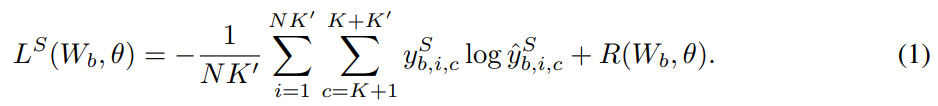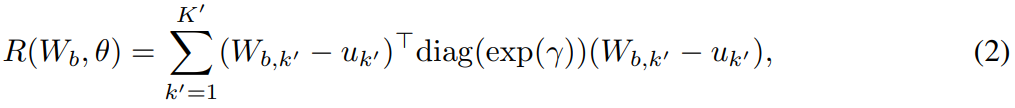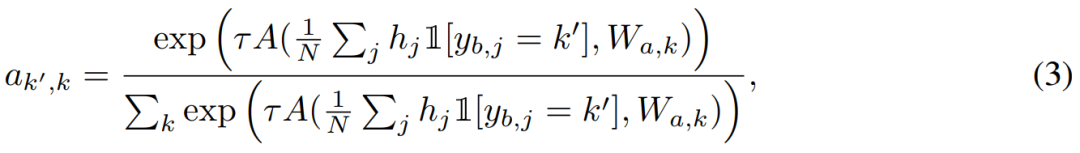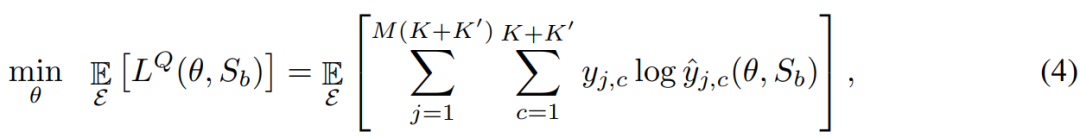选自 arXiv
作者:Mengye Ren、Renjie Liao等
机器之心编译
参与:Panda
少量次学习(Few-Shot Learning)一直以来都是机器学习领域内的一个重要研究主题。近日,多伦多大学一组研究团队,提出了一种使用注意式吸引器网络的渐进式少量次学习方法,能在记住基础类别的同时很好地学习全新的类别。
论文:https://arxiv.org/abs/1810.07218
代码:
https://github.com/renmengye/inc-few-shot-attractor-public
通常,机器学习分类器的训练目标是识别一组预定义的类别,但是很多应用往往需要机器学习能通过有限的数据灵活地学习额外的概念,而且无需在整个训练集上重新训练。
这篇论文提出的渐进式少量次学习(incremental few-shot learning)能够解决这个问题,其中已经训练好的常规分类网络能够识别一组基础类别,同时也会考虑一些额外的全新类别,包括仅有少量有标注的样本地一些类别。在学习了全新的类别后,这个模型会在基础类别与全新类别的整体分类表现上被重新评估。为此,作者提出了一种元学习模型:注意式吸引器网络(Attention Attractor Network)。它可以调整对全新类别的学习规范,在每个 episode 中,作者都会训练一组新的用于识别全新类别的权重,直到它们收敛,而且作者还表明这种循环式反向传播技术可以在整个优化过程中反向传播,并能促进对这些参数的学习。研究表明,学习得到的吸引器网络无需回顾原始的训练集,就能在记住旧有类别的同时助力对全新类别的识别,其表现也胜过多种基准。
作者在 mini-ImageNet 和 tiered-ImageNet 上进行了实验,结果表明新提出的方法在渐进式少量次学习方面达到了当前最佳水平。
![]()
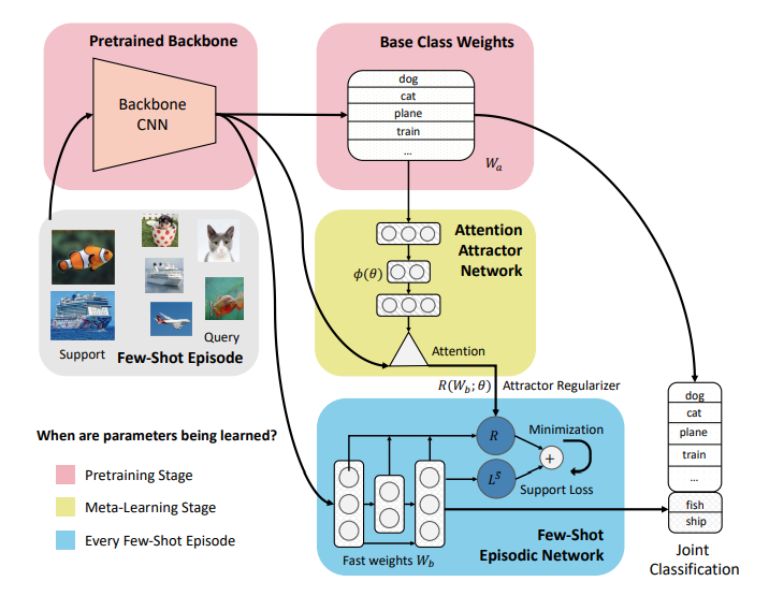
图 1:新提出的用于渐进式少量次学习的注意式吸引器网络。在预训练期间,网络学习基础类别权重 W_a 和特征提取器 CNN 骨干网络。在元学习阶段则是一个少量次学习 episode。
首先,这一节定义了渐进式少量次学习的设置,然后会介绍新提出的模型:注意式吸引器网络。该模型能通过使用吸引器正则化项,根据少量次训练数据来实现对基础类别集的关注。图 1 给出了该方法的较高水平的模型示意图。
实现渐进式少量次学习的元学习方法的大致过程为:(1)在一个基础类别集上,学习一组固定的特征表征和一个分类器;(2)在每个训练和测试 episode 中,使用元学习得到的正则化器训练一个新类别分类器;(3)基于组合到一起的新类别和基础类别分类数据,对元学习的正则化器进行优化和适应,使其也能在基础分类器上取得良好的表现。这些阶段的详情如下:
预训练阶段:在基础类别数据集 D_a 上学习一个常规监督式分类任务的基础模型。这个阶段的目的是学习得到一个优良的基础分类器和优良的表征。基础分类器的参数是在这个阶段学习得到的,并会在预训练之后固定下来。
渐进式少量次 episode:在一个少量次数据集 D_b 上,采样少量次 episode E。注意这个数据集可能与预训练数据集 D_a 的数据源相同,但采样是按 episode 来的。
元学习阶段:元训练阶段会迭代式地采样少量次 episode E 并尝试学习元参数,使得让联合查询数据集 Q_(a+b) 上的联合预测损失最小化。作者特别指出他们设计的正则化器 R(·, θ) 能通过最小化损失 l(W_b, S_b)+R(W_b, θ) 来快速学习权重,其中 l(W_b, S_b) 通常是用于少量次分类的交叉熵损失。
基础类别与全新类别上的联合预测:现在介绍每个少量次 episode 中执行的联合预测框架的细节。首先,构建一个 episode 式的分类器,比如一个 logistic 回归模型或多层感知器;该模型以所学习到的特征为输入,并根据少量次类别对它们进行分类。在支持集 S_b 上训练期间,可通过最小化以下正则化的交叉熵目标来学习快速权重,作者将这个目标称为「episodic objective」:
直接学习少量次 episode(比如通过将 R(W_b, θ) 设置为 0 或简单的权重延迟)会导致对基础类别的灾难性遗忘。原因是,为最大化正确的全新类别概率而训练的 W_b 可能会在联合预测中支配基础类别。为了解决这一问题,作者提出了注意式吸引器网络。这种吸引器网络的关键特点是正则化项 R(W_b, θ):
![]()
为了确保模型在基础类别上表现良好,吸引器必须包含一些基础类别样本的有关信息。由于无法直接读取这些基础样本,作者提出使用慢权重(slow weights)来编码这样的信息。具体来说,每个基础类别都有一个学习后的吸引器向量 U_k,其存储在内存矩阵 U=[U_1, ..., U_K] 中。
对于支持集中的每个类别,模型都会计算该类别的平均表征与基础权重 W_a 之间的余弦相似度,然后会使用一个 softmax 函数进行归一化:
![]()
这种设计的灵感来自 M. C. Mozer 等人提出的吸引器网络,针对每个基础类别都会有保存了与该类别有关的相关记忆的一个「吸引器」。作者将他们提出的整个模型称为「动态吸引器(dynamic attractor)」,因为它们可能会随每个 episode(即使是在元学习之后)而变化。
在元学习期间,θ 会被更新,以最小化查询集 Q_(a+b)(查询集包含基础类别和全新的类别)的预期损失,并求取所有少量次学习 episode 上的平均:
![]()
作者在两个少量次分类数据集 mini-ImageNet 和 tiered-ImageNet 上进行了实验。这两个数据集都是 ImageNet 的子集,其图像大小被减少到了 84×84 像素。作者还对这两个数据集进行了一些修改,使其满足渐进式少量次学习的设置。
作者使用的骨干网络是一个标准的 ResNet,可通过监督式训练学习特征表征。对于 mini-ImageNet 实验,作者使用的是一个修改版的 ResNet-10。对于 tiered-ImageNet 则使用了 ResNet-18,但使用分组归一化(group normalization)层替换了其中所有的分批归一化(batch normalization)层;原因是由于类别的划分方式,tiered-ImageNet 从训练到测试时有较大的分布转变。
作者考虑了以下评估指标:(1)在单个查询集和联合查询集(Base、Novel 和 Both)上的总体准确度;(2)在基础类别和全新类别之中分别考虑的由联合预测导致的表现下降(∆_a 和 ∆_b)。最后,对两者求平均:∆=1/2(∆_a + ∆_b),得到整体准确度下降的关键指标。
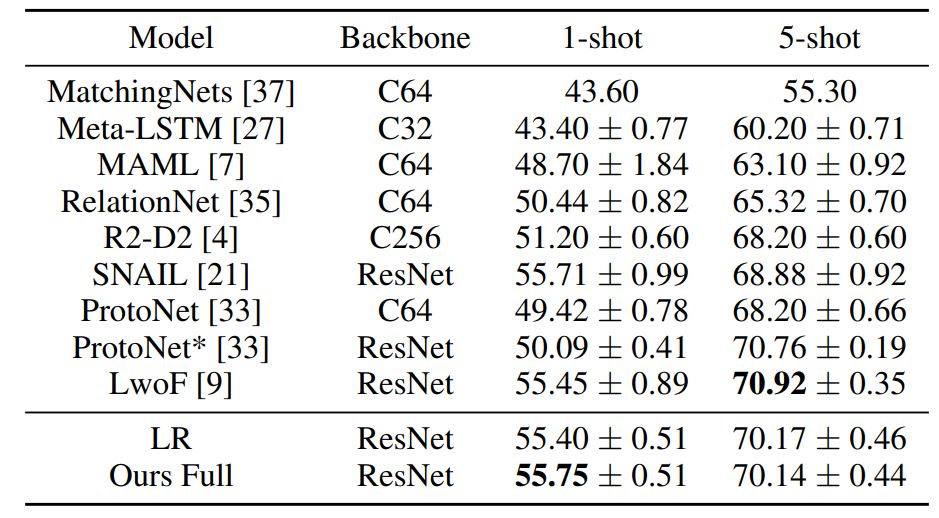
作者实现了三种方法,并对它们进行了比较,即 Prototypical Networks(调整到了适用于渐进式少量次学习的设置)、Weights Imprinting 和 Learning without Forgetting。
![]()
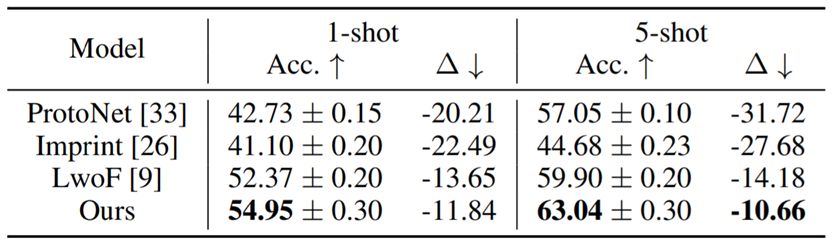
表 2:
mini-ImageNet 上 64+5-way 结果;
64+5-way 表示基础类别数为 64,全新类别数为 5。
∆ 是指在基础类别和全新类别中的由联合预测所导致的平均准确度下降(∆=1/2(∆_a + ∆_b));
↑ (↓) 表示更高(更低)更好。
![]()
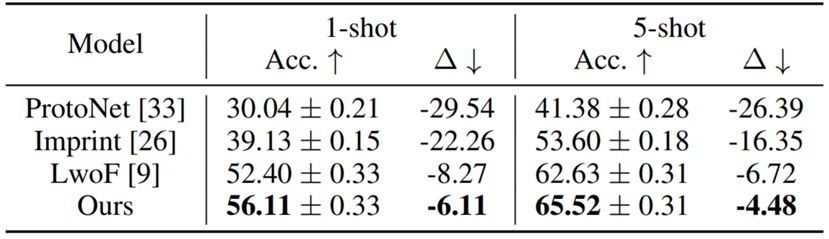
表 3:
tiered-ImageNet 上 200+5-way 结果;
200+5-way 表示基础类别数为 200,全新类别数为 5
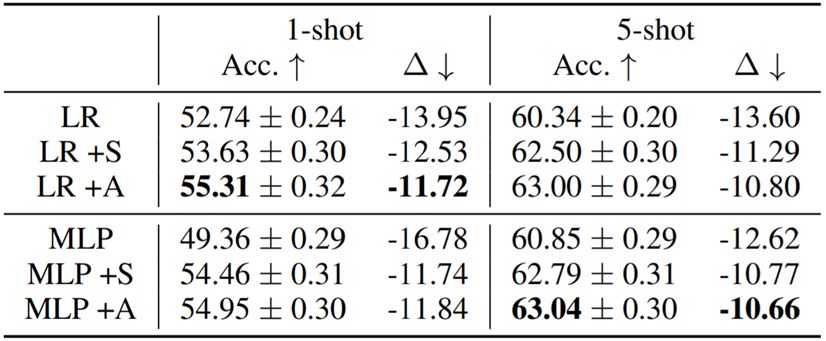
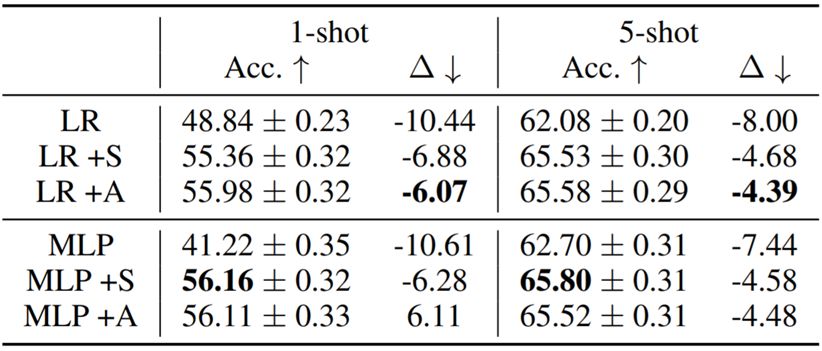
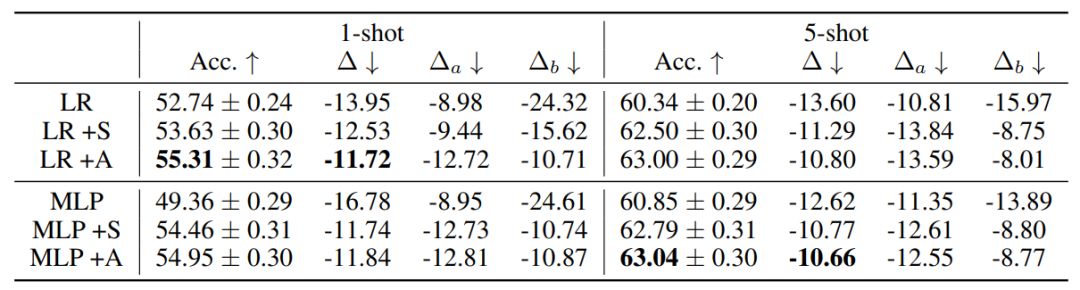
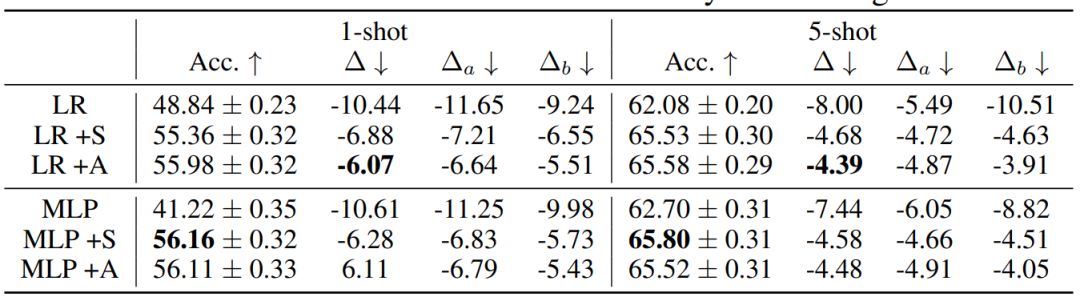
为了理解所提出的模型的每个部分的有效性,作者研究了以下变体:基本模型(LR、MLP)、静态吸引器(+S)和注意式吸引器(+A)。
表 4 和 5 给出了消融实验的结果。在所有案例中,学习得到的正则化函数都比为分类器网络人工设置权重延迟常数的表现更好;不管是联合预测基础类别和全新类别,还是相比于单个预测的劣化更低方面都是如此。在 mini-ImageNet 上,新提出的注意式吸引器相比于静态吸引器优势明显。
![]()
表 4:
在 mini-ImageNet 上的消融实验;
+S 表示静态吸引器,+A 表示注意式吸引器。
![]()
表 5:
在 tiered-ImageNet 上的消融实验。
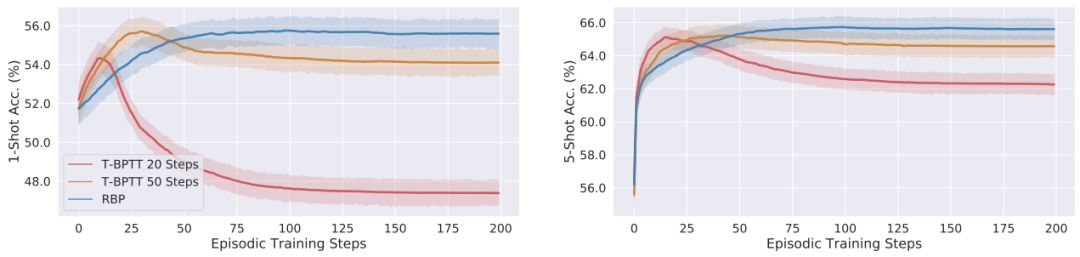
如图 2 所示,T-BPTT 学习到的模型的表现与作者提出的模型相当;但是,当在测试时间解决收敛问题时,T-BPTT 模型的表现会显著下降。而对 RBP 模型而言,由于支持样本数量小,完成完整 episode 训练的速度很快。
图 2:使用 T-BPTT 和 RBP 学习所提出的模型的表现比较。
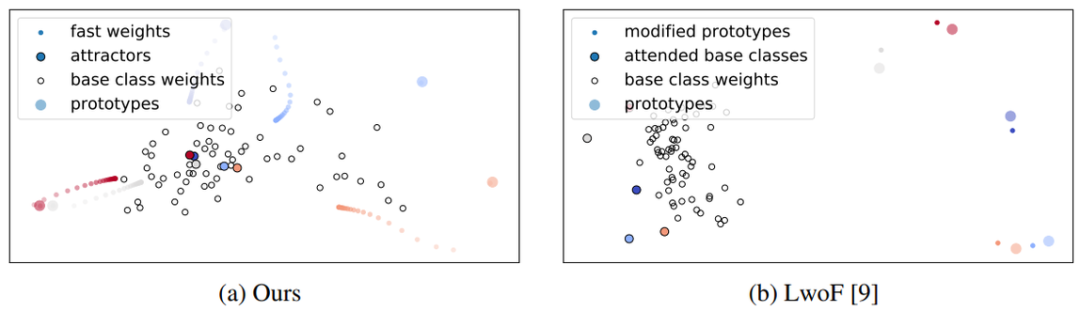
图 3 给出了吸引器动态的可视化结果。可以看到,作者提出的吸引器能将快速权重向基础类别权重推进。相比而言,Gidaris 和 Komodakis 提出的 LwoF(learning without forgetting)方法仅对原型有略微的修改。
图 3:使用 PCA 得到的 5-shot 64+5-way episode 的可视化。左图:新提出的吸引器模型能学习将原型(较大的有颜色的圈)「推向」基础类别权重(白圈)。右图:无遗忘的动态少量次学习。
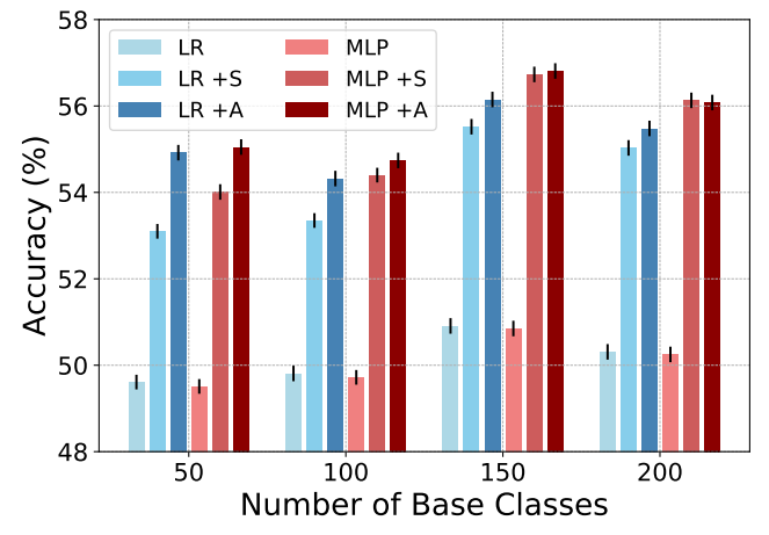
图 4 表明,所学习到的正则化器总是优于仅使用权重衰减的基准。由于在骨干网络上的表征更好,基础类别数量从 50 增至 150 时,整体准确度也在增长。而由于在类别数量为 200 时分类任务的难度更大,整体准确度有所下降。
图 4:当基础类别数量为 {50, 100, 150, 200} 时在 tiered-ImageNet 上的结果。
![]()
表 6:
在 mini-ImageNet 上的常规 5-way 少量次分类结果。
注意这是纯粹的少量次,没有基础类别。
![]()
表 7:
在 mini-ImageNet 上 64+5-way 全消融实验的结果。
![]()
表 8:
在 tiered-ImageNet 上 200+5-way 全消融实验的结果。
![]()
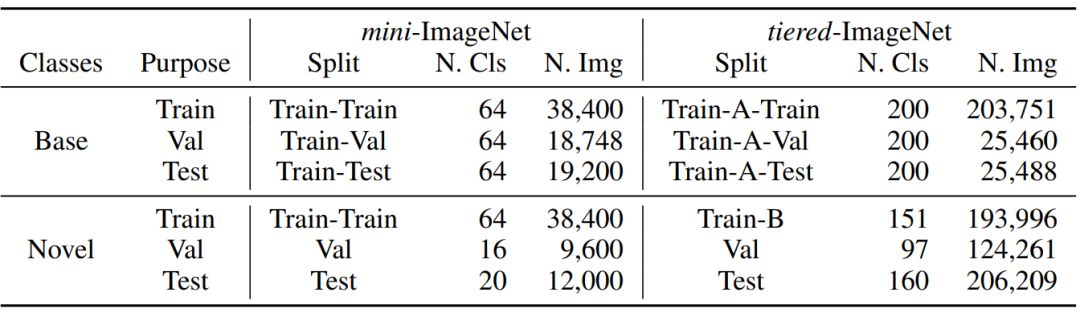
表 9:mini-ImageNet 和 tiered-ImageNet 的数据集划分情况。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com