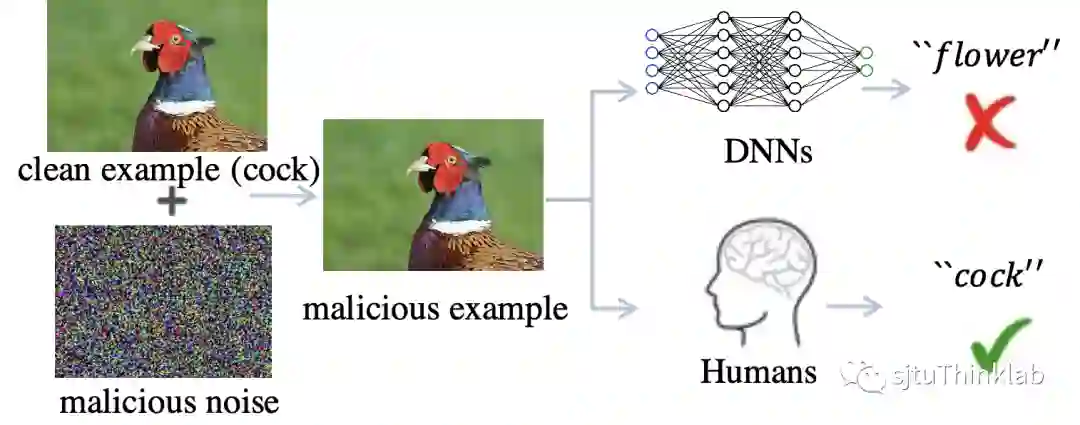
即使两种攻击手段通过造成测试域或者训练域的域偏移 (domain shift)在深度神经网络 (DNNs)上取得了很好的效果,然而它们并不会影响人类判断 (图 1)。对此一种流行的假设是人类认知系统能够捕捉到图像和标签中对域偏移保持不变的因果联系,而DNNs为了达到人类设置的监督目标,倾向于利用数据和标签之间所有的相关性来拟合数据,其中就可能有虚假的相关性,比如一张图像为草地上的鸡,草地并不是决定该图像标签 (鸡)的决定性因素,但是因为其在类别为“鸡”的图像里经常出现,所以容易被神经网络利用来做决策。因此,有理由认为攻击者的成功在于利用了这类虚假因子,造成训练数据和测试数据间的域偏移,使之不满足独立同分布 (IID)假设,降低模型的泛化性能。
然而这两类攻击造成的威胁很大程度上可以通过对抗训练 (adversarial training)得到缓解。对抗训练通过让模型在训练阶段拟合对抗数据来提升鲁棒性,对抗训练的成功展示出被攻击者扰动的虚假因子可以很容易的通过对抗训练恢复出来。所以如果攻击者可以识别并且扰动数据和标签之间的因果关系,就可以进一步提升他们在对抗训练下的性能。
2) 对抗训练:
然而对抗训练也有局限性,对抗训练的模型从训练集到测试集存在着巨大的泛化误差。既然我们假设攻击者成功之处在于利用了虚假因子,那么对抗训练也会因为在对抗样本上训练而拟合其中隐含的虚假因子。所以,当数据和标签之间的虚假联系随着域不同而变化时,模型的鲁棒性也会随之改变。从这个意义上来说,识别出数据和标签之间的因果关系也会帮助更好的鲁棒泛化。本文即利用因果推断这个强有力的工具来识别因果关系,通过因果干预来移除虚假因子。
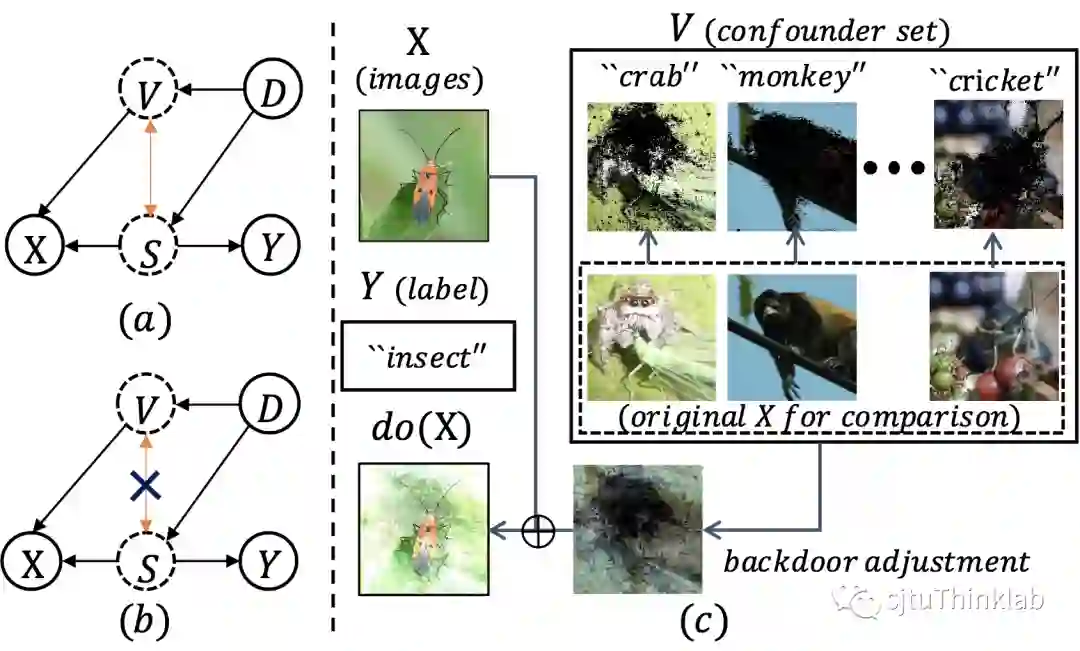
域攻击不变的因果图
首先,我们需要在攻防的语境下构建一个因果图来描述隐式因子和观测变量之间的联系。我们从数据生成的视角出发,提出了一个自底向上的结构化因果模型 (structural causal model)。如图2所示,我们把隐式因子划分为决定标签 的因子 (比如图像中的前景物体的形状)和其他因子 (比如前景物体的纹理), 和 共同组成了可观测的样本 。我们进一步假设 和 存在着虚假关联,这种虚假关联使得 可以通过 这条路径来影响 ,攻击者也就是利用这条路径改变了模型的正确输出。我们引入了域变量 ,来建模由攻击造成的域迁移对模型的影响。至此,我们可以从因果的视角对攻击和防御的运行原理进行重新阐释:(1) 攻击者通过干预 ,来影响分布 ,进而生成攻击样本 ;(2) 防御方则通过改变分布 来提升鲁棒性,诸如跨域模型的集成[1],或者更多的域外数据的加入[2]等;
域攻击不变的因果学习
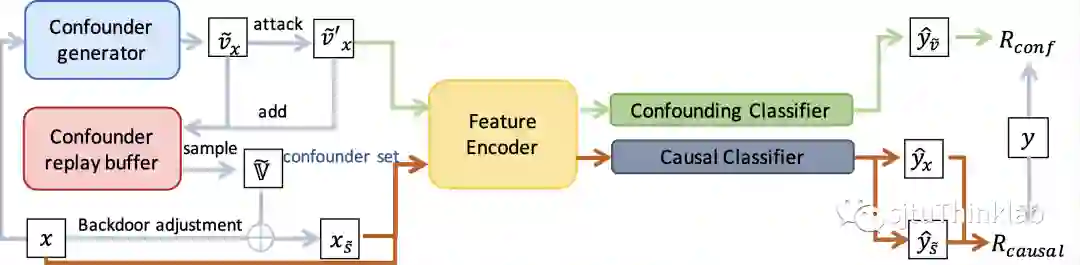
基于我们的因果图,我们提出了域攻击不变的因果学习模型 (DICE),通过因果干预来移除虚假因子。具体的,我们提出使用后门调整来进行因果干预,也就是通过干预 ,来阻断上文提到的 到 的通路,由此可以让模型只通过 这条通路进行学习。然而,由于 是不可观测的,直接对 进行物理干预是不实际的,所以我们设计了一种高效的虚拟干预策略。我们基于“鲁棒模型对输入样本的梯度信息和和人类感知对齐”[3]这一先验知识,提出利用梯度信息的大小在观测空间衡量 和 ,梯度揭示的重要区域是和人类感知一致的,因此我们将重要区域提取出来作为 的代表,剩余区域作为 的代表, 图 2(c)展示了我们方法的定性结果。进一步的,为了提高拟合的虚假因子 的多样性和混淆强度,我们引入了目标对抗攻击。最后,DICE通过最小化我们设计的因果不变损失,学会移除 来推断决定标签的因子 ,算法概念如图 3所示,细节请参考论文。
实验结果
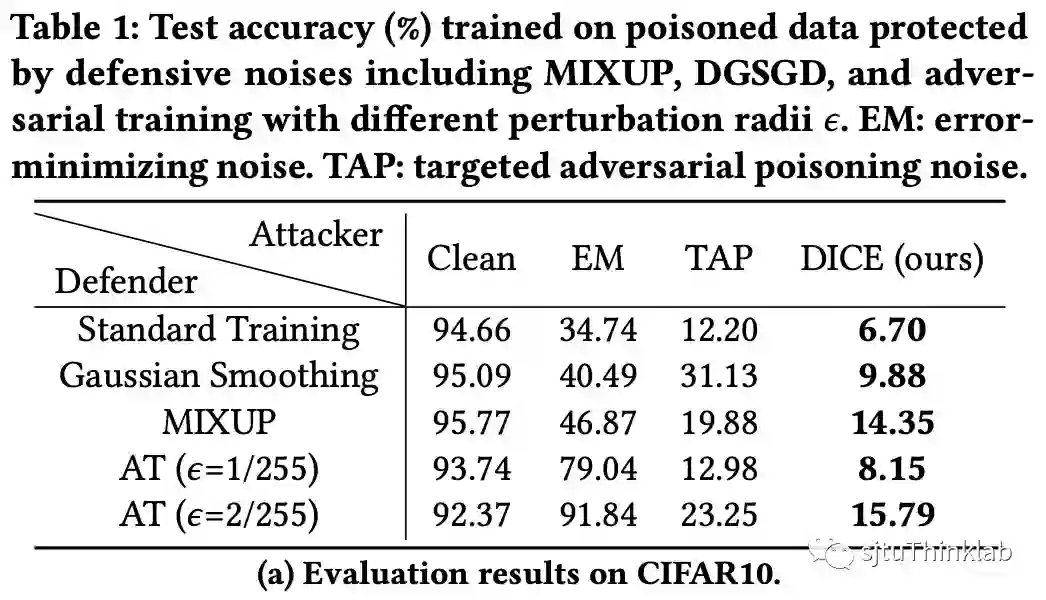
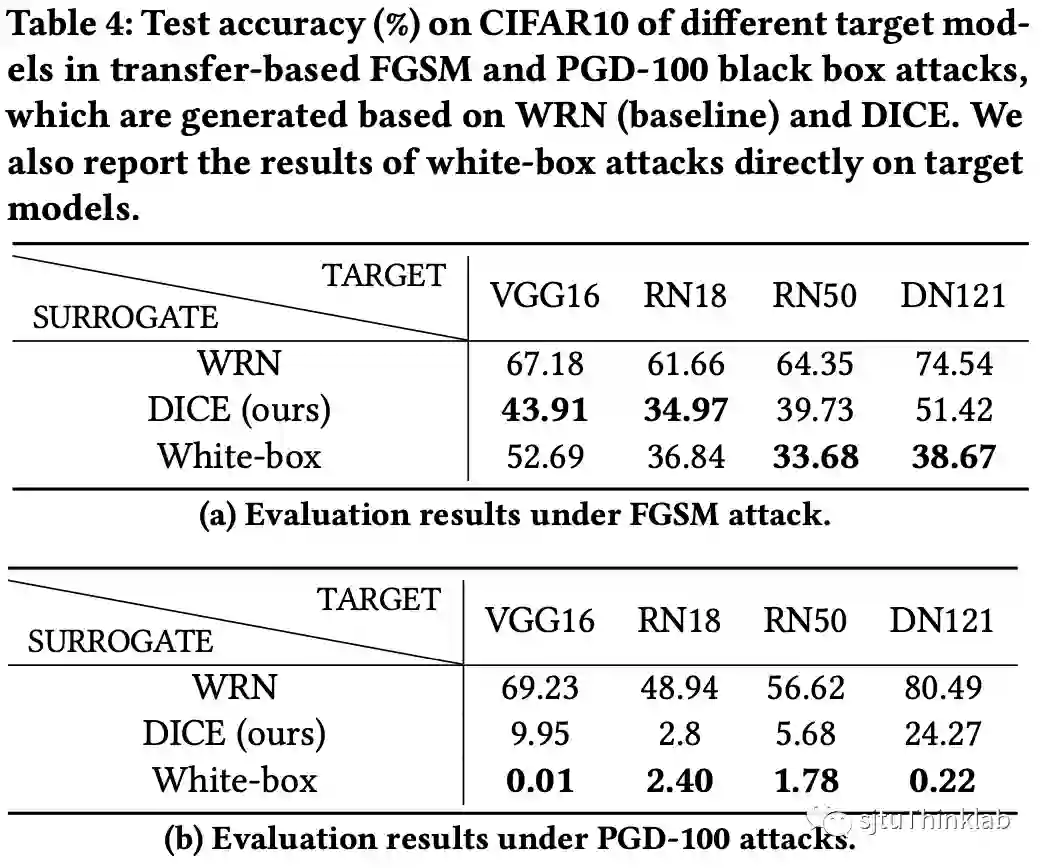
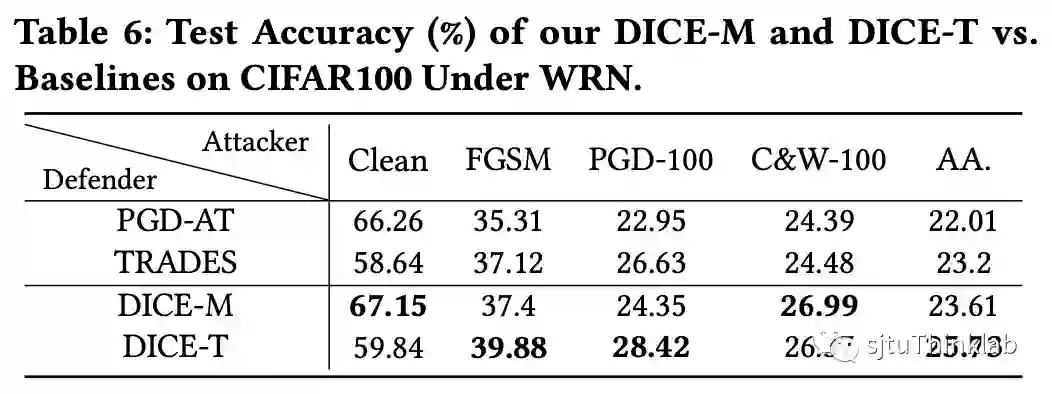
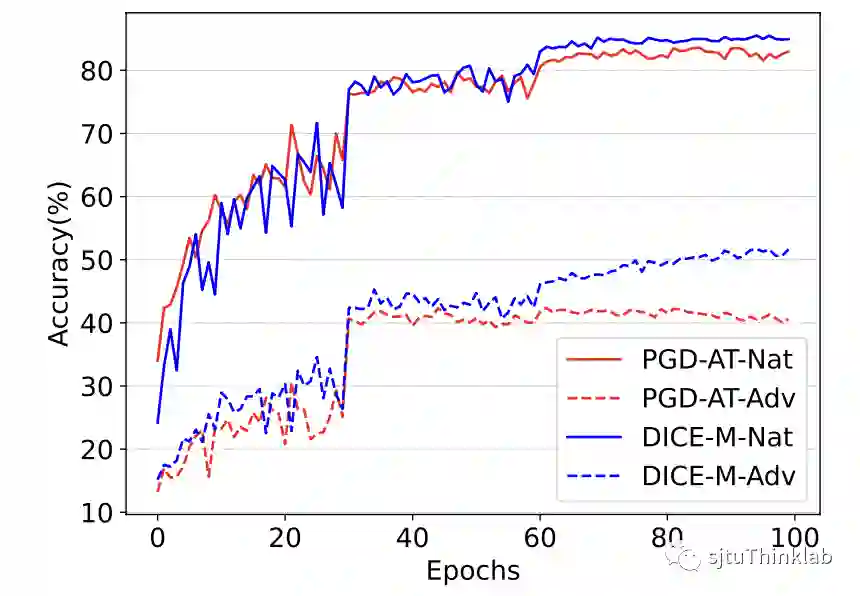
我们在CIFAR-10和CIFAR-100两个真实世界数据集上,面对三个下游任务,验证了DICE的优势。(i). 对于虚假攻击,我们的算法超越了目前的最优算法 [4][5],实现了最佳性能 (图 4);(ii). 对于对抗攻击,因为DICE推断出来的因果特征 有域不变的性质,我们着重评估了经过DICE生成的对抗样本在不同模型之间的迁移性,实验结果表明DICE可以极大提升对抗攻击的性能,甚至和白盒攻击的效果相匹配 (图 5);(iii). 在对抗防御任务上,DICE可以集成到目前流行的PGD-AT [6]和TRADES [7]两个对抗训练框架上,同时改善精度和鲁棒性的泛化性问题 (图 6和7)。
 |
 |
|---|---|
| 图 4. 虚假攻击实验结果 (CIFAR-10) | 图 5. 对抗迁移性实验 (CIFAR-10) |
 |
 |
|---|---|
| 图 6. 对抗鲁棒性实验 (CIFAR-100) | 图 7. DICE改善鲁棒泛化性 |
未来展望
我们计划从理论上进一步探索虚假关联和决定标签的因果关联的Identifiability;目前拟合虚假因子需要一次梯度回传以获取梯度重要性信息,计划设计更加高效的拟合手段;验证我们算法的泛化性:在大规模数据集上和域适应、域泛化等其他任务上。
如果您对我们的工作感兴趣或者对我们的代码有任何问题,欢迎联系renqibing@sjtu.edu.cn.
引用:
[1] Tianyu Pang, etc. Improving adversarial robustness via promoting ensemble diversity, ICML 2019.
[2] Yair Carmon, etc. Unlabeled data improves adversarial robustness, NeurIPS 2019.
[3] Dimitris Tsipras, etc. Robustness may be at odds with accuracy. arXiv preprint arXiv:1805.12152 (2018).
[4] Liam Fowl, etc. Adversarial examples make strong poisons, NeurIPS 2021.
[5] Hanxun Huang, etc Unlearnable examples: Making personal data unexploitable, ICLR 2021.
[6] Aleksander Madry, etc. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083 (2017).
[7] Hongyang Zhang, etc. Theoretically principled trade-off between robustness and accuracy, ICML 2019.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DICE” 就可以获取《【KDD22】DICE: 域攻击不变的因果学习以保护数据隐私、提升攻击迁移性和对抗鲁棒性》专知下载链接



