知识图谱以概念之间的关系表示世界上的事实知识,对于企业应用中的智能决策至关重要。通过将概念和关系编码为低维特征向量表示,从知识图谱中已有的事实中推断出新的知识。这一任务最有效的表示方法称为知识图嵌入(KGE),是通过神经网络体系结构学习的。由于其令人印象深刻的预测性能,它们越来越多地用于高影响力的领域,如医疗保健、金融和教育。然而,黑箱KGE模型在高风险领域的使用是否具有反鲁棒性呢?本文认为,最先进的KGE模型容易受到数据中毒攻击,即系统地对训练知识图进行扰动会降低其预测性能。为支持这一论点,提出了两种新的数据中毒攻击,在训练时制造输入的删除或添加,以破坏学习模型在推理时的性能。这些攻击的目标是使用知识图谱嵌入预测知识图谱中缺失的事实。
针对对抗缺失导致模型性能下降的问题,提出使用模型无关的实例归因方法。这些方法用于识别对KGE模型对目标实例预测影响最大的训练实例。有影响的三元组用作对抗性删除。为了通过对抗性添加来毒害KGE模型,利用它们的归纳能力。KGE模型的归纳能力是通过知识图中的对称、反转和组合等关系模式来获取的。具体而言,为了降低模型对目标事实的预测置信度,本文提出提高模型对一组诱饵事实的预测置信度。因此,通过不同的关系推理模式,构建了可以提高模型对诱饵事实预测置信度的对抗性添加。对提出的对抗性攻击的评估表明,它们在两个公开可用的数据集的四个KGE模型上优于最先进的基线。在提出的方法中,更简单的攻击与计算成本高的攻击竞争或优于它们。论文的贡献不仅强调并提供了一个机会来修复KGE模型的安全漏洞,而且还有助于理解这些模型的黑箱预测行为。



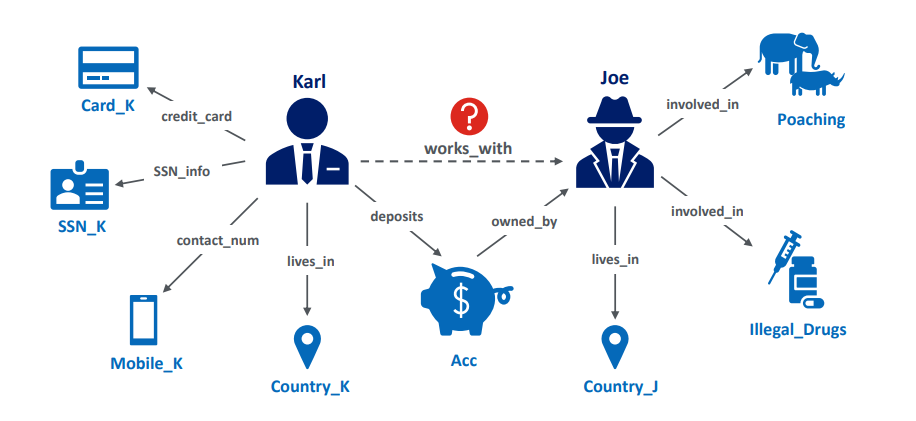
假设有一个金融监管机构想要发现和预测洗钱活动,在这种活动中,恶意方通过一系列金融交易将其从非法活动中获得的收入汇入合法的银行账户。鉴于此类活动的复杂性和相互关联的性质,分析来自孤立银行账户的金融交易往往不足以在实践中抓住诈骗犯。相反,利用不同金融实体之间的关系,跨不同的金融数据来源执行集成分析。为了实现这种集成分析,知识图谱已经成为建模和集成来自不同来源的关于多个金融实体的事实知识的事实标准(Hogan等人,2021;Noy等人,2019)。像银行账户这样的实体、它们的所有者和资产被表示为知识图谱的节点,这些实体之间的交互和交易被表示为图的标记边。由于数字金融交易的数量不断增长,数据驱动的机器学习(ML)方法被用于挖掘这个相互关联的交易图中的模式。对图表数据的学习和推断驱动智能决策,如预测不同账户之间的可疑交易或账户所有者之间的隐藏从属关系(Khalili等人,2020;张,2020;辛格森和索尼,2021年)。然而,有非法收入可洗黑钱的恶意方极有动机逃避这些系统的检测。因此,这些参与者可能试图通过操纵他们的个人信息和输入知识图谱中的交易来破坏数据驱动智能系统的预测。在这种对抗性环境中,机器学习模型对知识图谱的预测是否可靠?
与金融领域的反洗钱应用一样,知识图谱是有关互联实体及其之间关系的事实知识的普遍表示(Hogan等人,2021)。近年来,多个大规模知识图谱被开发出来,用于支持搜索引擎、电子商务、社交网络、生物医药、金融等领域的智能决策。谷歌和微软等商业企业已经从网络上的文本资源构建了网络规模的知识图谱,以支持谷歌搜索和必应。类似地,Facebook和LinkedIn依赖于用户知识的图表表示来了解用户偏好并推荐潜在的联系或工作机会。亚马逊和eBay等在线供应商也使用企业知识图谱来编码用户的购物行为和产品信息,以改进产品推荐。埃森哲(Accenture)、德勤(Deloitte)和彭博(Bloomberg)等其他公司也在金融服务领域部署了知识图谱。这些财务图表为企业搜索、财务数据分析、风险评估和欺诈检测等应用提供了强大的支持(Hogan等人,2021年;Noy等人,2019)。
更一般地说,在自然语言处理(NLP)领域,注入以事实知识图谱表示的背景知识,以支持知识感知的应用,如基于知识的问答或知识库的可解释事实检查(Ji et al., 2022; Kotonya and Toni, 2020)。研究结构化知识表示与非结构化文本语言表示相结合的方法是该领域一个新兴的研究方向。这些方法寻求利用事实和常识知识来提高NLP模型的上下文推理和理解能力(Malaviya et al., 2020; He et al., 2020; Zhang et al., 2022)。类似地,在计算机视觉(CV)领域,用于图像分类、视觉问题回答和基于骨架的动作识别等任务的机器学习通过将场景或图像中的对象之间的关系表示为知识图来增强(见Ma和Tang, 2021年,第11章)。另一方面,知识图谱在医疗保健和生物医学研究方面也出现了一些新兴应用。在这里,生物网络被用来模拟不同蛋白质结构、药物和疾病之间的联系和相互作用。此外,将生物医学知识与患者的电子健康记录结合起来,可以对疾病共病进行综合分析,从而实现个性化精准医疗(Rotmensch et al., 2017; Mohamed et al., 2020; Li et al., 2021; Bonner et al., 2022)。因此,知识图谱是现代智能系统中学习和推理的支柱。
为了将图数据合并到标准ML管道中,需要将符号图结构表示为可微的特征向量。传统算法启发式和领域工程的手工艺品的特性基于统计图或节点的拓扑结构,或内核方法(看到汉密尔顿,2020年,第2章)。缺乏灵活性的特征工程使得图形方式表示学习算法,学习图结构表示为低维连续特征向量,也称为嵌入。为了学习实体的嵌入,这些算法旨在保留实体在图域中邻域的结构信息,作为嵌入域中的相似性度量。通过这种方式,对实体嵌入的代数操作反映了这些实体之间的图结构交互,从而允许来自图的拓扑信息用于不同的ML任务。基于深度学习的神经网络架构用于优化知识图中实体和关系的表示,以便学习到的表示最好地支持要在图上执行的下游ML任务(Hamilton等人,2017b;由于其对不同下游任务的有效性,图表示学习算法已成为使用知识图进行学习和推理的最先进方法(Chen et al., 2020; Nickel et al., 2016a)。
基于深度学习的方法的成功归功于它们能够从大量输入数据中提取丰富的统计模式。然而,由于是数据驱动的,学习到的模型是不可解释的,预测的原因是未知的。由于这种黑盒预测行为,模型的失效模式也是未知的。已有研究表明,深度学习模型的预测可以通过操纵其输入数据来操纵(Biggio和Roli, 2018;约瑟夫等人,2019)。这对于医疗保健、金融、教育或执法等高风险领域尤其令人担忧,在这些领域,知识图谱的表示学习算法越来越多地使用(Mohamed等人,2020;邦纳等人,2022年)。在这些领域中,决策结果会影响人类的生活,模型失败的风险非常高。另一方面,由于高风险,很可能会有动机敌对的参与者想要操纵模型预测。此外,知识图谱通常从网络上的文本来源自动提取,或从用户生成的内容中策划(Nickel等人,2016a;Ji et al., 2022)。这使得对手很容易向图中注入精心制作的虚假数据。因此,在高风险的面向用户领域部署图表示学习模型,模型的良好预测性能是不够的。确保模型的使用安全性和鲁棒性是至关重要的。然而,建立对抗鲁棒模型需要测量模型的对抗鲁棒性的方法。换句话说,对抗鲁棒图表示学习模型的必要前提是识别现有模型的失效模式或安全漏洞的方法。
本文的研究是出于识别黑盒图表示学习算法的对抗性漏洞的需要,将其作为将其负责任地集成到高风险用户面对的应用程序的关键一步。