【迁移学习】大数据时代下的迁移学习--- 机器学习的下一个前沿
什么是迁移学习?
为什么现在需要迁移学习?
迁移学习的定义
迁移学习的应用场景
迁移学习的应用
从模拟仿真中学习
适应新的领域场景
跨语言转化知识
迁移学习方法
使用预先训练的CNN得到的特征
学习域不变的表示
使表示更相似
令人困惑的域
相关研究领域
半监督学习
更有效地使用可用的数据
提高模型的泛化能力
使模型更健壮
多任务学习
持续学习
零数据学习
结论
近年来,我们在训练深度神经网络从大量的标记数据(图片、句子、标签预测等)中获取非常精确的输入输出映射关系上取得了巨大的进展。
但是,我们的模型还欠缺着对与训练过程中遇到的不同的情况的归纳能力。当你将你在特定构造的数据集下训练得到的模型放到真实世界中测试时就会发现这一点的重要性。真实世界与单调的数据集不同,充斥着无数数据集中没有覆盖的场景,而你不可能把所有的场景都提供给模型训练之后再让模型进行预测。而将从有限数据集中学习到的知识转移到这种没有覆盖到的场景中的能力就成为迁移学习,本文的讨论也将围绕它展开。
在本文中,首先将会拿迁移学习与机器学习中应用最广泛、成功的范例——监督学习进行对比。然后分析为什么迁移学习值得我们关注,提出迁移学习的更技术性的定义和迁移学习不同的具体应用场景。在提供具体的应用实例之后,我们会深入讨论可以应用与迁移学习的实用方法。最后,我会对相关的研究领域进行简要介绍并做未来展望。
在机器学习经典的监督学习场景中,如果我们需要在域A中训练一个模型去完成某些任务,我们会假设我们已经拥有了与这个域以及任务相对应的标记数据集。就像下图展示的一样,模型A的测试数据以及训练数据对应的域以及任务都是相同的。(后面我们会对任务以及域做出具体的定义)现在,我们可以先做一个简单地假设:任务就是我们的模型要达到的目的,比方说从图片中识别出物体;而域就是我们数据来源的地方,比方说我们的照片是来自于旧金山的咖啡店。
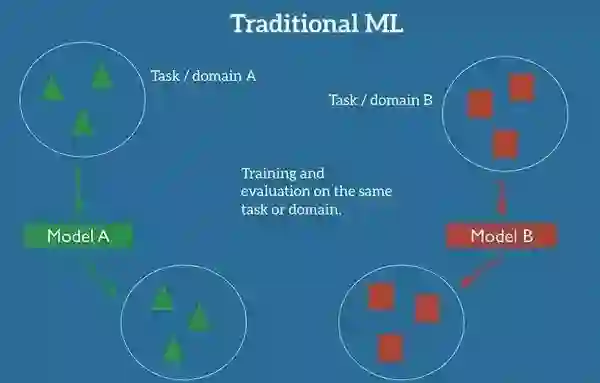
ML中传统监督学习的设定
注解:Traditional ML:传统机器学习,Task/Domain: 任务/域, Model: 模型,Training and evaluation on the same task or domain: 在同一任务或域下训练和验证模型。
现在我们可以训练一个模型A,并且要求他在这个域和任务中对于训练集中未出现的数据也可以保持很好的泛化能力。现在假想另一个场景,我们需要在域B中训练一个模型去完成一些其他的任务,那么我们像之前一样需要同样与之对应的标记数据集来训练在B域具有良好泛化能力的模型B。
然而,并不是什么时候我们都有着对应特定域的足够标记数据的,这时像上图一样的传统监督学习范式就不适用了。
举一个具体的例子:如果我们想基于夜间的图像训练一个模型去检测行人,我们希望利用一些相似域下训练得到的模型。(比方说在日间图像基础上训练好的模型)然而在实践中,由于在特定数据集下训练的模型已经习惯于训练集中的数据偏置,在面对来自新域中的输入数据时,模型的归纳能力会明显下降甚至崩溃。
上面的例子还是相对简单的,因为输入数据的不同还只是体现在输入参数的不同上,而如果再麻烦一点,比如说我们只想检测出骑着自行车的人,那我们之前训练得到的日间检测行人的模型甚至都没有了重用的可能性,因为原数据集上的标签都需要变动。
迁移学习是我们能够利用相关任务或域的数据来解决当前场景下的问题。我们可以将从设定的源域中获取的知识应用于我们感兴趣的目标域。
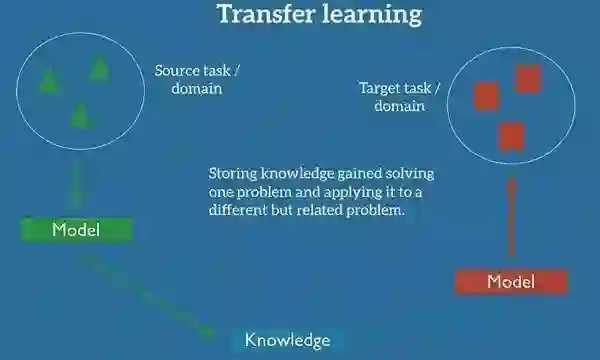
迁移学习的设定
注解:Transfer Learning: 迁移学习,Storing knowledge gained ... problem: 把从解决一个任务中获得的知识存储下来并且迁移到另一个与之相关但又有所区别的问题上
在实践当中,我们会尝试将尽可能多的知识从源域转化至目标任务或域。根据数据的不同,我们采取的知识形式也是不同的:可以涉及对象的组成,这可以使新的对象的识别变得更加容易;也可以是人们用于表达观点的一般数据,等等。
斯坦福大学教授Andrew Ng在他广受欢迎的NIPS 2016教程中表示,迁移学习将会继监督学习之后成为机器学习商业成功的下一个推动力。

Andrew Ng在NIPS 2016上关于迁移学习的观点
注解: “迁移学习会成为机器学习成功的下一个驱动力” Andrew Ng,NIPS教程 2016
特别是,他在白板上画出了一张图表,我尽可能忠实地复制后得到了下面的图(对于未标记的坐标轴感到抱歉)。按Andrew Ng的话说,转移学习将成为机器学习在行业中取得成功的关键因素。
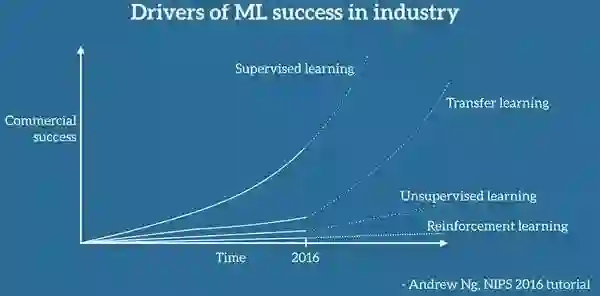
Andrew Ng提出的驱动机器学习在工业成功的因素
注解:表标题:机器学习在行业成功中的驱动力,Supervised learning: 监督学习,Transfer learning: 迁移学习,Unsupervised learning: 无监督学习,Reinforcement learning: 强化学习,横轴:时间,纵轴:经济效应
毫无疑问,迄今为止,机器学习在工业界的使用和成功主要是由监督学习推动的。在深度学习、功能更强大的计算工具和大量标记数据集的推动下,监督学习再次提起了人们对AI的兴趣,掀起了融资和收购的浪潮,尤其是近几年机器学习的应用越来越广,逐渐成为了我们生活的一部分。如果我们忽视反对者和质疑者提出的下一次AI寒冬的到来而是相信Andrew Ng的预测,也许机器学习的成功将会继续延续下去。
但是事实并不明朗,事实上迁移学习的概念已经存在了几十年但是在工业中的应用屈指可数,是否会如Andrew Ng所说,它会在未来出现爆炸式的增长呢?相对于机器学习的其他领域(无监督学习、强化学习),迁移学习的关注度要更低一些。而无监督学习和强化学习的欢迎度在逐渐上升:无监督学习——Yann LeCun提到的寻求通用AI的关键因素可以看出人们对监督学习兴趣的增长,尤其是生成敌对网络;Google DeepMindze则利用强化学习大大提升了游戏AI的水平,AlphaGo的成功印证了这一点,除了游戏之外,这一成功也应用在了Google的数据中心冷却技术上,节省下了40%的费用,不过虽然这两个领域有希望,但是在短期并不能产生很大的商业影响,仍然还停留在尖端的研究报告中,有着很多挑战需要解决。

Yann LeCun的蛋糕问题显然与迁移学习没有关系
注解:从上至下机器需要多少信息来进行预测?
单纯的增强学习(樱桃)——一些样本中的一些Bit;监督学习(刨冰)——每个样本10-10000Bit;无监督学习(蛋糕)——每个样本百万Bit
是什么使迁移学习与众不同?接下来,我们分析一下(从我们的角度)是什么因素促使 Ng 做出了这样的预测以及我们现在需要关注迁移学习的原因。
我们可以从两个方面来审视一下当前机器学习在行业中的应用现状:
一方面,在过去的几年中,我们训练得到的模型越来越精确。我们现在需要用它去完成各种各样的任务,最先进的模型的性能已经达到了用户几乎感觉不到它的细微提升的程度。这是什么概念呢?ImageNet上最新的残差网络[1]在识别物体的能力上已经超越了人类;Google的智能回复[2]可以自动处理所有回复中的10%;语音识别的错误率逐渐下降,低于人类打字的错误率[3];我们可以借助机器学习来像皮肤科医生一样诊断皮肤癌;Google的神经机器翻译系统[4]已经应用在十种以上的语种之上;百度可以实时生成像人类一样生动的演讲;机器学习能做的事情在变得越来越多,这些模型已经足够成熟,可以大规模部署来服务数百万的用户。
另一方面,这些模型的精确程度极度依赖于数据,模型性能的提升需要大量的标记数据。在一些任务和域中,这些数据时可用的并且已经经过了多年的精心整理。在少数的情况下这些数据数据时公开的,比如说ImageNet[5],但是更多的标记数据是专有或者昂贵的,因为这些数据一定程度上也代表了行业中的竞争力。
与此同时,在机器学习模型真正应用于真实世界中时面临的是无数之前没有遇到过的情况并不知道怎样去处理这些情况;每个客户端和每个用户都有着他们各自的性能指标,拥有或者产生着与训练数据集中不同的数据;每个模型在应用中都需要处理这些与训练过程中相似但又不是完全相同的任务。在所有的情况下,即使是在训练集上有着接近或者超越人类水平的模型在性能上也会有着明显的下降甚至在某些场景下会变得完全不可用。
而迁移学习可以帮助我们处理这些新的情况,这在机器学习应用于那些标记数据并不是很丰富的域时尤为重要。到目前为止,我们已经将模型应用于了那些具有丰富数据积淀的任务和域,这并不困难。但是为了服务于长尾部分(长尾效应,二八法则),我们需要将模型已经获得的知识迁移至新的任务与域当中。
为了做到这一点,我们要了解迁移学习设计的概念。下面的部分中我们会为此给出更技术性的定义。
对于迁移学习的定义,我们将以 Pan and Yang (2010)[6] 对二进制文本分类的优秀研究为例来进行讲解。
迁移学习涉及到了域和任务的概念。域D由一个特征空间X和特征空间上的边缘概率分布P(X)组成,X = x\_1, ... , x\_n \in \chi。以文本分类为例来说,\chi是所有文本代表的特征空间,x\_i是对应文本中的第i项的矢量,X是训练时使用的文本样本。
给定一个域,D = {\chi, P(X)},任务\mathcal{T}由标签空间\mathcal{Y}和从包含x\_i \in X和y\_i \in \mathcal{Y}组合的训练数据中获得的条件概率分布P(Y|X)组成。在文本分类的例子中,\mathcal{Y}是所有标签组成的集合,由于y\_i只能是True或False,所以\mathcal{Y} = {True, False}
此时,之前迁移学习要解决的问题就可以表述为:给定一个对应于源任务\mathcal{T}\_S的源域\mathcal{D}\_S以及目标域\mathcal{D}\_T和目标任务\mathcal{T}\_T(\mathcal{D}\_S \neq \mathcal{D}\_T, \mathcal{T}\_S \neq \mathcal{T}\_T),要从源任务\mathcal{T}\_S和源域\mathcal{D}\_S中提供的信息中学习得到目标域\mathcal{D}\_T中的概率分布P(Y\_T|X\_T)。在迁移学习的大多数场景下,可用的目标域的标记样本远远小于源域。
域\mathcal{D}和任务\mathcal{T}均被定义为元组,而源域和目标域中它们的不等价就产生了4种机器学习场景,下面我们对这四种情景进行讨论
给定源域\mathcal{D}\_S和目标域\mathcal{D}\_S(\mathcal{D} = {\mathcal{X},P(X)})以及源任务\mathcal{T}\_S和目标任务\mathcal{T}\_T(\mathcal{T} = {\mathcal{Y}, P(Y|X)}),源和域满足的条件可以有四种,下面我们还是以文本分类为例来说明:
\mathcal{X}\_S \neq \mathcal{X}\_T。源域和目标域的特征空间是不同的,比如说文本是用两种不同的语言编写的。在自然语言处理中,这通常被称为跨语言适应。
P(X\_S) \neq P(X\_T)。源域和目标域的边缘概率分布是不同的,即源域和目标域的文本讨论的是不同的主题。这种情况被称为域适应。
\mathcal{Y}\_S \neq \mathcal{Y}\_T。两个任务之间的标签空间是不同的,即同一个文本需要在目标任务中被分配以不同的标签。在实践中,通常发生的是场景4,因为两个不同的任务具有不同的标签空间,但具有完全相同的条件概率分布的情况是十分罕见的。
P(Y\_S|X\_S) \neq P(Y\_T|X\_T)。源和目标任务的条件概率分布是不同的,即源文件和目标文件在类别方面是不平衡(某些类别的样本数量极多,而有些类别的样本数量极少)的。这种情况在实践中相当普遍,过采样,欠采样或SMOTE过采样[7]算法这些被广泛使用的方法都是为了解决这一问题。
现在,我们已经明白了迁移学习的概念和迁移学习应用的场景,下面我们来看一下迁移学习的不同应用以及迁移学习的潜力所在。
从模拟中学习这是一个让我感到很振奋的迁移学习的应用并且我猜想在未来会有越来越多的模型是从模拟中学习得来。因为对于很多依赖于实物或者硬件进行交互的机器学习应用来说,在真实世界中收集数据和训练模型不是很昂贵、耗时就是存在危险。所以就需要一些风险成本较小的收集数据方式。
而仿真就是这方面应用的首选,实际上它也应用在了很多先进的机器学习系统上。将从仿真中习得的知识迁移到真实世界中时,源域和目标域的特征空间是一致的(通常都依赖与获得图像中的像素单元的状态),但是源域和目标域的边缘概率分布是不同的。(虽然是仿真,但是源域和目标域的物还是有着差异的,而且物理引擎并不能模拟真实世界中的所有复杂交互),这种场景对应的就是上面提到的迁移学习场景中的第2种。

Google自驾车
(来源:Google Research博客)
在模拟中学习的一大好处是可以更加方面地收集数据,在保证快速学习的前提下还可以轻松地添加或者分析仿真中的物体,也使模型在不同实例下的并行训练成为了可能。由此,仿真是大型机器学习项目在真实世界中进行测试的先决条件,自动驾驶汽车就是一个很好的例子。Google自动驾驶汽车的技术负责人 Zhaoyin Jia 就说过:“如果你想真的坐一辆可以自动驾驶的汽车,那么仿真是必不可少的”。优达学城已经开源了模拟器,它用于无人驾驶工程师的纳米学位教学(图7),OpenAI's Universe未来可能会允许使用GTA 5或者其他视频游戏来训练自动驾驶汽车。

Udacity自动驾驶汽车的模拟器
(来源:TechCrunch)
仿真以关键角色出现的另一个应用是机器人技术:用真正的机器人去训练模型不仅慢,而且训练成本也很昂贵。而从模拟中学习之后在将习得的知识迁移到真实世界中一定程度上缓解了这一问题,这也使得它在近期得到了更多的关注[8]。下图分别展示了机器人在真实世界和仿真中完成操作任务的图像。

真实世界中的机器人和仿真图像(Rusu等,2016)
最后一提,仿真也是实现通用AI道路上不可或缺的一部分。直接在真实世界中训练得到通用AI的成本太高,而且上来就会受到真实世界中一些并不是很关键的因素影响而提升问题的复杂度。相反地,如果基于仿真环境(像下图展示的CommonAI-env)[9]开始训练则更容易取得成功。

Facebook的 CommAI-env(Mikolov等,2015)
虽然从仿真中学习已经是域适应中的一个具体的实例了,但是我们还是值得概括一些其他域适应的例子。
在机器视觉中,域适应是一个常见要求,因为带有标注的数据集很容易取得,但是获得的数据集和我们最终应用的数据集来源的域往往是不同的,就像下图展示的一样。虽然训练数据和测试数据看起来差别并不大,但是训练集中包含的人类难以察觉到的偏差将会影响到模型的训练[10]。
不同的视觉域(Sun et al., 2016)
另一个常见的域适应的场景是适应不同的文本类型:标准的NLP工具(词性标注器或解析器)通常在华尔街日报等新闻数据(曾经被用于评估这些模型)上进行训练。然而,在新闻数据上训练得到的模型在面对来自像Twitter一样的社交媒体中新的文本类型时就显得力不从心了。

不同的文本类型
即使是在产品评论这样一个领域中人们也会用不同的词语来表达相同的意见。因此,在一种评价上训练得到的模型应当能够识别人们通常使用的和特定域使用的表达意见的词汇,以免被域的切换所迷惑。

不同的主题
虽然上述挑战已经设计了一般的文本或图像类型,但是如果我们考虑到与个人或用户群体相关的域,这个问题还会被进一步放大:自动语音识别(ASR)。语音有望成为下一个大平台,据研究进度推测,在2020年将会有50%的搜索是通过语音进行。大多数ASR系统还是在Switchboard语料库上进行检验,这意味着有口音的人也是可以被识别出的,然而移民、有着非标准口音或者有语言障碍的人则很难识别。现在,为了确保每个人的声音都可以被识别,我们急需一个可以适应个人用户或少数群体的语音系统。
最后,虽然上述挑战涉及一般的文本或图像类型,但如果我们考虑与个人或用户群体有关的域,则问题会被放大:考虑自动语音识别(ASR)的情况。语音有望成为下一个大平台,预计到2020年,我们所有搜索中的50%预计将通过语音进行。大多数ASR系统在传统上由交换板数据集评估,该数据集由500个扬声器组成。大多数有口音的人是幸运的,而移民,非标准人士,有言语障碍的人或孩子则难以理解。现在我们比以往任何时候都需要能够适应个人用户和少数群体的系统,以确保每个人的声音都能被听到。

Google Assistant和亚马逊的Echo可以处理不同的口音
最后,我认为将我们从一种语言学习中获得的知识迁移到另一种语言上将成为迁移学习的另一个杀手级应用.可靠的跨语言适应方法可以让我们充分利用当前拥有的大量带有标注的英文数据并将之应用于任何语言,特别是一些缺少语料库和常规方案难以奏效的语言,但是从当前的最新研究进展来看,这个方案仍然是乌托邦式的,不过之前的一些进展,如零数据翻译[11],已经在这个领域有了飞速的发展。
到目前为止,我们已经考虑了转移学习的具体应用和面临的挑战,现在我们来看看文献中用于解决一些之前提出的挑战的实际方法和方向。
迁移学习有着悠久的研究历史,有着处理上述四种迁移学习场景的技术。同时深度学习的出现带来了一系列新的学习方法,其中一些我们将在下面进行介绍。如果对早期方法感兴趣,请参阅文献索引6。
为了理解目前最常用的转移学习方式的来源,我们必须首先了解在ImageNet上大型卷积神经网络取得巨大成功的原因[12]。
虽然这些模型很多细节的工作原理还是一个谜,但是我们现在意识到较低的卷积层可以捕获一些低阶的图像特征,如边缘(见下图),高阶的卷积层可以捕捉更复杂的细节,如身体部分,面部和其他组成特征。

由AlexNet学习的卷积核示例(Krizhevsky et al. ,2012)
而最终的全连接层通常假设用于捕获与解决任务相关的信息,以AlexNet为例,它的全连接层指出了将图像分类到某一具体类别下与哪些特征相关。
然而,虽然在识别动物为一只猫的过程中知道猫有胡须、爪子、毛皮等特征是必要的,但是这并不能帮助我们识别新的物体或者说解决一些常见的机器视觉场景,比如细粒度识别,属性检测和图像检索等任务。

真正对我们有帮助的不是上一段提到的高阶特征,而是能够帮助我们捕获图像构成的一般特征以及图像中的边缘和形状组合的表示层。关于这些低阶特征,上面已经提到过,这些信息一般被包含在一个最终的卷积层或者在像ImageNet这样大型的网络中的早期完全连接层中。
对于一个新的任务,我们可以直接使用ImageNet上预先训练得到的CNN的现成特征,并且基于这些提取的特征来训练新的模型。在实践中我们会保持预先训练好的参数不变或者保持较低的学习率来避免模型遗忘之前获得的知识。这个简单的方法已经在一系列的机器视觉任务和一些依赖视觉输入的任务(视频字幕)上取得了惊人的成果[13]。在ImageNet上训练得到的模型似乎捕捉到了处理动物和图像时通常相关的结构和组成细节,因此ImageNet任务成为了一般的机器视觉问题的很好的代理(agent),因为它所需的知识与其他很多机器视觉任务也是相关的。
一个类似的假设被用于生成模型:当训练生成模型时,我们假设生成逼真的图像依赖于对图像底层结构的了解,反过来这一假设也可以用于其他任务。这一假设本省依赖于所有的图像是位于低维流形上的即我们可以通过模型提取图像的底层结构。最近利用生成对抗网络[14]产生逼真图像的最新进展表明这样的底层结构可能真是存在,由模型的显示在下图中的卧室图像空间中的点之间的现实过渡能力证明了这一点。

卧室图像合集
在机器视觉以外的领域,预训练得到的特征是否依旧有效?
在机器视觉领域,训练得到的现成的CNN特征取得了空前的效果,但是要将这一成功在其他领域(如语言)中复刻仍然有着很多问题需要解决。目前来说,现成的特征并不能使自然语言处理达到与机器视觉一样的效果。这是为什么呢?这样的特征是否存在?为什么这种形式的迁移学习更容易在视觉上而不是自然语言处理上取得成功?
在自然语言处理中,低级别的任务输出(如词性标注、分块)可以看做现成的特征,但是这些特征并不能捕捉到超越语法以外的更细粒度的语言使用规则,对于所有的任务的整体来说并没有帮助。正如我们之前看到的,一般化的现成特征是与一个任务交织在一起的,而这个特殊的任务就是该域很多任务的原型。在机器视觉中,物体识别占据了这样一个角色,在自然语言处理中,最接近的可能是语言建模:给定一个单词序列,为了预测下一个单词或句子,模型需要掌握语言结构相关的知识,需要了解那些单词与之前的序列相关并可能出现在后面,这需要长期依赖(Long-Term Dependencies)的建立。
虽然最先进的语言模型越来越接近人的水平[15],但是它们的特征都是局部适用的。不过语言建模的进步仍然为其他任务产生了积极的效应:使用语言模型作为目标来作为目标预训练模型可以提升性能[16]。除此之外,用近似语言建模在大型无标记语料库上预先训练的词嵌入已经变得非常普遍了[17]。即使不像视觉中现成的特征那样有效,这种方式仍然提供了很大的收益[18],可以看做是从大的未标记语料库中获得的一般域知识的简单形式迁移。
一般任务的代理(agent)任务在自然语言处理中仍然是未知的,但是它的辅助任务可以采取本地代理(agent)的方式。无论是多任务目标[19]还是合成任务目标[20,21],都可以被用于将额外的相关知识注入到模型当中。
使用预先训练的特征是当前迁移学习中最直接和常用的方法,但我们应当清楚这并不是唯一的方法。
利用预训练的特征通常适用于我们要适应新任务的场景3。对于其他情况,深度学习为我们提供了另一种迁移学习的方式:学习域不变的表示。这种方法与我们之前提取预训练的CNN特征在概念上是十分相似的,他们都将域中的一般知识做了编码处理。不过,创建域不变的表示对于非视觉任务来说要比生成对所有任务有用的表示来说成本更低,可行性更高。ImageNet花费了数年,数千小时来创建对所有任务有用的表示,而我们通常只需要每个域的未标记数据来创建域不变的表示。这些表示通常通过去噪的多层自编码器来实现并且已经在自然语言处理[22,23]和机器视觉[24]上取得了巨大的成功。
为了提高从源域到目标域习得的表示的可迁移性,我们希望两个域之间的表示尽可能相似,这样域中特有的特征就不再阻碍迁移学习了,我们只需要考虑域之间的共性即可。
由此,我们不仅仅希望自编码器学习一些表示,更希望它在两个域中习得的表示[25,26]具有更多的共性。我们可以将自编码器作为预处理步骤,训练得到的新的表示可以用于接下来的训练,与之类似的我们也可以让模型中域的表示具有更多的共性[27,28]。
最近越来越流行的保证两个域表示相似性的的方式是添加一个新的目标到现有的模型当中,鼓励模型混淆这两个域[29,30]。这两个域的混淆损失即一个正则化的分类损失,对应于模型对输入实例所属域的预测损失函数。它与正则化损失的区别在于由损失函数传递到网络其他部分的的梯度是相反的,如下图所示:
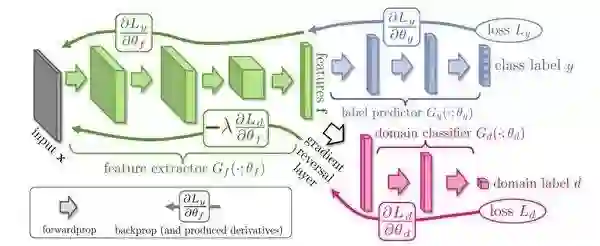
具有梯度反转层的混淆域(Ganin和Lempitsky,2015)
Feature extractor: 特征提取,feature: 特征,label predictor: 标签推测,class label: 类标签,domain classifier: 域分类器,gradient reversal layer: 梯度反转层,forwardprop:前馈,backprop: 反馈,loss: 损失
与最小化分类误差相反,梯度反转层将导致最大化的模型分类误差。在实践中意味着模型习得的表示将最小化原来的目标,使模型不能区分这两个域从而有利于知识的迁移。在下图中展示了一个只用正则化目标来进行训练的模型,在混淆之前可以根据其各自学习的特征来分离域,但是混淆之后的模型做不到这一点。
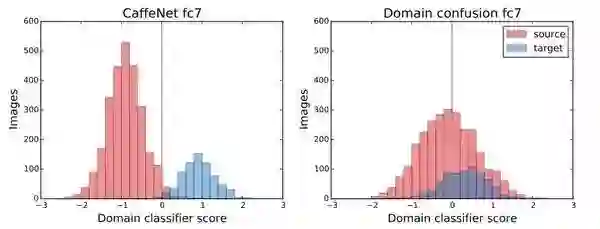
正则化和域混淆模型的域分类器得分(Tzeng等,2015)
注解: Domain classifier score: 域分类器得分
虽然这篇文章是关于迁移学习的,但是迁移学习并不是机器学习的唯一研究领域。迁移学习试图利用有限的数据和已经习得的知识来进行新的尝试以使模型更好地推广到新的环境。接下来,我们将介绍与迁移学习相关或互补的其他方向。
迁移学习的目标是利用目标任务或域中的未标记数据达到最大的效应。这也是半监督学习的目标,半监督学习虽然和经典的机器学习设定相同,但它假设用于训练的标记样本是很有限的。迄今为止,半监督的域适应本质上是在域转换下的半监督学习。因此半监督学习中很多的经验与见解在迁移学习中也同样适用,关于半监督学习,可以参见参考文献中的31。
与转移学习和半监督学习有关的另一个方向是使模型能够在有限的数据量下更好地工作。
这可以通过几种方式来实现:可以通过无监督学习或者半监督学习从未标记的数据中提取信息从而减少对标记样本的依赖;可以使模型访问数据中固有的其他特征而不是通过正则化来减轻过拟合的趋势;最后,可以利用被训练中忽略的数据或看起来并不起眼的数据来增强模型。
这种偶然的数据[32]可以视为用户生成内容时被创建的副产物,例如可以用来说明命名实体的超链接和词性标注符;它也可以是注释的副产物,就像不同的注解可以可能会提升标注或解释的质量;还可以从用户行为(眼动追踪或用户的键盘行为)中获得信息提供给NLP(自然语言处理)任务。虽然这些数据只能以有限的方式利用,但是这样的例子鼓励我们在一些之前没有留意的地方查找数据,发现新的数据检索方式。
为了使模型具有更好的泛化能力,我们首先要理解大型神经网络的行为和复杂性,并研究他们如何实现归纳和泛化以及为什么要这样做。最近的研究在这一方面已经取得了很大进展[33],但是仍然还有很多问题亟待解答。
虽然提高模型的泛化能力还有很长的路要走,但是我们已经可以很好地概括相似的实例,但是一些意料之外的输入带来的结果可能是灾难性的。因此,一个关键的补充目标是让我们的模型更加健壮。这个方向近来由于对抗学习的进展而引起了越来越多的兴趣,最近研究已经发现了很多种方法来保证模型在不同的设定下对最坏情况或对抗性情况的健壮性[34,35]。
在迁移学习中,我们主要希望在目标任务或域有好的性能。与之不同,在多任务学习中,我们希望所有的任务上都可以有好的性能。换言之,我们可以借助相关任务中习得的知识来在目标任务上达到很好的性能。更为关键的一点是,与迁移学习不同,标记数据被假设提供给所有的任务,模型也是在源和目标任务数据上共同训练,这种情况是没有出现在迁移学习当中的。这种场景下,即使训练过程中目标数据是不可用的,多任务学习中对任务的见解对迁移学习的决策也是有益的。
对于多任务学习更彻底的概述(特别是在深层神经网络中的应用),可以参见作者的博客。
虽然多任务学习可以在不对源任务造成性能损失的前提下让我们在多项任务中保留知识,但是只有所有任务同时训练时才可以达到这一效果,这意味着每当出现一个新的任务我们需要重新训练我们模型相关的所有任务。
在现实世界中我们并不希望这样做,我们希望代理(agent)可以利用过去的经验来处理日渐复杂的任务。为此,我们需要让模型可以持续学习而不会忘记之前的经验。这个机器学习领域被称为(Learning to learn)[36]让机器学会学习,元学习,终身学习或持续学习。从增强学习[37,38,39]最近的发展可以看出它的发展,尤其是Google DeepMind在寻求一般学习代理方面的研究,已经应用在了序列到序列(sequence-to-sequence)的模型上[40]。
最后,我们想象迁移学习的极限情况,每一类实例中我们只有几个、一个甚至零个实例以供学习,我们分别称之 为few-shot learning, one-shot learning(单次学习)和 zero-shot learning。机器学习中最困难的问题就是使模型一次性学习达到效果或者不经过学习就达到目标。但对于人类来说这是很常见的事情,小孩子在得知某个物体是狗的时候他(她)马上就可以识别出其他的狗,成年人可以通过阅读相关的书籍来建立对一个完全没有看到过的物体的认知。
在单次学习方面的最新进展利用了一下认知:在单次训练中,模型需要被明确地训练,这样在测试时才可以达到很好的性能[41,42]。而零数据学习中在测试数据前训练的类的设定也被研究人员所关注[43]。
总而言之,迁移学习提供了很多令人兴奋的研究方向,尤其是很多需要模型将知识迁移到新的任务或域的应用。希望我的文章可以让你能够大致了解迁移学习这一概念并能激起你的兴趣。
注意:这篇博客文章中的一些陈述是故意有些争议的。如果你对一些说法有不同的见解或者发现了一些错误请在评论中指出。
参考文献
Szegedy, C., Ioffe, S., Vanhoucke, V., & Alemi, A. (2016). Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv preprint arXiv:1602.07261.
Kannan, A., Kurach, K., Ravi, S., Kaufmann, T., Tomkins, A., Miklos, B., … Ramavajjala, V. (2016). Smart Reply: Automated Response Suggestion for Email. In KDD 2016. http://doi.org/10.475/123
Ruan, S., Wobbrock, J. O., Liou, K., Ng, A., & Landay, J. (2016). Speech Is 3x Faster than Typing for English and Mandarin Text Entry on Mobile Devices. arXiv preprint arXiv:1608.07323.
Wu, Y., Schuster, M., Chen, Z., Le, Q. V, Norouzi, M., Macherey, W., … Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv preprint arXiv:1609.08144.
Deng, J., Dong, W., Socher, R., Li, L., Li, K., & Fei-fei, L. (2009). ImageNet : A Large-Scale Hierarchical Image Database. In IEEE Conference on Computer Vision and Pattern Recognition.
Pan, S. J., & Yang, Q. (2010). A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 22(10), 1345–1359.
Chawla, N. V, Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE : Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321–357.
Rusu, A. A., Vecerik, M., Rothörl, T., Heess, N., Pascanu, R., & Hadsell, R. (2016). Sim-to-Real Robot Learning from Pixels with Progressive Nets. arXiv Preprint arXiv:1610.04286. Retrieved from http://arxiv.org/abs/1610.04286
Mikolov, T., Joulin, A., & Baroni, M. (2015). A Roadmap towards Machine Intelligence. arXiv Preprint arXiv:1511.08130. Retrieved from http://arxiv.org/abs/1511.08130
Torralba, A., & Efros, A. A. (2011). Unbiased Look at Dataset Bias. In 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Johnson, M., Schuster, M., Le, Q. V, Krikun, M., Wu, Y., Chen, Z., … Dean, J. (2016). Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. arXiv Preprint arXiv:1611.0455.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Advances In Neural Information Processing Systems, 1–9.
Razavian, A. S., Azizpour, H., Sullivan, J., & Carlsson, S. (2014). CNN features off-the-shelf: An astounding baseline for recognition. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 512–519.
Radford, A., Metz, L., & Chintala, S. (2016). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. ICLR. Retrieved from http://arxiv.org/abs/1511.06434
ozefowicz, R., Vinyals, O., Schuster, M., Shazeer, N., & Wu, Y. (2016). Exploring the Limits of Language Modeling. arXiv Preprint arXiv:1602.02410. Retrieved from http://arxiv.org/abs/1602.02410
Ramachandran, P., Liu, P. J., & Le, Q. V. (2016). Unsupervised Pretrainig for Sequence to Sequence Learning. arXiv Preprint arXiv:1611.02683.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. NIPS.
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 1746–1751. Retrieved from http://arxiv.org/abs/1408.5882
Bingel, J., & Søgaard, A. (2017). Identifying beneficial task relations for multi-task learning in deep neural networks. In EACL. Retrieved from http://arxiv.org/abs/1702.08303
Plank, B., Søgaard, A., & Goldberg, Y. (2016). Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics.
Yu, J., & Jiang, J. (2016). Learning Sentence Embeddings with Auxiliary Tasks for Cross-Domain Sentiment Classification. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP2016), 236–246. Retrieved from http://www.aclweb.org/anthology/D/D16/D16-1023.pdf
Glorot, X., Bordes, A., & Bengio, Y. (2011). Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach. Proceedings of the 28th International Conference on Machine Learning, 513–520. Retrieved from http://www.icml-2011.org/papers/342_icmlpaper.pdf
Chen, M., Xu, Z., Weinberger, K. Q., & Sha, F. (2012). Marginalized Denoising Autoencoders for Domain Adaptation. Proceedings of the 29th International Conference on Machine Learning (ICML-12), 767--774. http://doi.org/10.1007/s11222-007-9033-z
Zhuang, F., Cheng, X., Luo, P., Pan, S. J., & He, Q. (2015). Supervised Representation Learning: Transfer Learning with Deep Autoencoders. IJCAI International Joint Conference on Artificial Intelligence, 4119–4125.
Daumé III, H. (2007). Frustratingly Easy Domain Adaptation. Association for Computational Linguistic (ACL), (June), 256–263. http://doi.org/10.1.1.110.2062
Sun, B., Feng, J., & Saenko, K. (2016). Return of Frustratingly Easy Domain Adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16). Retrieved from http://arxiv.org/abs/1511.05547
Bousmalis, K., Trigeorgis, G., Silberman, N., Krishnan, D., & Erhan, D. (2016). Domain Separation Networks. NIPS.
Tzeng, E., Hoffman, J., Zhang, N., Saenko, K., & Darrell, T. (2014). Deep Domain Confusion: Maximizing for Domain Invariance. CoRR. Retrieved from https://arxiv.org/pdf/1412.3474.pdf
Ganin, Y., & Lempitsky, V. (2015). Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning. (Vol. 37).
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., … Lempitsky, V. (2016). Domain-Adversarial Training of Neural Networks. Journal of Machine Learning Research, 17, 1–35. http://www.jmlr.org/papers/volume17/15-239/source/15-239.pdf
Zhu, X. (2005). Semi-Supervised Learning Literature Survey.
Plank, B. (2016). What to do about non-standard (or non-canonical) language in NLP. KONVENS 2016. Retrieved from https://arxiv.org/pdf/1608.07836.pdf
Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2017). Understanding deep learning requires rethinking generalization. ICLR 2017.
Kurakin, A., Goodfellow, I., & Bengio, S. (2017). Adversarial examples in the physical world. In ICLR 2017. Retrieved from http://arxiv.org/abs/1607.02533
Huang, S., Papernot, N., Goodfellow, I., Duan, Y., & Abbeel, P. (2017). Adversarial Attacks on Neural Network Policies. In Workshop Track - ICLR 2017.
Thrun, S., & Pratt, L. (1998). Learning to learn. Springer Science & Business Media.
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., … Hadsell, R. (2017). Overcoming catastrophic forgetting in neural networks. PNAS.
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., ... Deepmind, G. (2016). Progressive Neural Networks. arXiv preprint arXiv:1606.04671.
Fernando, C., Banarse, D., Blundell, C., Zwols, Y., Ha, D., Rusu, A. A., ... Wierstra, D. (2017). PathNet: Evolution Channels Gradient Descent in Super Neural Networks. In arXiv preprint arXiv:1701.08734.
Kaiser, Ł., Nachum, O., Roy, A., & Bengio, S. (2017). Learning to Remember Rare Events. In ICLR 2017.
Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., & Wierstra, D. (2016). Matching Networks for One Shot Learning. NIPS 2016. Retrieved from http://arxiv.org/abs/1606.04080
Ravi, S., & Larochelle, H. (2017). Optimization as a Model for Few-Shot Learning. In ICLR 2017.
Xian, Y., Schiele, B., Akata, Z., Campus, S. I., & Machine, A. (2017). Zero-Shot Learning - The Good, the Bad and the Ugly. In CVPR 2017.
Tzeng, E., Hoffman, J., Saenko, K., & Darrell, T. (2017). Adversarial Discriminative Domain Adaptation.
翻译人:ArrayZoneYour,
原文链接:http://ruder.io/transfer-learning/index.html
原文作者:anonymous

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能金融”、“智能零售”、“智能驾驶”、“智能城市”;新模式:“财富空间”、“工业互联网”、“数据科学家”、“赛博物理系统CPS”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com




