贝叶斯分析助你成为优秀的调参侠:自动化搜索物理模型的参数空间

©PaperWeekly 原创 · 作者|庞龙刚
学校|华中师范大学
研究方向|能核物理、人工智能
学习内容

贝叶斯公式
随机变量 的联合概率密度分布 可以写成以下两种形式:
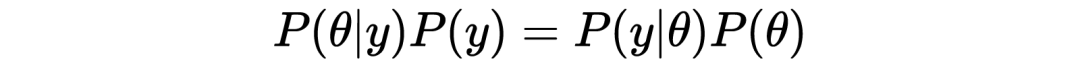
若将左边的 除到右边,则有:
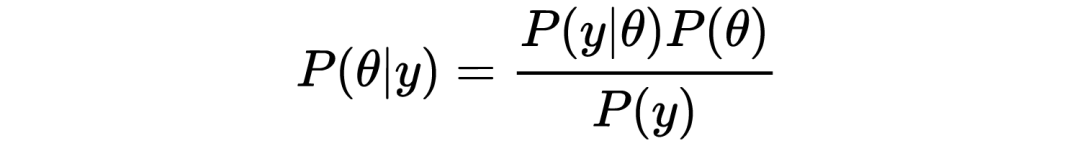
这就是著名的贝叶斯公式,后面马上会用到。

科学的研究方法与贝叶斯分析
First you guess. Don't laugh, this is the most important step. Then you compute the consequences. Compare the consequences to experience. If it disagrees with experience, the guess is wrong. In that simple statement is the key to science. It doesn't matter how beautiful your guess is or how smart you are or what your name is. If it disagrees with experience, it's wrong. That's all there is to it.
——By Richard P. Feynman
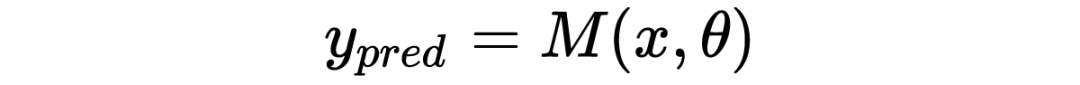
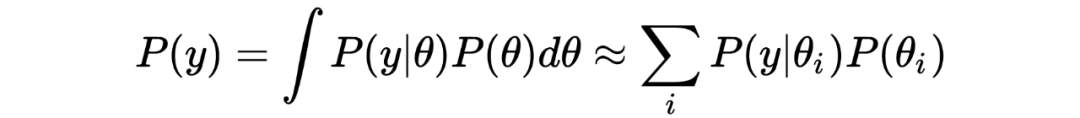
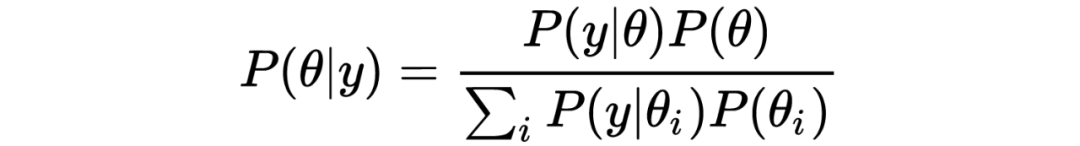
费曼对科研的描述中:
3. 费曼没有提如果有很多模型都可以描述同样的实验数据,那么真实理论是其中一种的几率就会降低。这一项对应归一化系数,即分母上对不同参数的似然加权求和。有时又称“证据” Evidence;
4. 费曼也没有提人们对模型参数的信仰会随着数据的增多而发生改变和更新。这就是后验(Posterior)。

关于模型
物理模型都是真实世界的近似描述。 对于不同的参数,张开了一个函数空间,真实世界的函数一般并不能在此函数空间中完美展开。但是,只要对某组参数, 能够近似描述实验数据,就可以认为它是真实世界的一个有效模型。
很多时候,我们需要跟实验对比,寻找这个有效模型的参数 。
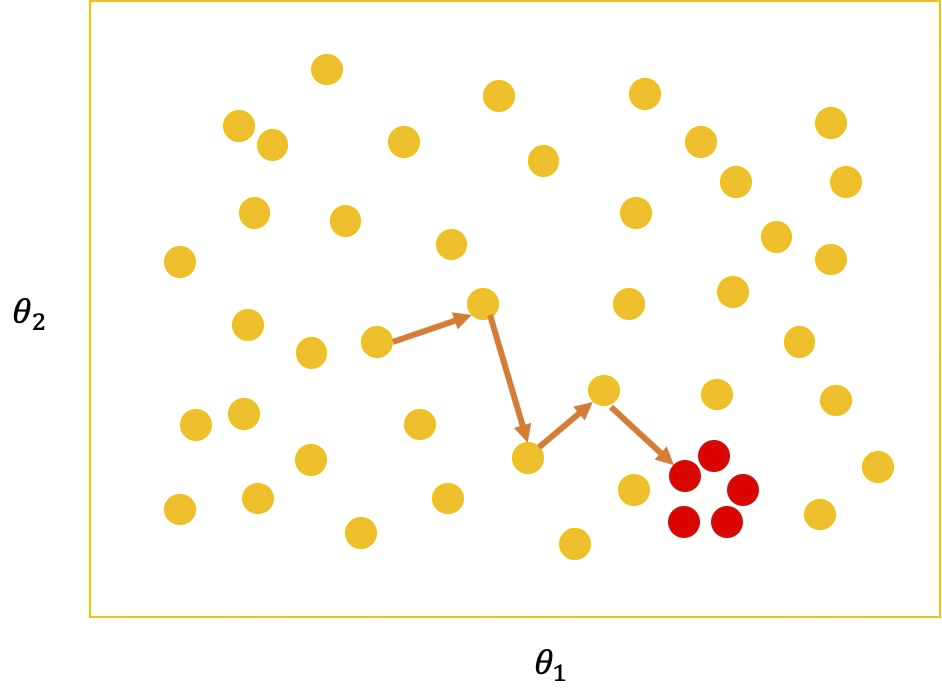
举例,模型有两个参数, ,构成 2 维参数空间,可以使用 Grid Search 法逐点探索。但对于大部分参数来说,模型输出与实验数据的 likelihood 都很低,处于不值得浪费时间探索的参数空间区域,如下图所示:

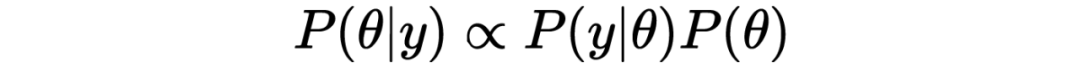
算法实现(仅用作教学目的):
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm import tqdm
import os
def mcmc(func, ranges, n=100000, warmup=0.1, thin=1, step=1, initial_guess=None):
'''Metropolis-Hastings sampling for distribution func
:func: non-normalized distribution function
:ranges: the lower and upper bound of params, its shape determines ndim,
np.array([[xmin, xmax], [ymin, ymax], [zmin, zmax], [..., ...]])
:n: number of samples
:warmup: ratio of samples that will be discarded
:thin: samples to skip in the output
:step: effective step length in the proposal function
:initial_guess: initial position in the parameter space'''
ran = np.random.random
normal = np.random.normal
ndim = ranges.shape[0]
samples = np.empty((n, ndim), dtype=np.float32)
xmin, xmax = ranges[:, 0], ranges[:, 1]
# start from somewhere in the parameter space
if initial_guess == None:
r = ran()
x0 = xmin * (1 - r) + xmax * r # initial sample
else:
x0 = initial_guess
step = step * (xmax - xmin) / (xmax - xmin).max()
for i in tqdm(range(n)):
r = normal(size=(ndim)) # propose the next move
x1 = x0 + r * step
alpha = min(func(x1) / func(x0), 1) # acception rate
r0 = ran()
if (r0 <= alpha) and (x1>xmin).all() \
and (x1<xmax).all(): # accept the proposal
x0 = x1
samples[i] = x0 # or keep the previous sample
return samples[int(warmup*n):-1:thin]
调用上面实现的 MH 算法,对函数 抽样:
def fun(theta):
return np.exp(-np.abs(theta))
# get 1,000,000 samples using mcmc
ranges_ = np.array([[-5, 5]])
samples = mcmc(fun, ranges_, n=1000000, warmup=0.1, thin=10)100%|██████████| 1000000/1000000 [00:11<00:00, 85041.25it/s]
本来我们设定要抽样 1000,000 个样本,但因为使用了 warmup 和 thin 两个参数,最终得到的样本数量只有 90000 个。
# 'warmup' removes 10% data
# 'thin' reduces the size by a fact of 10
print(samples.shape)# this script is to make an animation for the mcmc sampling
%matplotlib notebook
from matplotlib.animation import FuncAnimation
# compute the distribution of these samples using histogram
hist, edges = np.histogram(samples.flatten(), bins=500)
x = 0.5 * (edges[1:] + edges[:-1])
fig1, ax1 = plt.subplots()
ax1.plot(x, hist/hist.max(), '-', label="MCMC")
ax1.plot(x, fun(x), '-', label = r"$f(\theta) = \exp(-|\theta|)$")
plt.legend(loc='best')
plt.xlabel(r'$\theta$')
plt.ylabel(r'$f(\theta)$')
ax1.set_xlim(x[0], x[-1])
dot, = ax1.plot(0, 1, 'o', ms=10)
def update(i):
xi = samples[i]
dot.set_data(xi, fun(xi))
return dot,
anim = FuncAnimation(fig1, update, frames=1000, interval=50, blit=False)

Warmup 与 Thin 两个参数是什么
这两个参数都表示要扔掉部分样本。warmup=0.1 表示在样本列表的最前端扔掉 10% 的样本,thin=10 表示在剩下的样本中每隔 10 个样本保留一个。下图中蓝色是保留下的样本,灰色是扔掉的样本。

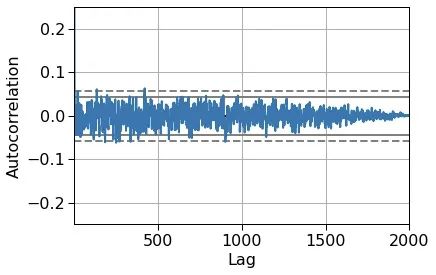
因为 MCMC 样本都是按顺序产生的,后一个样本依赖于前一个样本的位置,所以样本与样本之间有自关联(Auto Correlation),使用 thin 参数,每隔几个样本保留一个有利于削弱自关联。这里可以画图看一下自关联。
%matplotlib inline
s = pd.Series(samples[:2000].flatten())
ax = pd.plotting.autocorrelation_plot(s)
plt.ylim(-0.25, 0.25)
Warmup 是为了扔掉初期还没有达到细致平衡的那些样本。在二维或高维抽样时可以非常直观看到早期样本不满足最终分布。
def fun2d(theta):
return np.exp(-np.abs(theta).sum())
# get 100,000 samples in 2d-parameter space using mcmc
ranges_ = np.array([[-5, 5], [-5, 5]])
samples2d = mcmc(fun2d, ranges_, n=1000, warmup=0.0, step=1)
plt.scatter(samples2d[:, 0], samples2d[:, 1], label="all samples")
plt.plot(samples2d[:15, 0], samples2d[:15, 1], 'ro-', label="initial samples")
plt.plot(samples2d[0, 0], samples2d[0, 1], 'r*', ms=15, label="start")
plt.xlabel('param 1')
plt.ylabel('param 2')
plt.legend(loc='best')
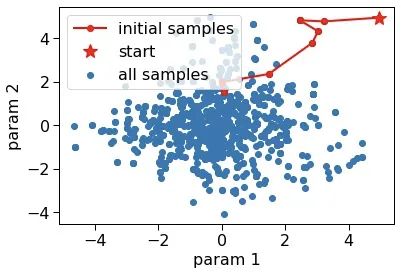
▲ 红星是在参数空间中探索的开始位置,红色连线是初始的几步探索,蓝色圆点是后期在参数空间探索留下的足迹——所以有些库将抽样得到的参数列表用英文 trace(迹) 表示。

总结
为了防止文章太长,这里简单总结一下。只要知道了模型参数的先验分布和似然函数,就可以定义非归一化的后验分布函数, 。使用马尔可夫链蒙特卡洛算法 MCMC,可以对这个后验分布抽样,得到能够拟合实验数据的模型参数 的分布。知道了参数的分布,就能计算拟合实验数据最好的那个参数组合(最大后验估计),以及模型的不确定度。
下一节继续介绍贝叶斯分析调参时先验和观测对后验分布的影响,以及如何克服物理模型运行缓慢的困难。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




