AAAI20论文:面向目标观点词抽取的潜在观点迁移网络

01
—
背景介绍
面向目标的观点词抽取(Target-oriented Opinion Words Extraction, TOWE)是一个细粒度的情感分析任务,任务旨在从评论句子中抽取出给定目标(Target)对应的观点词(Opinion Words)。举个例子,句子“waiters are very friendly and the pasta is out of this world.”中包含两个目标,当给定目标分别是“waiters”和“pasta”时,TOWE需要抽取出“friendly”和“out of this world”分别作为“waiters”和“pasta”对应的观点词。由于细粒度情感分析数据标注复杂且耗时,这个任务的数据集规模通常比较小,一般包含1000~3000个样本,数据不足严重制约了深度学习模型在TOWE任务上的性能。相比之下,文档级的情感分类数据很容易从在线评论网站中获取,这些评论数据中包含了大量的潜在观点信息以及与情感相关的语义模式。因此,本文从迁移学习的角度出发,提出迁移文档情感分类数据中的潜在观点来提升TOWE任务的性能。
在迁移之前,有两个挑战需要解决。首先,情感分类数据中的观点信息(如观点词)是未标注的,我们需要显示找出这些潜在的观点信息。其次,文档情感分类只考虑文本整体的情感极性,不涉及具体的目标对象。因此,在第一步找出全局的观点信息之后,我们需要将其转化成目标相关的观点信息,然后才能融合到TOWE任务中。
02
—
解决方案
为了解决迁移过程中的两个挑战,我们设计了一个潜在观点迁移网络(Latent Opinion Transfer Network,LOTN),如下图所示。LOTN主要包含两个模块,左边的模块用来解决TOWE任务,右边是预先训练的文档情感分类模块。
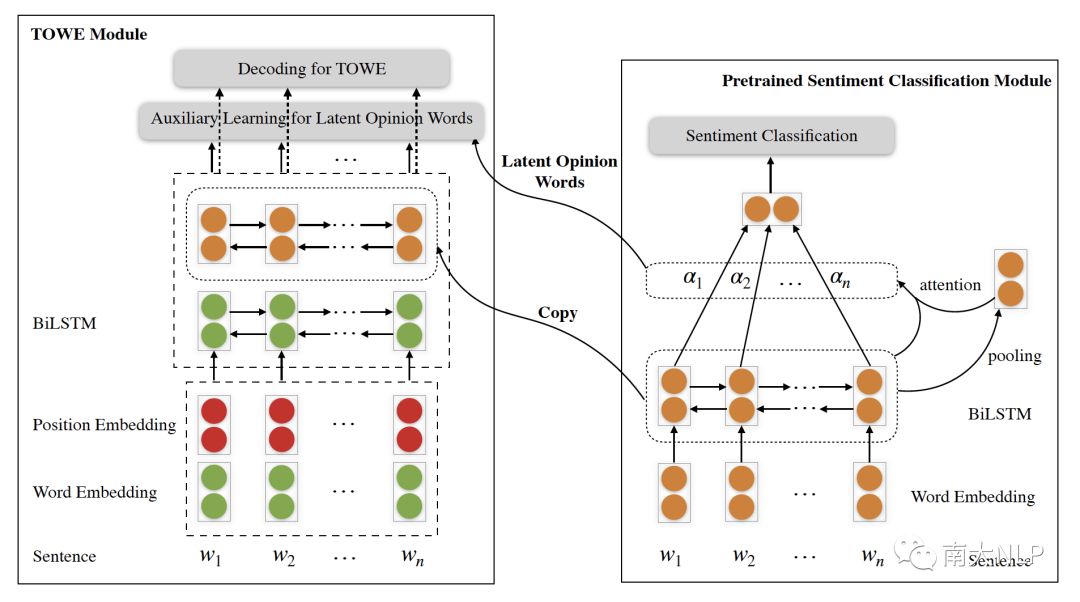
图1:潜在观点迁移网络
具体而言,我们先在大规模评论情感分类数据集上预训练一个情感分类模型。在预训练的情感分类模型中,我们采用注意力机制捕获文本中潜在的观点。可以想到,注意力权重越大的词越有可能是观点词,因此注意力权重可以用来指示潜在的观点词。为了解决上述的第二个挑战,我们设计了一个启发式规则,将情感分类模型中每个词的注意力权重乘以一个与目标对象相关的系数,从而将全局的注意力权重转化成目标相关的注意力权重。系数大小根据每个词与目标对象之间的距离计算得出,距离目标对象越近的词系数越大。因为根据语义表达上的相关性,和目标对象越接近的词越有可能是其对应的观点词,观点词出现在较远位置的概率会低很多。然后,我们通过一个阈值,将目标相关的注意力权重转化成0/1分布的潜在观点词标签,并通过辅助学习信号将这些潜在的观点词信息融合到TOWE任务中。此外,预训练情感分类模型中的BiLSTM层包含着大量情感相关的语义模式,因此,我们也将它拼接到TOWE模块的encoder中。
03
—
实验结果与分析
我们在四个TOWE数据集上进行了实验,它们的数据量均在1000~2700之间。预训练情感分类数据分别来自Yelp评论网站和Amazon评论网站,共计100万条左右。数据集统计信息如表1和表2所示。
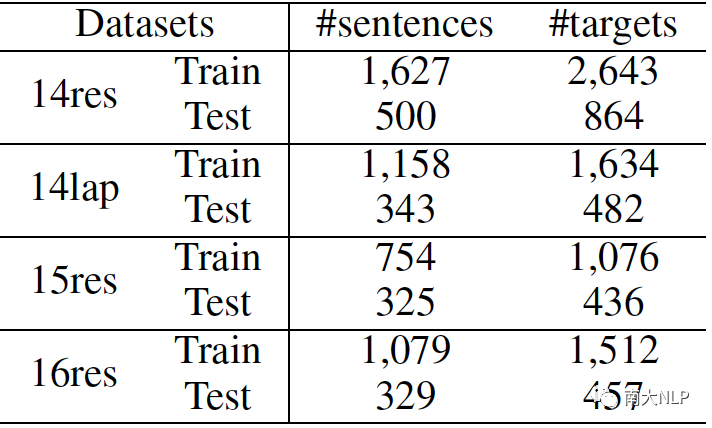
表1:TOWE数据集统计信息

表2:预训练情感分类数据集统计信息
采用precision、recall和F1-score来衡量不同模型的性能,主要结果如表3所示,PE-BiLSTM是我们基础的TOWE模型,也是LOTN的base版本,表示不从情感分类数据集中迁移观点知识。
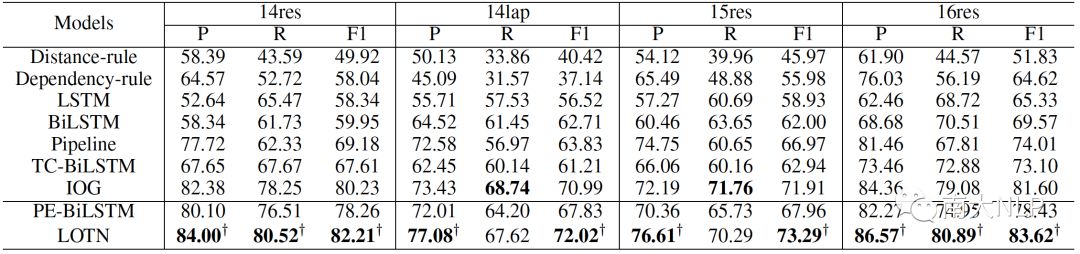
表3:不同模型在TOWE任务上的表现
可以看到,我们的潜在观点迁移网络LOTN相对base模型PE-BiLSTM取得了非常显著的提升。相比于之前的state-of-the-art IOG,LOTN也获得了比较明显的提升。
我们测试了迁移encoder和迁移潜在观点词对TOWE任务带来的性能增益,结果如表4所示。

表4:迁移encoder和潜在观点词的影响
可以看到,相比于base模型PE-BiLSTM,迁移encoder或者潜在观点词都获得了明显的性能提升,这表明两种方案都能捕获情感分类数据中潜在的观点信息,并为TOWE所用。融合两者之后,结果获得了进一步提升,说明两者从不同角度迁移了观点知识。
此外,我们也统计了base模型PE-BiLSTM和最终模型LOTN在数据集14res上的错误信息,结果见表5。

表5:PE-BiLSTM和 LOTN在14res上的错误类型统计
“NULL”即抽取结果为空,表示模型没有抽取任何观点词;“under-extracted”表示模型只抽取了真实观点词的一部分;“over-extracted”则表示除真实观点词外模型还抽取了其他的词。可以看到,在迁移情感分类数据集中的潜在观点知识之后,LOTN在空预测和“under-extracted”上的错误更少,在“over-extracted”上的错误变多。这三者一致地表明,在迁移观点的影响下,LOTN倾向解码出更多的观点词。实际上,“NULL”和“under-extracted”两类错误都属于抽取不足,表5的结果也表明抽取不足可能是TOWE任务的主要错误。
04
—
总结
数据不足很大程度上制约了深度学习在TOWE任务上的性能。本文提出将大规模情感分类数据集中潜在的观点知识迁移至TOWE任务,并设计了一个神经网络模型从两种不同的角度来迁移观点信息,从而在一定程度上弥补了TOWE任务数据不足的问题。实验结果验证了我们方案的有效性,错误分析也揭露了TOWE任务仍然存在的一些问题。
作者:吴震
编辑:何亮
南大NLP研究组

南京大学自然语言处理研究组从事自然语言处理领域的研究工作始于20世纪80年代。曾先后承担过该领域的18项国家科技攻关项目、863项目、国家自然科学基金和江苏省自然科学基金以及多项对外合作项目的研制。其中,承担的国家七五科技攻关项目“日汉机译系统研究”获七五国家科技攻关重大成果奖、教委科技进步二等奖以及江苏省科技进步三等奖。
分析理解人类语言是人工智能的重要问题之一,本研究组在自然语言处理的多个方向上做了大量、深入的工作。近年来集中关注文本分析、机器翻译、社交媒体分析推荐、知识问答等多个热点问题,结合统计方法和深度学习方法进行问题建模和求解,取得了丰富的成果。本研究组在自然语言处理顶级国际会议ACL上连续三年发表多篇论文,也在人工智能顶级国际会议IJCAI和AAAI上发表论文多篇,相关系统在机器翻译、中文分词、命名实体识别、情感计算等多个国际国内评测中名列前茅。
本实验室立志于研究和解决在传统文本和互联网资源的分析处理中面临的各项问题和挑战,并积极探索自然语言处理的各种应用。如果你也和我们有共同兴趣或目标,欢迎加入我们!
推荐阅读
CCMT2019最佳论文奖:在远距离语言对上提升双语词典推断的质量
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




