经典文章推荐-《迁移学习-该做的和不该做的》

如果你最近开始从事深度学习,尤其是图像识别方面的工作,你可能已经在网上看到了大量的博客文章,承诺教你如何在一个现代图形处理器上用十几行或更少的代码,只用几分钟就能建立一个世界级的图像分类器。令人震惊的不是承诺,而是大多数教程最终都实现了承诺。这怎么可能呢?对于那些受过“传统”机器学习技术训练的人来说,为一个数据集开发的模型可以简单地应用于另一个数据集的想法听起来很荒谬。
答案当然是迁移学习,这是深层神经网络最迷人的特征之一。在这篇文章中,我们将首先看看什么是迁移学习,什么时候它能起作用,以及为什么在某些情况下它不能起作用,最后给出一些迁移学习最佳实践的建议。
什么是迁移学习?
Pan和Yang(2010)在他们关于这个主题的开创性论文中给出了迁移学习的一个优雅的数学定义(见2.2小节)。然而,就我们的目的而言,一个简单得多的定义就足够了:迁移学习使用为特定任务(有时称为源任务)所学的知识来解决不同的任务(目的任务)。当然,假设源任务和目标任务非常相似。这一假设是迁移学习的核心。因此,我们必须首先理解为什么迁移学习首先起作用。
你可能还记得,典型的当代神经网络-比方说,多层卷积深度神经网络(cDNN)-由神经元层组成,每个神经元层根据训练结果计算出的网络权重和偏差来反馈其结果。这种架构是根据人脑中与此相当相似的一个特定过程形成的,即Ventral Visual Stream。
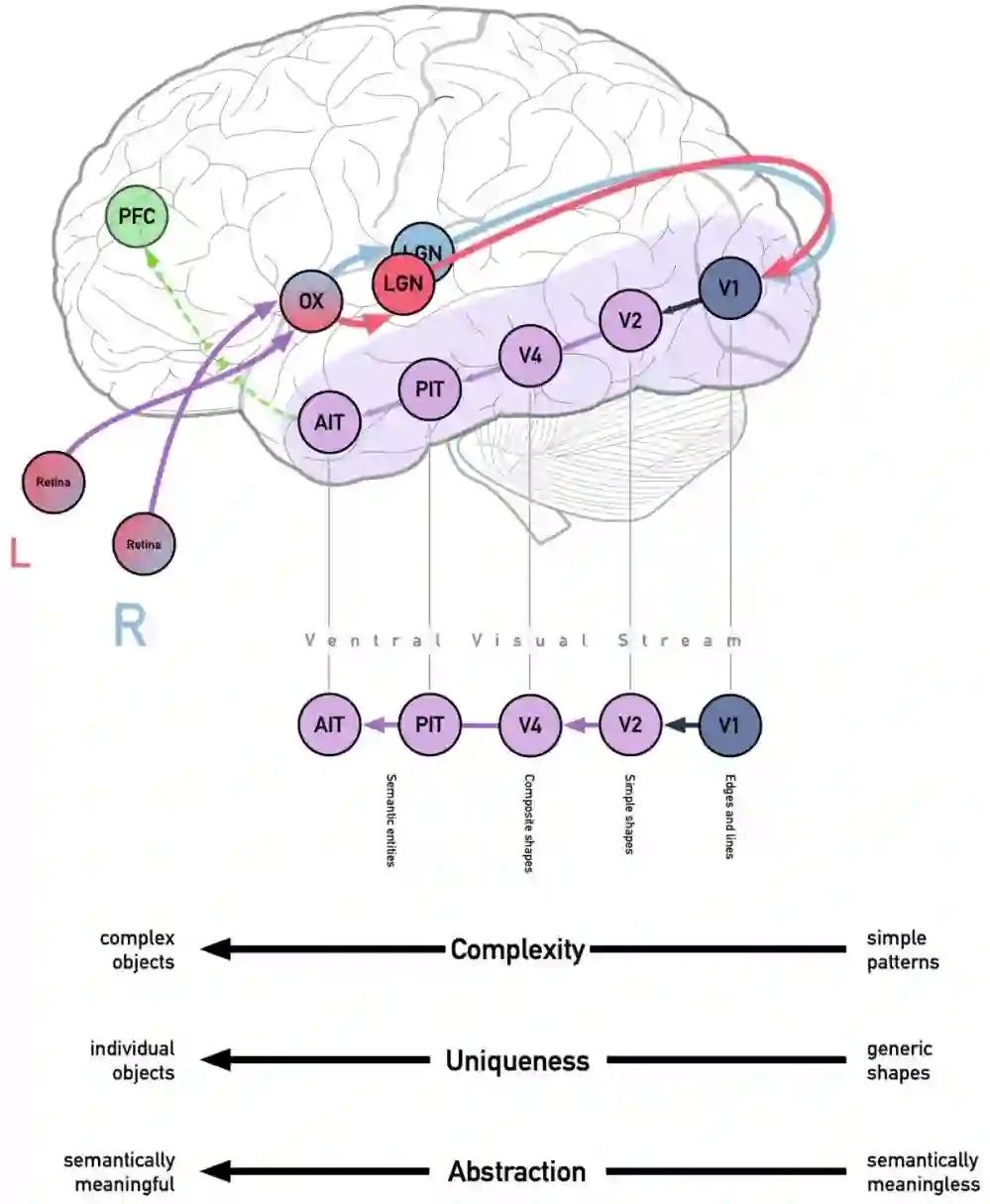
Ventral视觉流的概述。视觉神经(深紫色)将来自视网膜两侧的信息传送到视觉交叉(OX),在那里它们根据来自视野的左侧还是右侧而被分开。外侧膝状体(LGN)将输入类型分开。LGN两侧的投影进入相应的主视区(V1)。从那里,它以越来越复杂和语义化的方式穿越Ventral视觉流。
Ventral流始于初级视皮层或V1,即枕叶的一部分。V1接收来自外侧膝状体的视觉信息,这是丘脑的一部分,向枕叶发送光学信息,同时将其分成两类信息-对确定你正在看什么更有用的输入(LGN的小细胞层)和对确定某物在哪里更有用的输入(LGN的大细胞层)。两者最终都在初级视觉皮层,但Ventral视觉流是由来自LGN小细胞层的“where”信息提供的:来自视网膜神经节细胞(称为P细胞)的关于物体的缓慢但持续的详细信息。
P细胞的输出(有时称为投射)随后在穿过Ventral视觉流时被处理,从V1穿过V2、V4,最终到达下颞叶。通过兴奋实验发现,虽然V1的细胞对非常简单的模式(主要是边缘、方向、颜色和空间频率)做出反应,但V2对更复杂的概念做出反应,包括某些格式塔现象,如“主观轮廓”。最终,神经元逐渐进入下颞叶,对越来越复杂的模式做出反应。

CaffeNet的猫识别器,由DeconvNet逆向工程设计。请注意,随着层数的增加,语义也在增加,从卷积层1中的简单几何图形到上下文2中的几何图形、复合几何图形(CL3和CL4)到对象类语义上有意义的特定过滤器(CL5)。图像来自于Qin等人(2018年)。
我们看到这在深层神经网络中被复制。一种被称为泽勒-弗格斯deconvolutional的技术让我们能够看到特定层(在本文中通常被称为“过滤器”)最能响应(激活最大化)-也就是说,最能激发特定神经元的“种类”结构(你可能熟悉谷歌DeepDream算法中的一些形状)。随着层数的增加,形状的复杂性也会增加。虽然我们在第一层看到简单的边缘,甚至是颜色块,但后面的层显示出更复杂的图案,最后一层的激活通常被认为是预期的类别。它们也变得越来越语义化-线的组合被一起加权,作为识别三角形的过滤器
三角形过滤器能识别两只耳朵,与其他过滤器结合,它开始识别狗的脸和猫的脸。
传递学习的思想是固有的,因为神经网络是分层独立的-也就是说,你可以在特定层之后移除所有层,用不同数量的神经元和随机权重栓在完全连接的层上,并得到一个工作的神经网络。这是迁移学习的基础。在迁移中学习,我们使用训练有素、构建良好的网络在大型设备上所学到的知识,并将其应用于小型设备上提高检测器的性能(通常提高几个数量级!)数据集。
迁移还是不迁移
从上面可以看出,迁移学习在某些场景下起作用,有些却不一定。迁移学习的最大好处在于目标数据集相对较小。在许多这种情况下,模型可能倾向于过拟合,数据扩充可能并不总能解决整个问题。因此,当源任务的模型在比目标任务更大的训练集中训练时,迁移学习得到了最好的应用。这可能是因为特定事物的实例很难获得(例如,当致力于合成或识别只有很少样本存在的声音时),或者标记实例很难获得(例如,在放射诊断学的情况下,标记图像通常很难获得,尤其是在罕见的情况下)。
如果存在过拟合风险,每个任务的数据量大致相同的模型仍可能受益于迁移学习,这种风险通常发生在目标任务是高度特定于领域的。事实上,在训练一个大的领域特定的DCNN可能会适得其反,因为它可能会过度到特定的领域。总的来说,在源任务和目标任务的训练集大小相同的情况下,有时使用迁移学习是明智的。
实际上,在计算机视觉领域,使用经过大量图像数据集训练的黄金标准网络非常普遍,例如图像网120万张超过1000个类别的图像甚至是非特定领域的任务,如评估胸片。许多现代机器学习包,特别是像Caffe、fastai和keras这样的高级包,都有它们自己的内置的model zoo,可以方便地访问预先训练好的DCNN。因此,这仅仅是移除最顶层、添加一个或多个新层以及重新训练(微调)模型的问题。新模型将立即受益于数周的艰苦训练,这些训练是为了创建像ResNet50这样的模型,NASNet或Inceptionv3。总的来说,如果使用得当,
迁移学习会给你带来三大好处:更高的起始精度、更快的收敛速度和更高的渐近精度(训练收敛的精度水平)。最近,一些相当有前途的网站涌现出来,对各种预先训练好的模型进行分类-我最喜欢的是模型仓库(Model Depot)和ModelZoo,后者有一个可以通过框架和解决方案过滤的庞大数据库,包括许多预先训练好的GANs。
一些最佳实践
大多数深度学习框架允许你“有选择地解冻”深度神经网络的最后n层,剩下的部分将被冻结。总的来说,这个特性并不像最初听起来那么有用。经验表明,花时间进行彻底的model introspection并试图确定在哪里切断解冻几乎是不值得的。一个例外是,如果你正在训练一个可能不适合你的GPU内存的非常大的网络,在这种情况下,资源限制将决定你能够解冻多少。
与其解冻特定的层,使用不同的学习速率可能是更好的主意,其中学习速率是基于每层来确定的。底层将具有非常低的学习率,因为这些概括得非常好,主要响应边缘、斑点和其他琐碎的几何形状,而响应更复杂特征的层将具有更高的学习率。在过去,2:4:6规则(10的负幂)对我来说非常有效-对最底层的几层使用10^-6学习率,对其他传输层使用10^-4学习率,对任何其他层使用10^-2学习率。我还听说过其他人使用不同架构的2:3:4:5:6或2:3:4。对于ResNet及其衍生产品,我总是觉得2:4:6比2:3:4更舒服,但我绝对没有经验证据支持这一点。
通过retraining任何层次来进行迁移学习并不总是一个好主意。如果目的地任务基于一个小数据集,然而该数据集非常类似于网络所训练的数据集(例如,识别图像网训练的结果50中没有包括的一个新的动物或车辆类别),保持权重不变,并且在输出概率之上放置一个线性分类器可能更有用,在不冒过拟合风险的情况下产生大致相似的结果。
当迁移到具有相对较大数据集的任务时,你可能希望从头开始训练网络(这将使它根本不会迁移学习)。与此同时-假设这样一个网络将被随机值初始化,那么通过使用预先处理的权重,你不会有任何损失!解冻整个网络,移除输出层,用与目标任务类数量匹配的输出层替换,并微调整个网络。
最后:知道你在用什么。意识到自己正在从什么样的网络迁移不仅仅是一种好的做法,也是一种重要的深度学习手艺。虽然像ResNet这样普遍信任的主要工具已经被反复证明是构建良好的,但是坚实的网络,选择一个适合你的任务的网络,并且如果存在的话,可能是几种选择中最有效率的,正是深度学习专业人士获得高薪的原因。如果使用非标准网络-任何没有数百个同行评审应用程序的都被视为非标准网络-请放心,网络架构是合理的,确实是最佳选择。像TensorFlow图形网络可视化工具或Caffe的原型文本格式的神经网络网络观测器(如果你只是想玩玩,Yang Lei有一个有趣的拖放原型文本编辑器)这样的工具可以很好地洞察神经网络的内部,并有助于评估网络架构。当使用一个不熟悉的网络时,我也发现了内省,包括解除虚拟网络或其他逆向工程解决方案观察层和神经元水平的激活最大值会有很大的好处。
往期精品内容推荐
2019年最新-深度学习、生成对抗、Pytorch优秀教材推荐
Tensorflow官方视频课程-深度学习工具 TensorFlow入门
机器学习圣经《模式识别与机器学习(PRML)-2018》pdf分享



DeepLearning_NLP


深度学习与NLP
商务合作请联系微信号:lqfarmerlq




