看完这篇垃圾回收,和面试官扯皮没问题了


作者 | 码海
来源 | 码海(ID:seaofcode)
责编 | 伍杏玲
-
GC 的几种主要的收集方法:标记清除、标记整理、复制算法的原理与特点,各自的优劣势? -
为啥会有 Serial ,CMS, G1 等各式样的回收器,各自的优劣势是什么,为啥没有一个统一的万能的垃圾回收器? -
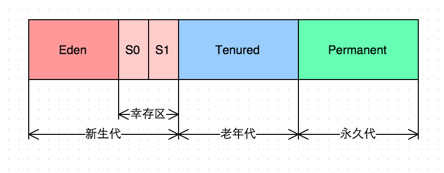
新生代为啥要设置成 Eden, S0,S1 这三个区,基于什么考虑呢? -
堆外内存不受 GC 控制,那该怎么释放呢? -
对象可回收,就一定会被回收吗? -
什么是 SafePoint,什么是 Stop The World?
-
GC 日志格式怎么看? -
主要有哪些发生 OOM 的场景? -
发生 OOM,如何定位,常用的内存调试工具有哪些?
-
JVM 内存区域 -
如何识别垃圾 -
引用计数法 -
可达性算法 -
垃圾回收主要方法 -
标记清除法 -
复制法 -
标记整理法 -
分代收集算法 -
垃圾回收器对比

JVM 内存区域
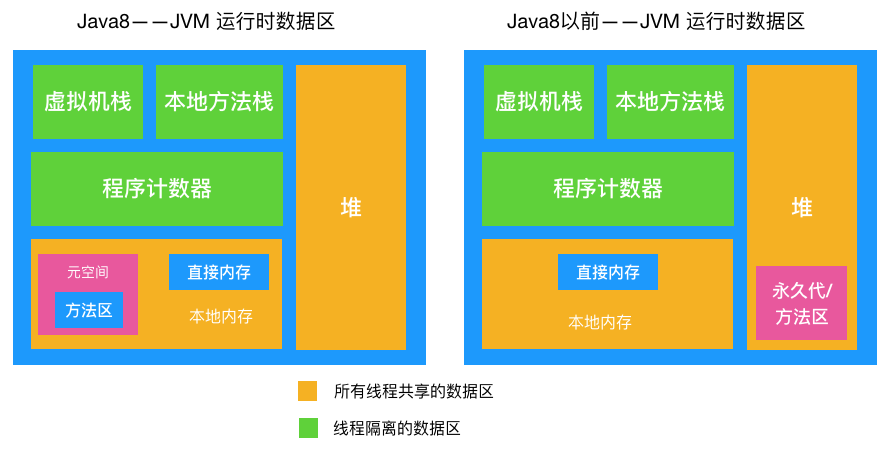
-
虚拟机栈:描述的是方法执行时的内存模型,是线程私有的,生命周期与线程相同,每个方法被执行的同时会创建栈桢(下文会看到),主要保存执行方法时的局部变量表、操作数栈、动态连接和方法返回地址等信息,方法执行时入栈,方法执行完出栈,出栈就相当于清空了数据,入栈出栈的时机很明确,所以这块区域不需要进行 GC。 -
本地方法栈:与虚拟机栈功能非常类似,主要区别在于虚拟机栈为虚拟机执行 Java 方法时服务,而本地方法栈为虚拟机执行本地方法时服务的。这块区域也不需要进行 GC。 -
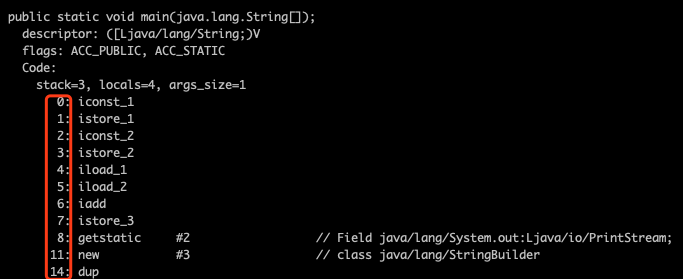
程序计数器: 线程独有的, 可以把它看作是当前线程执行的字节码的行号指示器,比如如下 字节码内容,在 每个字节码`前面都有一个数字(行号),我们可以认为它就是程序计数器存储的内容
-
本地内存:线程共享区域,Java 8 中,本地内存,也是我们通常说的堆外内存,包含元空间和直接内存,注意到上图中 Java 8 和 Java 8 之前的 JVM 内存区域的区别了吗,在 Java 8 之前有个永久代的概念,实际上指的是 HotSpot 虚拟机上的永久代,它用永久代实现了 JVM 规范定义的方法区功能,主要存储类的信息,常量,静态变量,即时编译器编译后代码等,这部分由于是在堆中实现的,受 GC 的管理,不过由于永久代有 -XX:MaxPermSize 的上限,所以如果动态生成类(将类信息放入永久代)或大量地执行 String.intern (将字段串放入永久代中的常量区),很容易造成 OOM,有人说可以把永久代设置得足够大,但很难确定一个合适的大小,受类数量,常量数量的多少影响很大。所以在 Java 8 中就把方法区的实现移到了本地内存中的元空间中,这样方法区就不受 JVM 的控制了,也就不会进行 GC,也因此提升了性能(发生 GC 会发生 Stop The Word,造成性能受到一定影响,后文会提到),也就不存在由于永久代限制大小而导致的 OOM 异常了(假设总内存1G,JVM 被分配内存 100M, 理论上元空间可以分配 2G-100M = 1.9G,空间大小足够),也方便在元空间中统一管理。综上所述,在 Java 8 以后这一区域也不需要进行 GC
-
堆:前面几块数据区域都不进行 GC,那只剩下堆了,是的,这里是 GC 发生的区域!对象实例和数组都是在堆上分配的,GC 也主要对这两类数据进行回收,这块也是我们之后重点需要分析的区域。

如何识别垃圾
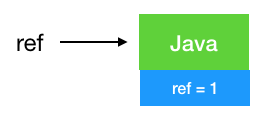
引用计数法
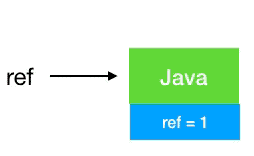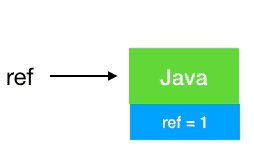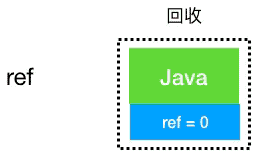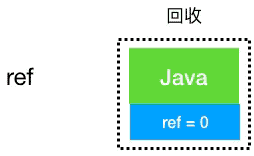
String ref =
new
String(
"Java");
public
class
TestRC {
TestRC instance;
public TestRC(String name) {
}
public static void main(String[] args) {
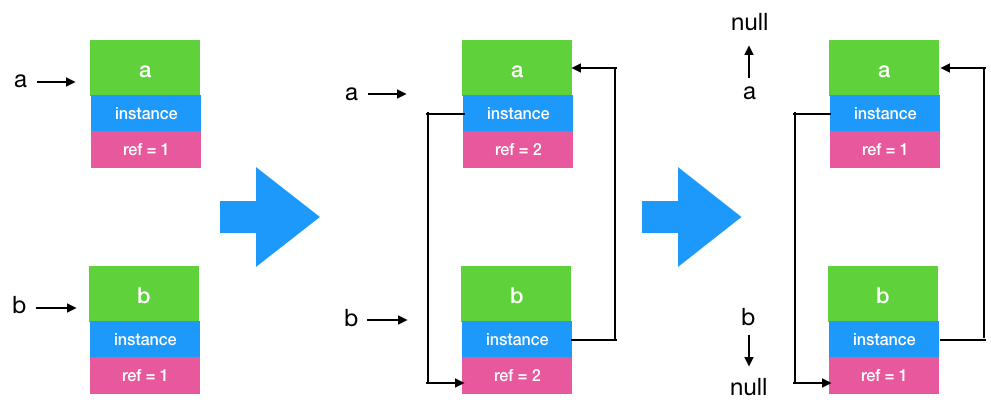
// 第一步
A a =
new TestRC(
"a");
B b =
new TestRC(
"b");
// 第二步
a.instance = b;
b.instance = a;
// 第三步
a =
null;
b =
null;
}
}
可达性算法
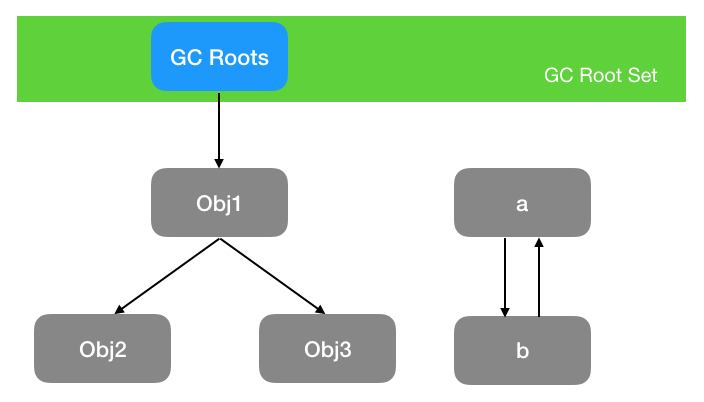
-
虚拟机栈(栈帧中的本地变量表)中引用的对象 -
方法区中类静态属性引用的对象 -
方法区中常量引用的对象 -
本地方法栈中 JNI(即一般说的 Native 方法)引用的对象
虚拟机栈中引用的对象
public
class
Test {
public static void main(String[] args) {
Test a =
new Test();
a =
null;
}
}
方法区中类静态属性引用的对象
public
class
Test {
public
static Test s;
public static void main(String[] args) {
Test a =
new Test();
a.s =
new Test();
a =
null;
}
}
方法区中常量引用的对象
public
class Test {
public
static
final Test s =
new Test();
public static void main(String[] args) {
Test a =
new Test();
a =
null;
}
}
本地方法栈中 JNI 引用的对象
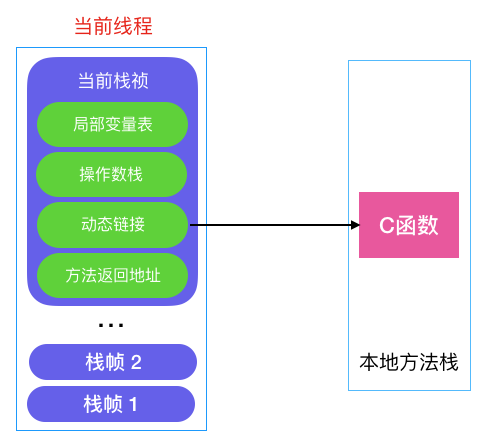
JNIEXPORT void JNICALL Java_com_pecuyu_jnirefdemo_MainActivity_newStringNative(JNIEnv *env, jobject instance,jstring jmsg) {
...
// 缓存String的
class
jclass jc =
(*env)->FindClass(env, STRING_PATH);

垃圾回收主要方法
-
标记清除算法 -
复制算法 -
标记整理法
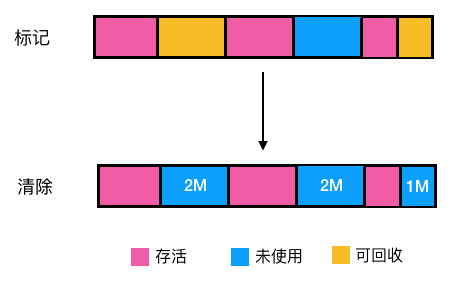
标记清除算法
-
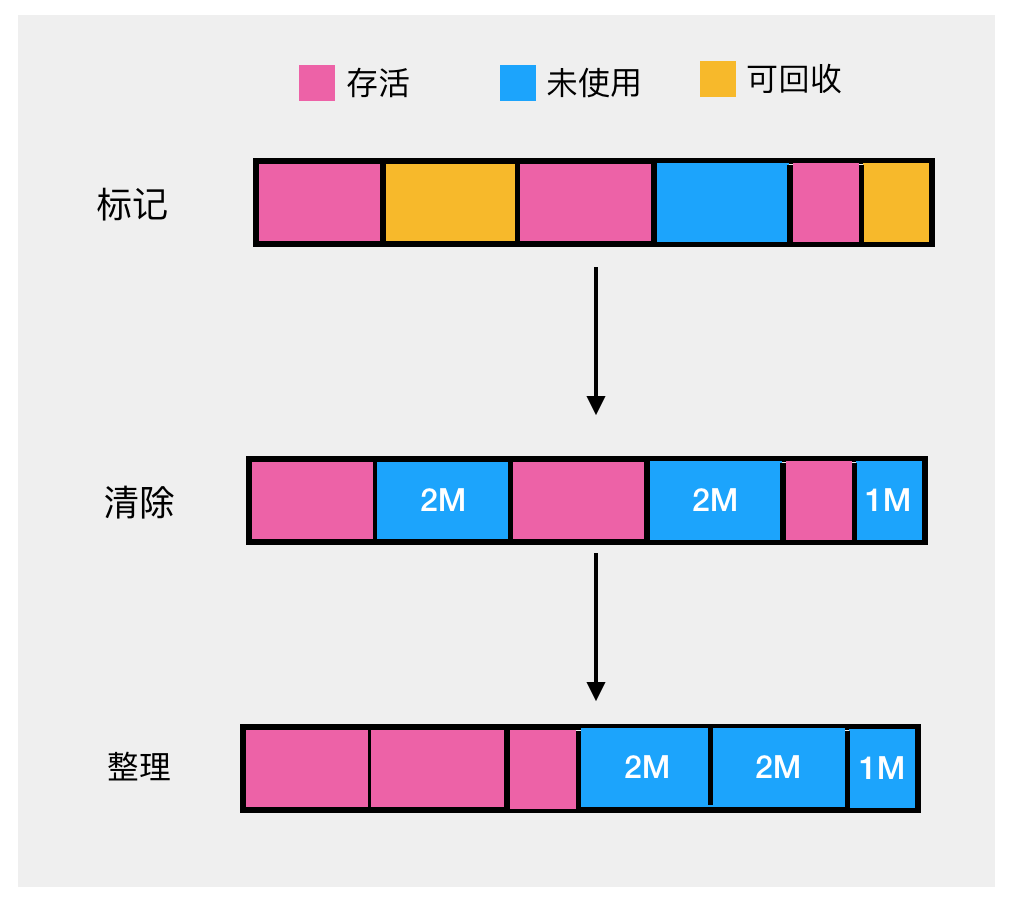
先根据可达性算法标记出相应的可回收对象(图中黄色部分)。 -
对可回收的对象进行回收。 操作起来确实很简单,也不用做移动数据的操作,那有啥问题呢? 仔细看上图,没错,内存碎片! 假如我们想在上图中的堆中分配一块需要连续内存占用 4M 或 5M 的区域,显然是会失败,怎么解决呢,如果能把上面未使用的 2M, 2M,1M 内存能连起来就能连成一片可用空间为 5M 的区域即可,怎么做呢?
复制算法
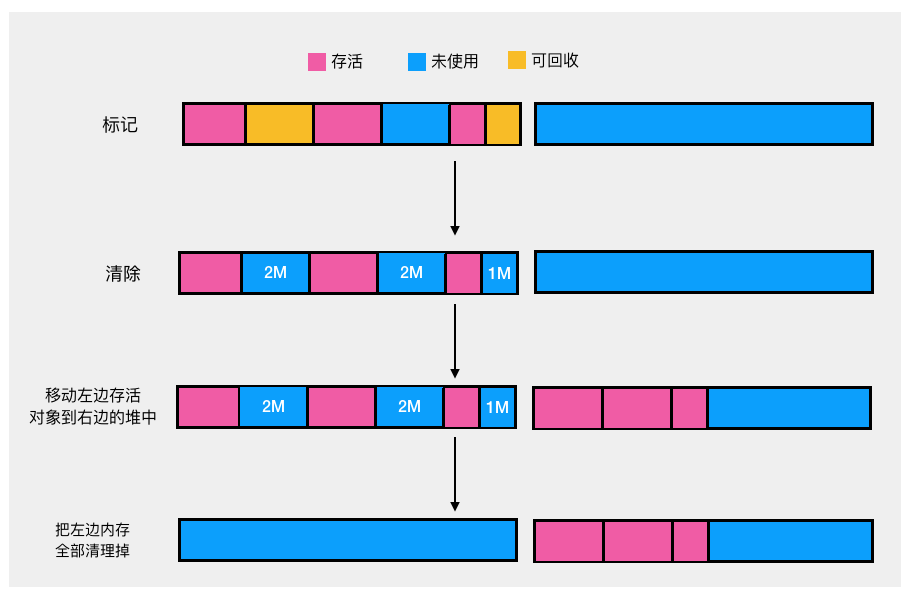
标记整理法
分代收集算法
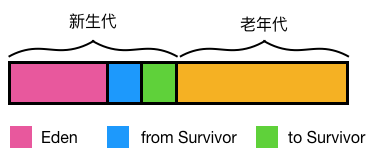
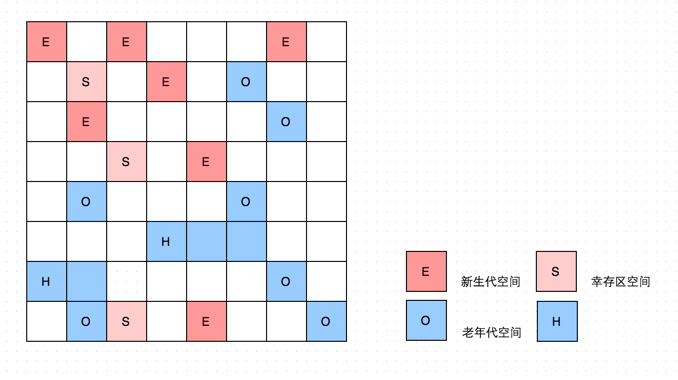
分代收集工作原理

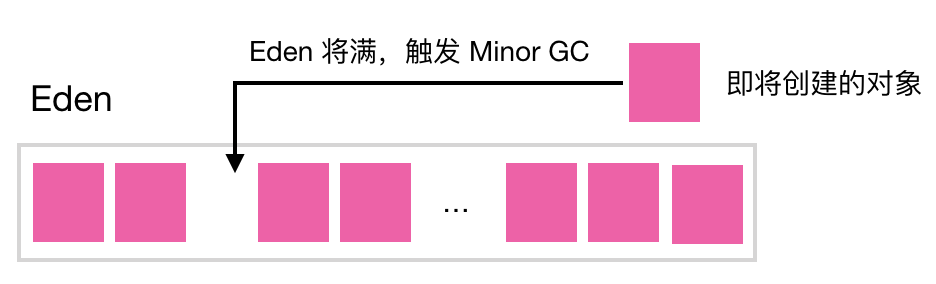
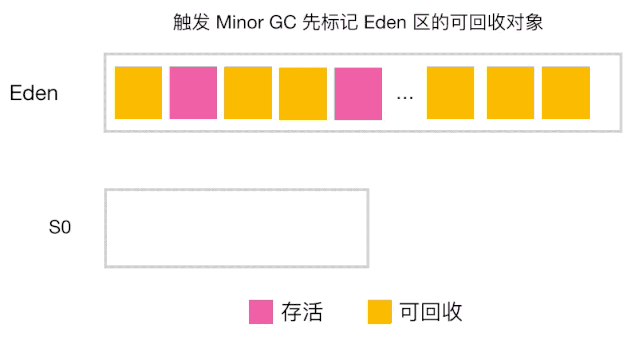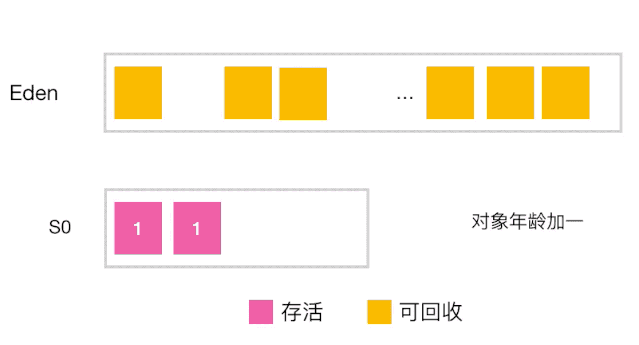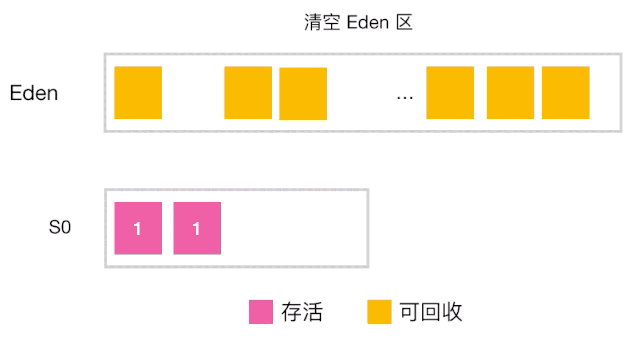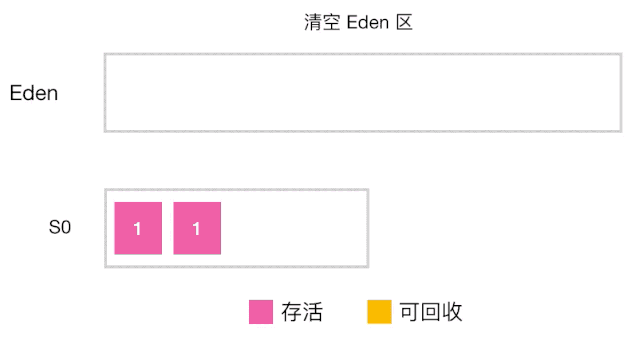
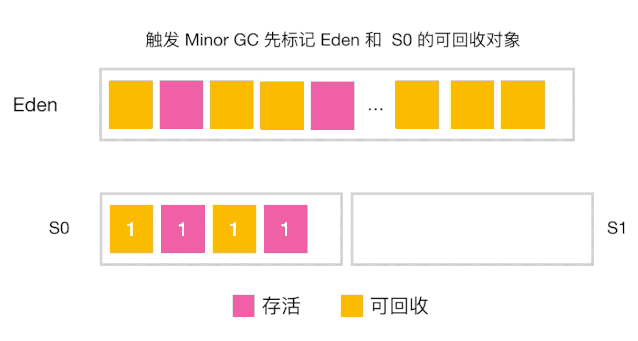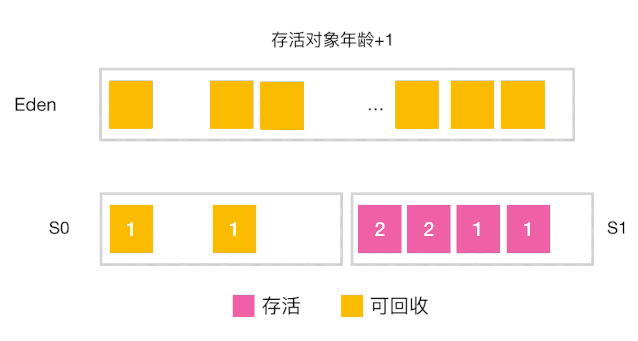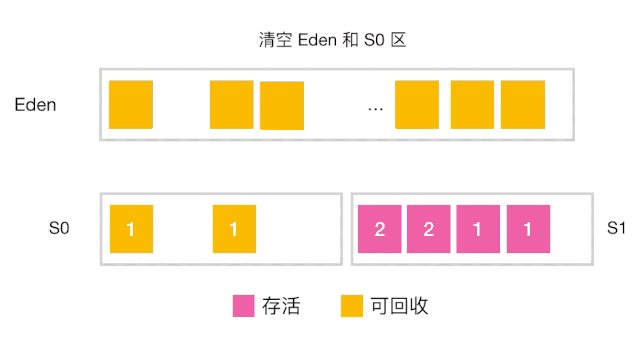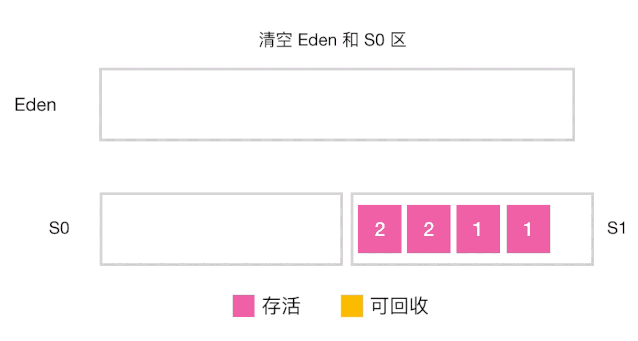
-
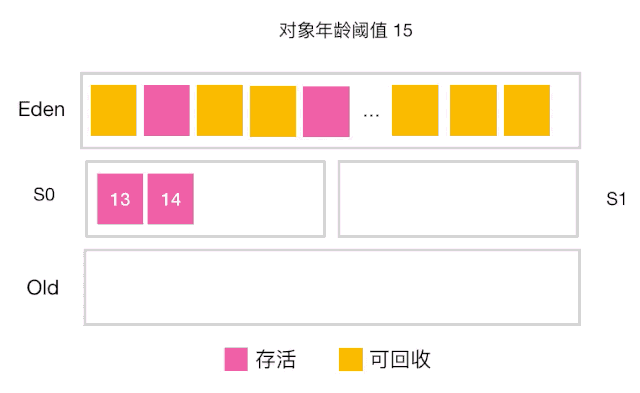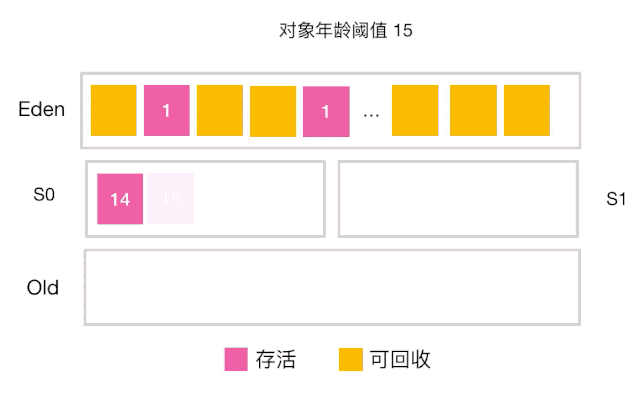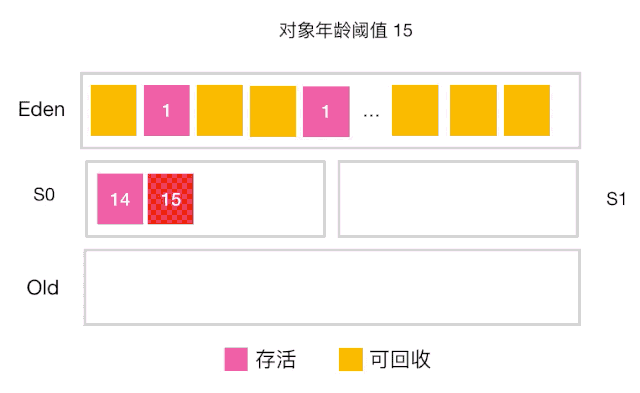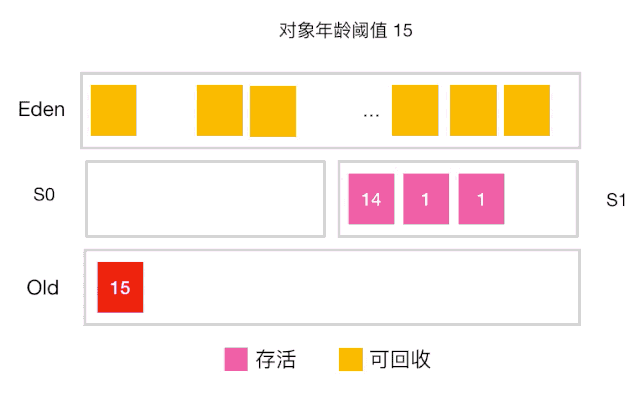
当对象的年龄达到了我们设定的阈值,则会从S0(或S1)晋升到老年代 如图示:年龄阈值设置为 15, 当发生下一次 Minor GC 时,S0 中有个对象年龄达到 15,达到我们的设定阈值,晋升到老年代! -
大对象 当某个对象分配需要大量的连续内存时,此时对象的创建不会分配在 Eden 区,会直接分配在老年代,因为如果把大对象分配在 Eden 区, Minor GC 后再移动到 S0,S1 会有很大的开销(对象比较大,复制会比较慢,也占空间),也很快会占满 S0,S1 区,所以干脆就直接移到老年代. -
还有一种情况也会让对象晋升到老年代,即在 S0(或S1) 区相同年龄的对象大小之和大于 S0(或S1)空间一半以上时,则年龄大于等于该年龄的对象也会晋升到老年代。

-
循环的末尾 -
方法返回前 -
调用方法的 call 之后 -
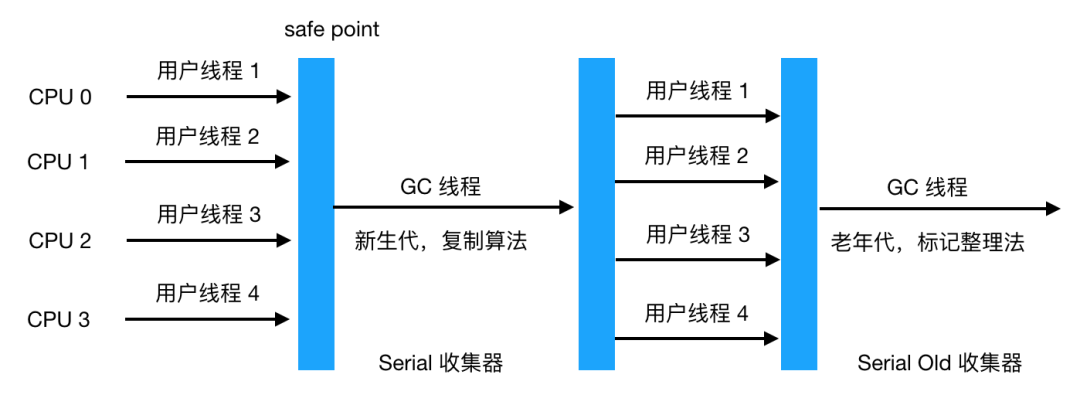
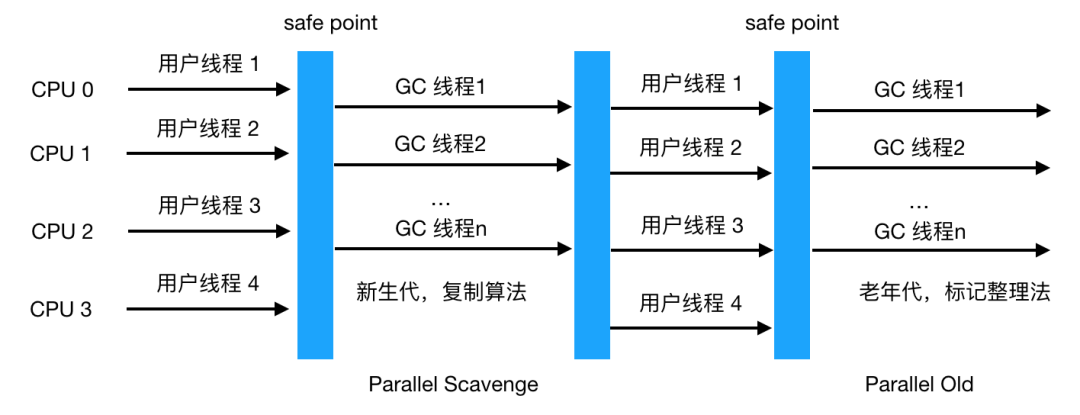
抛出异常的位置 另外需要注意的是由于新生代的特点(大部分对象经过 Minor GC后会消亡), Minor GC 用的是复制算法,而在老生代由于对象比较多,占用的空间较大,使用复制算法会有较大开销(复制算法在对象存活率较高时要进行多次复制操作,同时浪费一半空间)所以根据老生代特点,在老年代进行的 GC 一般采用的是标记整理法来进行回收。

垃圾收集器种类
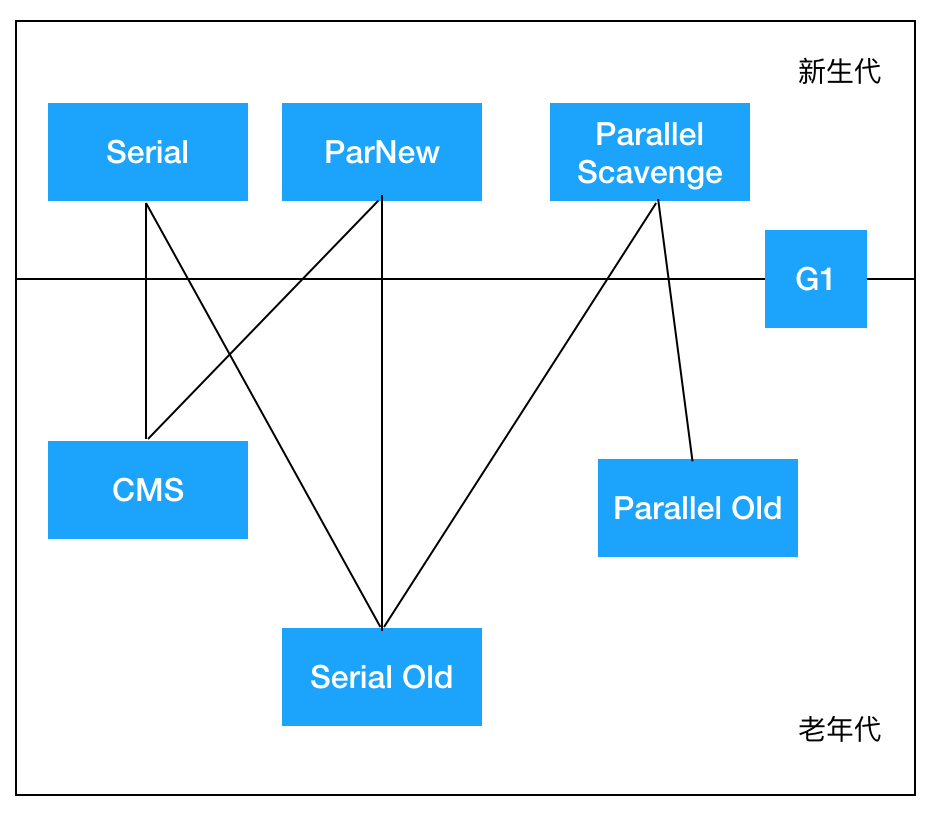
-
在新生代工作的垃圾回收器:Serial, ParNew, ParallelScavenge -
在老年代工作的垃圾回收器:CMS,Serial Old, Parallel Old -
同时在新老生代工作的垃圾回收器:G1
新生代收集器
Serial 收集器
ParNew 收集器
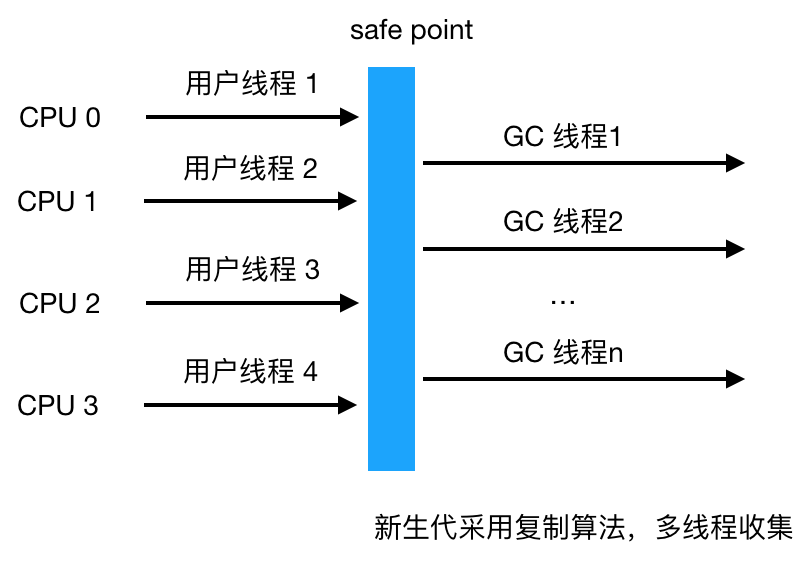
Parallel Scavenge 收集器
老年代收集器
Serial Old 收集器
Parallel Old 收集器
CMS 收集器
-
初始标记 -
并发标记 -
重新标记 -
并发清除
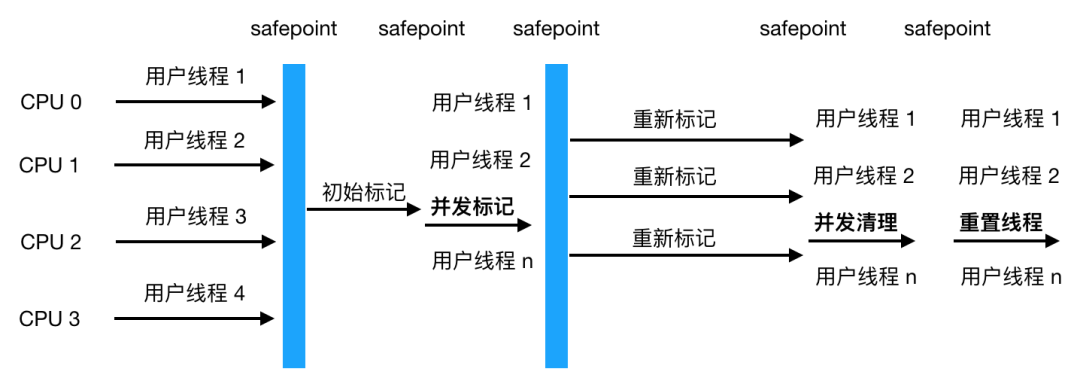
-
CMS 收集器对 CPU 资源非常敏感 原因也可以理解,比如本来我本来可以有 10 个用户线程处理请求,现在却要分出 3 个作为回收线程,吞吐量下降了30%,CMS 默认启动的回收线程数是 (CPU数量+3)/ 4, 如果 CPU 数量只有一两个,那吞吐量就直接下降 50%,显然是不可接受的 -
CMS 无法处理浮动垃圾(Floating Garbage),可能出现 「Concurrent Mode Failure」而导致另一次 Full GC 的产生,由于在并发清理阶段用户线程还在运行,所以清理的同时新的垃圾也在不断出现,这部分垃圾只能在下一次 GC 时再清理掉(即浮云垃圾),同时在垃圾收集阶段用户线程也要继续运行,就需要预留足够多的空间要确保用户线程正常执行,这就意味着 CMS 收集器不能像其他收集器一样等老年代满了再使用,JDK 1.5 默认当老年代使用了68%空间后就会被激活,当然这个比例可以通过 -XX:CMSInitiatingOccupancyFraction 来设置,但是如果设置地太高很容易导致在 CMS 运行期间预留的内存无法满足程序要求,会导致 Concurrent Mode Failure 失败,这时会启用 Serial Old 收集器来重新进行老年代的收集,而我们知道 Serial Old 收集器是单线程收集器,这样就会导致 STW 更长了。 -
CMS 采用的是标记清除法,上文我们已经提到这种方法会产生大量的内存碎片,这样会给大内存分配带来很大的麻烦,如果无法找到足够大的连续空间来分配对象,将会触发 Full GC,这会影响应用的性能。当然我们可以开启 -XX:+UseCMSCompactAtFullCollection(默认是开启的),用于在 CMS 收集器顶不住要进行 FullGC 时开启内存碎片的合并整理过程,内存整理会导致 STW,停顿时间会变长,还可以用另一个参数 -XX:CMSFullGCsBeforeCompation 用来设置执行多少次不压缩的 Full GC 后跟着带来一次带压缩的。
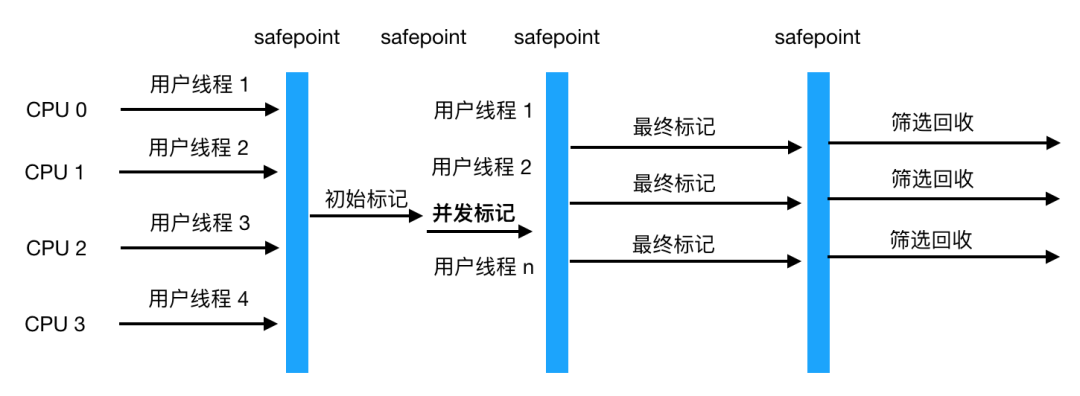
G1(Garbage First) 收集器
-
像 CMS 收集器一样,能与应用程序线程并发执行。 -
整理空闲空间更快。 -
需要 GC 停顿时间更好预测。 -
不会像 CMS 那样牺牲大量的吞吐性能。 -
不需要更大的 Java Heap
-
运作期间不会产生内存碎片,G1 从整体上看采用的是标记-整理法,局部(两个 Region)上看是基于复制算法实现的,两个算法都不会产生内存碎片,收集后提供规整的可用内存,这样有利于程序的长时间运行。 -
在 STW 上建立了可预测的停顿时间模型,用户可以指定期望停顿时间,G1 会将停顿时间控制在用户设定的停顿时间以内。
-
初始标记 -
并发标记 -
最终标记 -
筛选回收

总结
【END】
推荐阅读
☞黑莓手机将停售;三大运营商:疫情防控期间用户欠费不停机;Chrome 测试移除搜索结果页网址 | 极客头条

登录查看更多
相关内容

Java 虚拟机(Java Virtual Machine)是一个虚构出来的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。
Arxiv
4+阅读 · 2018年7月29日
Arxiv
11+阅读 · 2018年5月21日
Arxiv
9+阅读 · 2018年3月22日





相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年7月29日
Arxiv
11+阅读 · 2018年5月21日
Arxiv
9+阅读 · 2018年3月22日