DeepMind 的这个模型,可以说是「看一眼」就学会了。
关于智能,其关键点是在得到一个简短的指令时快速学习如何执行新任务的能力。例如,一个孩子在动物园看到动物时,他会联想到自己曾在书中看到的,并且认出该动物,尽管书中和现实中的动物有很大的差异。
但对于一个典型的视觉模型来说,要学习一项新任务,它必须接受数以万计的、专门为该任务标记的例子来进行训练。假如一项研究的目标是计数和识别图像中的动物,例如「三匹斑马」这样的描述,为了完成这一任务,研究者将不得不收集数千张图片,并在每张图片上标注它们的数量和种类。但是标注过程效率低效、成本高,对于资源密集型的任务来说,需要大量带注释的数据,并且每次遇到新任务时都需要训练一个新模型。
DeepMind 另辟蹊径,他们正在探索可替代模型,可以使这个过程更容易、更高效,只给出有限的特定于任务的信息。
在 DeepMind 最新公布的论文中,他们推出了 Flamingo(火烈鸟)模型,这是一个单一的视觉语言模型(visual language model,VLM),它在广泛的开放式多模态任务中建立了少样本学习新 SOTA。这意味着 Flamingo 只需少量的特定例子(少样本)就能解决许多难题,而无需额外训练。Flamingo 的简单界面使这成为可能,它将图像、视频和文本作为提示(prompt),然后输出相关语言。
![]()
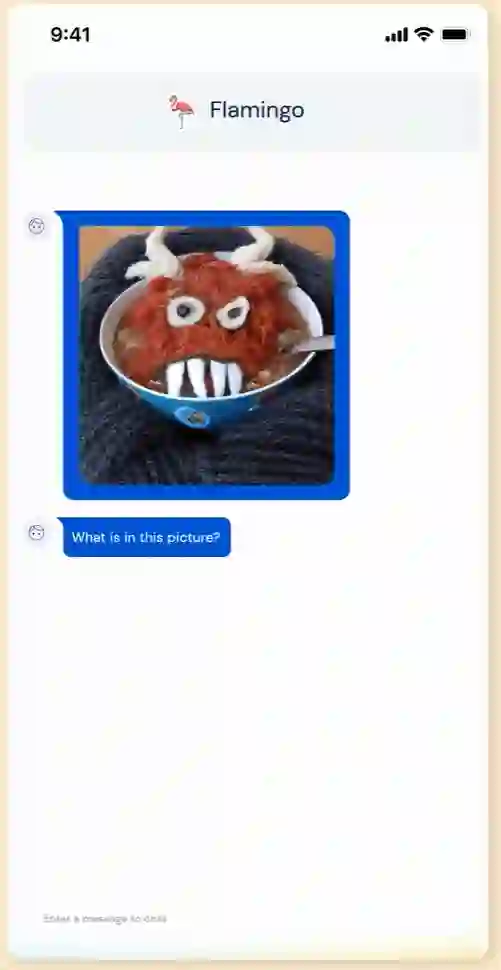
这个 Flamingo 模型到底有多智能呢?我们先来看下效果:Flamingo 可以进行开箱即用的多模式对话,下图展示的是使用 OpenAI 的 DALL·E 2 生成的「汤怪物」图像,在关于这张图像的不同问答中,Flamingo 都能准确地回答出来。例如问题:这张图片中有什么?Flamingo 回答:一碗汤,一张怪物脸在上面。
![]()
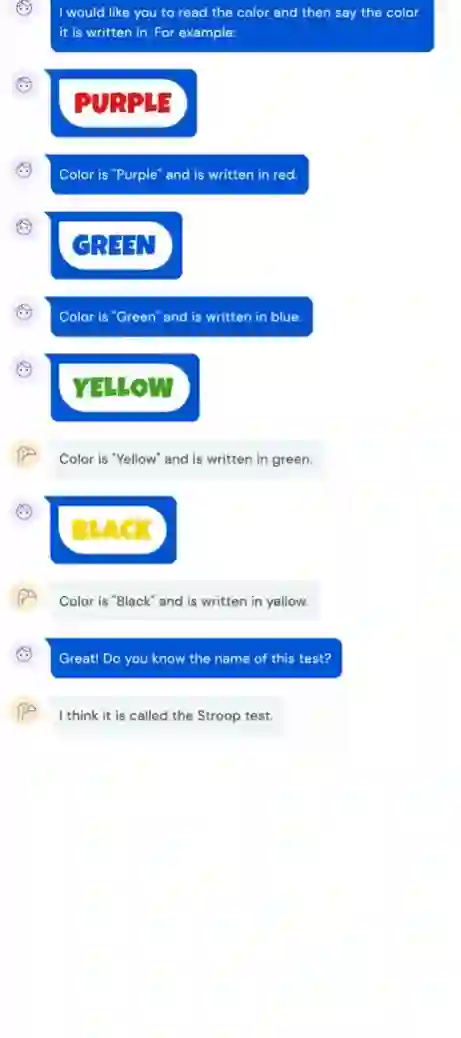
Flamingo 还能通过并识别出著名的斯特鲁普效应 (Stroop effect),例如事先给几个示例,如出题人给出表示绿色的单词 GREEN,并用蓝色的字体表示,回答者需要回答:颜色是绿色,用蓝色书写。在给出几组示例后,Flamingo 就学会了这种模式,当给出 YELLOW 绿色字体时,Flamingo 回答:颜色是黄色,用绿色书写。
此外,Flamingo 还能识别出这是 Stroop 测试。
![]()
下图给出了两个动物图片示例和一个标识它们名称的文本以及关于在哪里可以找到的描述,Flamingo 可以模仿这种风格,给定一个新图像以输出相关描述:例如,在给出栗鼠、柴犬示例后,Flamingo 模仿这种方式,输出这是一只火烈鸟,它们在加勒比海被发现。
![]()
![]()
就像大型语言模型一样,Flamingo 可以快速适应各种图像和视频理解任务,只需简单地提示它几个例子 (上图)。Flamingo 还具有丰富的视觉对话功能 (下)。
![]()
在实践中,通过在两者之间添加新颖的架构组件,Flamingo 将每个经过单独预训练和冻结的大型语言模型与强大的视觉表示融合在一起。接着在仅来自网络上的互补大规模多模态混合数据上进行训练,而不使用任何为达到机器学习目的而标注的数据。
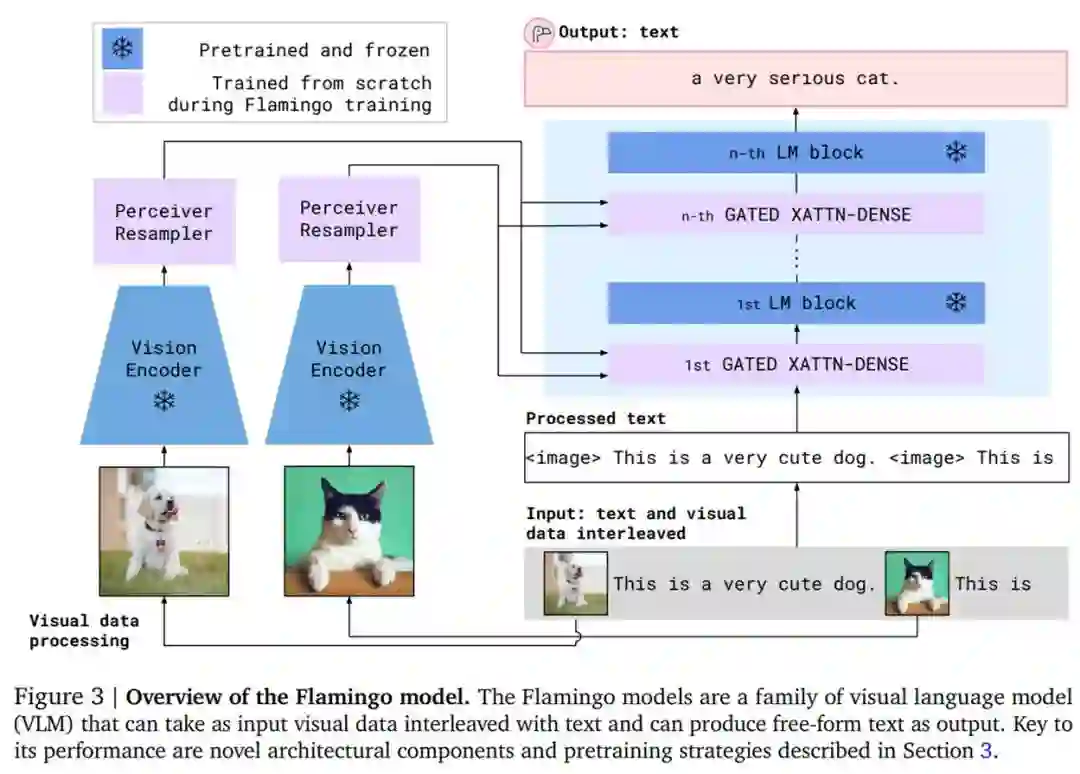
按照该方法,研究者从最近推出的计算最优的 700 亿参数语言模型 Chinchilla 入手,训练最终的 800 亿参数的 VLM 模型 Flamingo。完成训练后,Flamingo 经过简单的少样本学习即可直接适用于视觉任务,无需任何额外特定于任务的微调。下图为 Flamingo 架构概览。
![]()
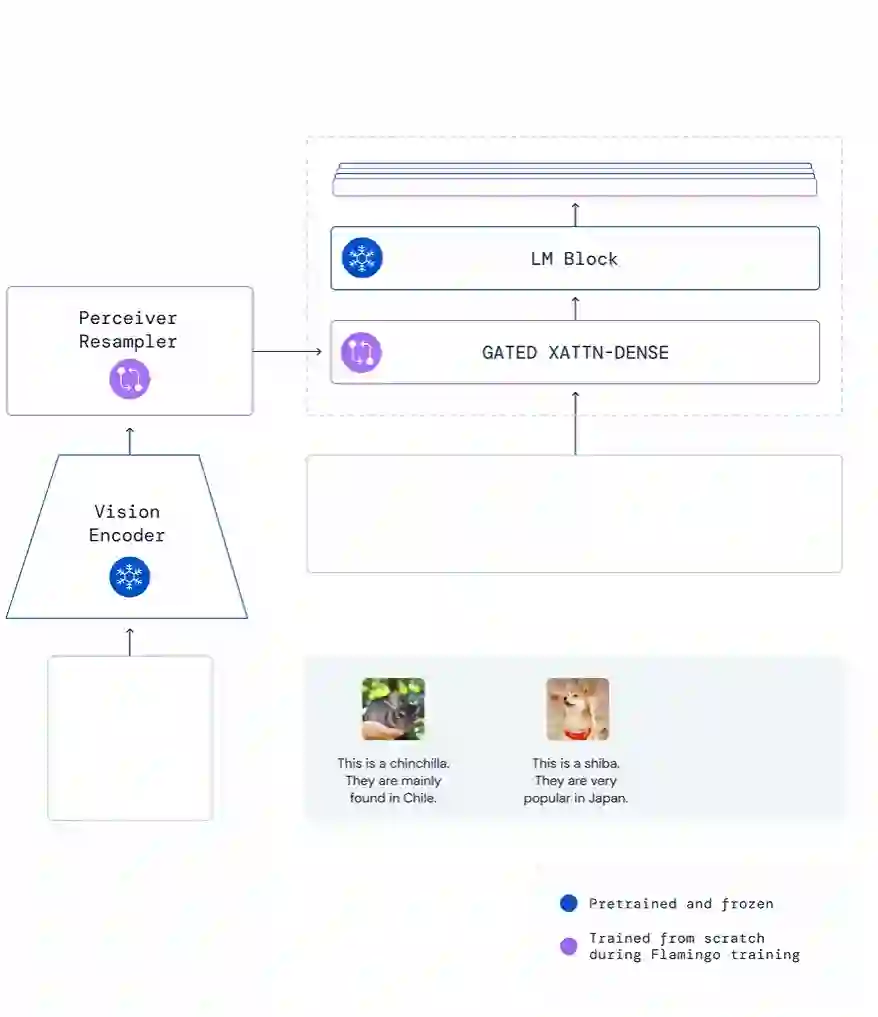
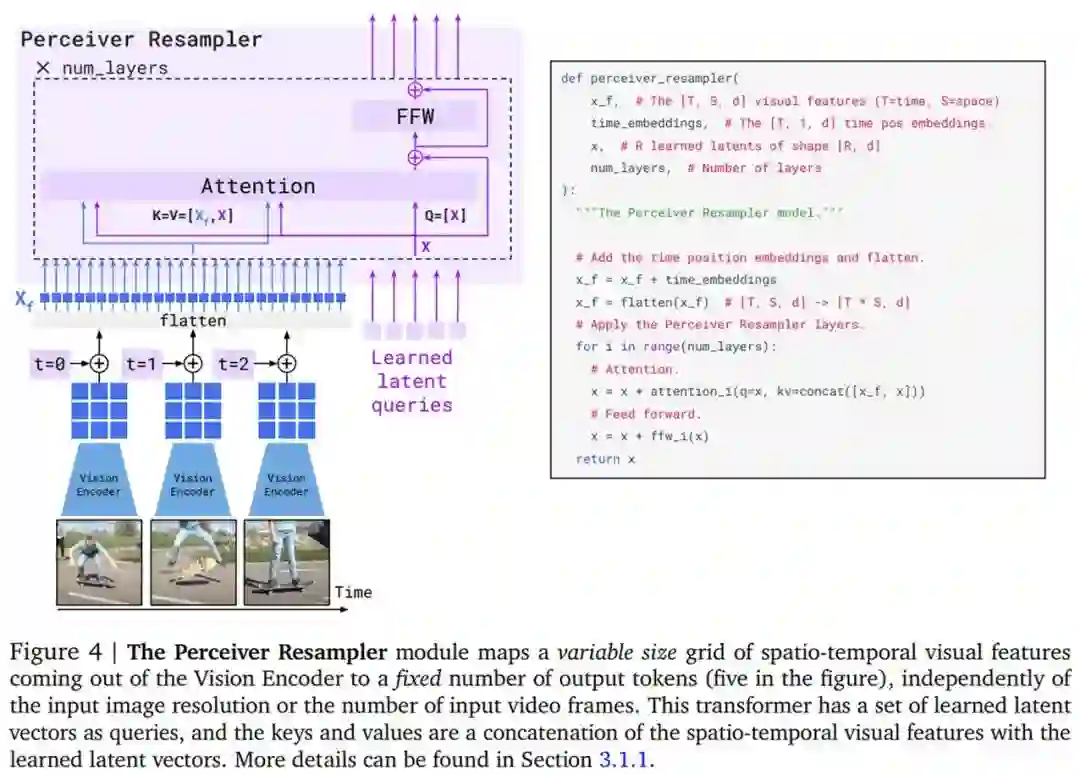
首先是视觉处理和感知器重采样器(Perceiver Resampler)。Flamingo 模型的视觉编码器是一个预训练的 NFNet,研究者使用的是 F6 模型。在 Flamingo 模型的主要训练阶段,他们将视觉编码器冻结,这是因为它与直接基于文本生成目标训练视觉模型相比表现得更好。最后阶段是特征 X_f 的 2D 空间网格被展平为 1D,如下图 4 所示。
感知器重采样器模块将视觉编码器连接到冻结的语言模型(如上图 3 所示),并将来自视觉编码器的可变数量的图像或视频特征作为输入,产生固定数量的视觉输出,如下图 4 所示。
![]()
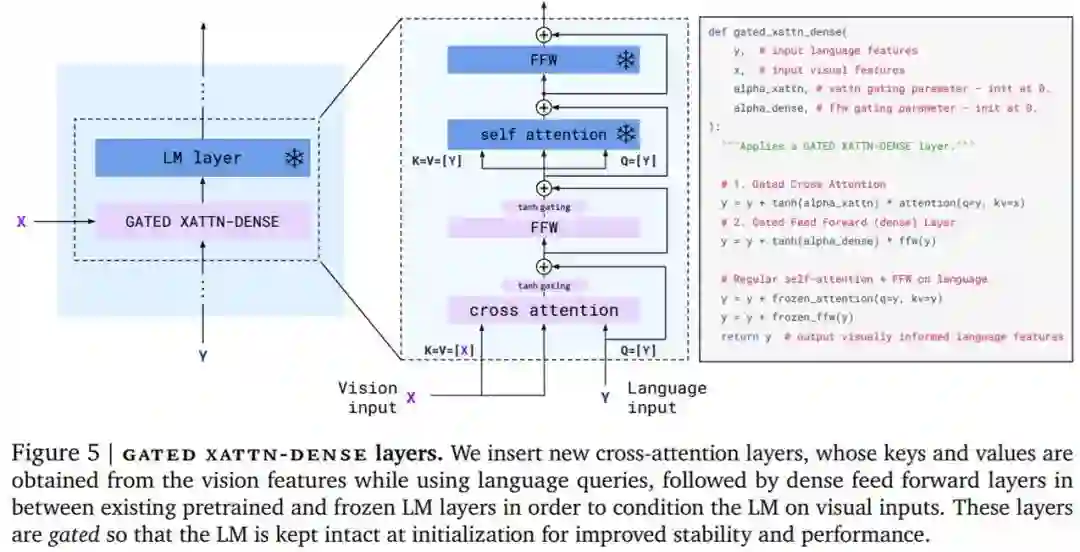
然后是在视觉表示上调整冻结的语言模型。如下图 5 所示,文本生成由一个 Transformer 解码器执行,并以感知器重采样器生成的视觉表示 X 为条件。研究者通过间插从仅文本语言模型中获得的预训练块以及使用感知器重采样器的输出作为输入从头训练的块来构建模型。
此外,为了使得 VLM 模型具有足够的可表达性并使它在视觉输入上表现良好,研究者在初始层之间插入了从头开始训练的门跨注意力密集块。
![]()
最后,如下图 7 所示,研究者在三种类型的混合数据集上训练 Flamingo 模型,分别是取自网页的间插图像和文本数据集、图像和文本对以及视频和文本对。
![]()
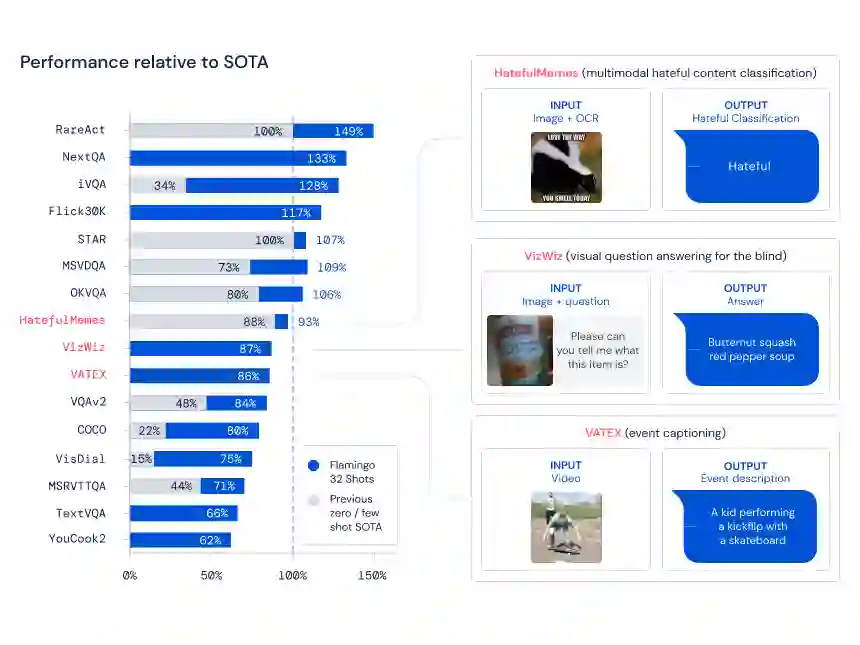
在纳入研究的 16 个任务中,当每个任务仅给定 4 个示例时,Flamingo 击败了以往所有的少样本学习方法。在某些情况下,Flamingo 模型甚至优于针对每个任务单独进行微调优化并使用更多数量级特定于任务的数据的方法。这使得非专家人员可以快速轻松地在手头新任务上使用准确的视觉语言模型。
下图左为 Flamingo 在 16 个不同的多模态任务上与特定于任务的 SOTA 方法的少样本性能比较。图右为 16 个基准中的 3 个的预期输入和输出示例。
![]()
Flamingo 是一个有效且高效的通用模型族,它们可以通过极少的特定于任务的示例应用于图像和视频理解任务。
DeepMind 表示,像 Flamingo 这类模型很有希望以实际的方式造福社会,并将继续提升模型的灵活性和能力,以便可以实现安全的部署。Flamingo 展示的能力为与学得视觉语言模型的丰富交互铺平了道路,这些模型能够实现更好的可解释性和令人兴奋的新应用,比如在日常生活中帮助人们的视觉助手等。
https://www.deepmind.com/blog/tackling-multiple-tasks-with-a-single-visual-language-model
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com