Google 翻译中降低性别表述偏差的可扩展方法
文 / 高级软件工程师 Melvin Johnson,Google Research
用于语言翻译的机器学习 (ML) 模型可能会因其训练数据中潜在的社会偏见而产生同样的偏差。性别表述偏差即是其中一例:在对区分性别的语言和不分性别的语言之间进行翻译时,翻译结果中存在性别表述偏差的情况往往更加明显。例如,Google 翻译之前会将土耳其语中的“他/她是一名医生”翻译为阳性形式,而将“他/她是一名护士”翻译为阴性形式。
Google 的 AI 原则强调了避免产生或强化不公平偏差的重要性,依据这一原则,我们于 2018 年 12 月宣布推出了区分性别的翻译功能:在进行源语言未区分性别的翻译查询时,Google 翻译的这一功能将提供阳性和阴性两种翻译选项。在这项研究中,我们开发了一种三步法,即检测未区分性别的查询、生成区分性别的翻译,然后检查翻译准确性。我们之前使用此方法对土耳其语到英语的短语和句子翻译启用了区分性别的翻译功能;现在,我们已将该方法扩展至英语到西班牙语的翻译,这也是 Google 翻译中最受欢迎的语言对。
AI 原则
https://ai.google/principles/三步法
https://www.tdcommons.org/dpubs_series/1577/
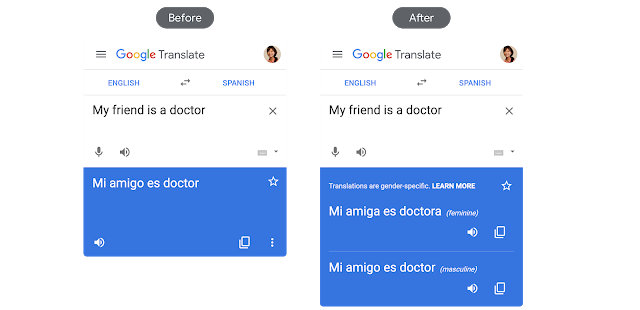
左图:将未进行性别区分的英语短语翻译成区分性别的西班牙语(早期示例)。此示例中仅出现一个有偏差的翻译结果。右图:新的翻译功能提供阴性和阳性两种翻译选项
但是,随着将这种方法应用于更多语言,我们发现扩展过程中出现了十分明显的问题。具体来说,使用神经机器翻译 (Neural Machine Translation,NMT) 系统独立生成阳性和阴性翻译结果的召回率 (Recall) 很低,会使符合条件的查询中有近 40% 查询无法显示区分性别的翻译结果,这是由于除了与性别相关的现象以外,这两种翻译结果通常并不完全相同。此外,在建立用于检测每种源语言性别中立性的分类器时,需要用到大量数据。
今天,随着英语到西班牙语全新性别区分翻译功能的发布,我们还宣布推出一种改进方法。该方法使用了截然不同的范例,通过对初始翻译结果进行重写或译后编辑来解决性别表述偏差问题。这种方法更具可扩展性,尤其是在从未区分性别的语言翻译成英语时表现更好,因为在此期间无需使用性别中立检测器。借助这一方法,我们将可区分性别的翻译功能扩展到了芬兰语、匈牙利语和波斯语到英语的语言对翻译。我们还使用基于重写的新方法替换了先前的土耳其语到英语的翻译系统。
基于重写的性别区分翻译方法
在基于重写的方法中,第一步是生成初始翻译结果。接着,对翻译结果进行审核,从中找出由不分性别的源语言短语生成区分性别的翻译结果的实例。若找到符合要求的实例,我们将使用句子层级的重写器来生成另一个区分性别的翻译结果。最后,对初始和重写的翻译结果进行审核,确保二者之间仅存在性别方面的差异。

上排:原始方法,下排:基于重写的新方法
重写器
构建重写器需要生成数百万个由成对短语组成的训练示例,且每对短语都要包含阳性形式和阴性形式两种翻译结果。由于此类数据不易获得,我们为此专门生成了一个新数据集。首先,我们创建一个庞大的单语数据集,然后以编程方式生成候选的重写结果,也即,将区分性别的代词从阳性形式转换为阴性形式,或从阴性形式转换为阳性形式。由于根据上下文的不同可能存在多个有效的候选重写结果(例如,阴性代词“她”可以映射为“他”或“他的”,而阳性代词“他的”可以映射为“她”或“她的”),因此需要确立一种用于选择正确重写结果的机制。为解决此问题,我们可以使用语法解析器或语言模型。由于语法解析模型需要使用每种语言的带标签数据集进行训练,所以其可扩展性要低于可采用非监督式学习的语言模型。基于此,我们使用经过数百万英语句子训练的内部语言模型来选择最佳候选重写结果。
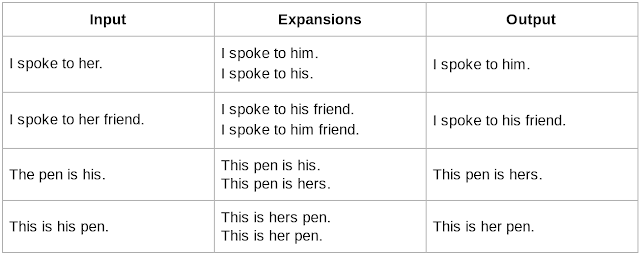
此表格演示了数据生成流程:首先输入内容,然后生成候选结果,最后使用语言模型选出最佳结果
上述数据生成流程能够产生从阳性形式输入转换为阴性形式输出(或反向转换)的训练数据。我们合并了两种转换方向上的数据,并使用此类数据训练了一个基于转换器的单层序列到序列模型。我们在训练数据中引入了标点符号和大小写变体,以提高模型的鲁棒性。最终模型能够在 99% 的时间内稳定生成所需的阳性形式或阴性形式重写结果。
基于转换器
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
评估
我们还设计了一种称为 “减少偏差”的新评估方法, 用于衡量新翻译系统与现有系统之间的相对偏差减少量。我们所说的“偏差”是指在源语言不分性别的情况下,做出翻译结果的性别选择。例如,如果当前系统在 90% 的时间内出现偏差,而新系统在 45% 的时间内出现偏差,则可得出相对偏差的减少量为 50%。基于这一指标,新方法可将匈牙利语、芬兰语和波斯语到英语的翻译偏差减少 90% 及以上。与现有土耳其语到英语的翻译系统相比,新方法可将偏差减少量从 60% 提升至 95%。我们的系统在触发区分性别的翻译结果时,平均精度达到 97%(也即,当我们决定显示区分性别的翻译结果时,有 97% 的时间都能显示正确结果)。
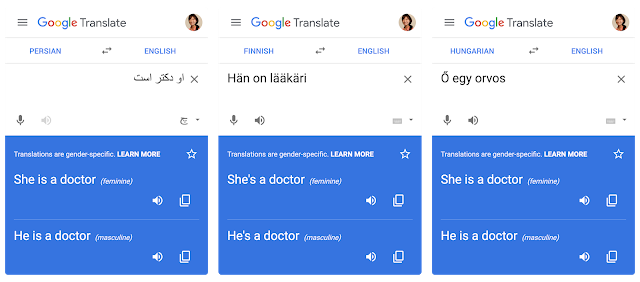
自系统发布以来,我们已取得重大进展,不仅提高了区分性别的翻译结果质量,还将其扩展到了其他 4 种语言对。我们还将继续努力,以进一步解决 Google 翻译中存在的性别偏差问题,并计划将这项研究拓展至文档级翻译领域。
致谢
这项成果离不开许多人的辛勤工作,包括但不限于以下人士(按姓氏字母排序):Anja Austermann、Jennifer Choi、 Hossein Emami、 Rick Genter、 Megan Hancock、 Mikio Hirabayashi、Macduff Hughes、Tolga Kayadelen、 Mira Keskinen、 Michelle Linch、Klaus Macherey、 Gergely Morvay、 Tetsuji Nakagawa、Thom Nelson、Mengmeng Niu、Jennimaria Palomaki、Alex Rudnick、Apu Shah、Jason Smith、Romina Stella、Vilmos Urban、Colin Young、Angie Whitnah、Pendar Yousefi 和 Tao Yu。
更多 AI 相关阅读:







