Petascale AI芯片Vathys:靠谱项目?清奇脑洞?还是放卫星?
我之前连续介绍了一下Graphcore和Groq的进展,本来打算开始写全年总结了。没想到年底又冒出一个Startup,Vathys,在Stanford做了一个介绍,题目是“Petascale Deep Learning on a Single Chip”。又把Deep Learning处理器的指标推到了Petascale。这个项目到底靠谱不靠谱我不好评价,不过他们提出的脑洞倒是挺有意思的,还是一起看看吧。
最新消息
正在我开始写这篇文章的时候,突然收到Vathys的老板给我的gitub AI Chip list提的issue,说应该把他们公司加到list中。大家可以感受一下。
我之所以犹豫,正如我在回答中所写,这个初创公司做的几件事情太牛了。下面我和大家一起简单看看,想了解细节的同学可以详细看看他们的视频。
•••
几个重要工作(脑洞?)
他们首先提出的目标就是“1 PetaFLOP of compute (fp8/fp16)”,当然这个指标是针对fp8/fp16的运算。同时,他们也分析了实现这个目标的挑战是什么。

所以,要实现上述目标就需要达到目前各种方案5-10倍的性能。为此,他们在几个层面做了工作。
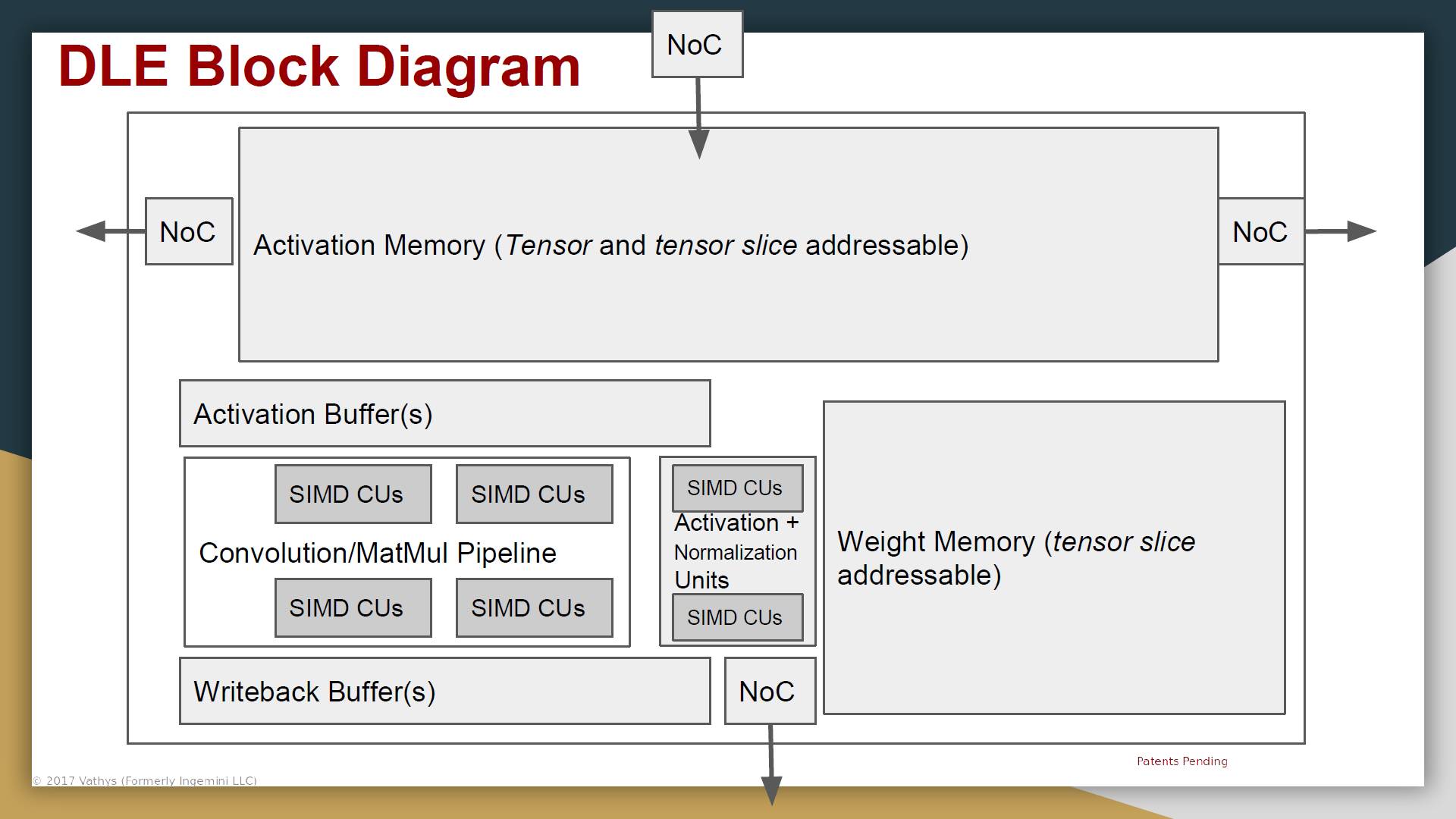
1. 首先是架构层面。其中大部分想法我们并不陌生,亮点应该是“True dataflow”(虽然后来也没有说清楚具体是什么意思)和“Tensor native” memory architecture。后者似乎是个不错的脑洞。

最后是说一个DLE所需的memory都放在片上,不需要片外的memory。DLE的具体架构如下,比较类似CGRA的架构。

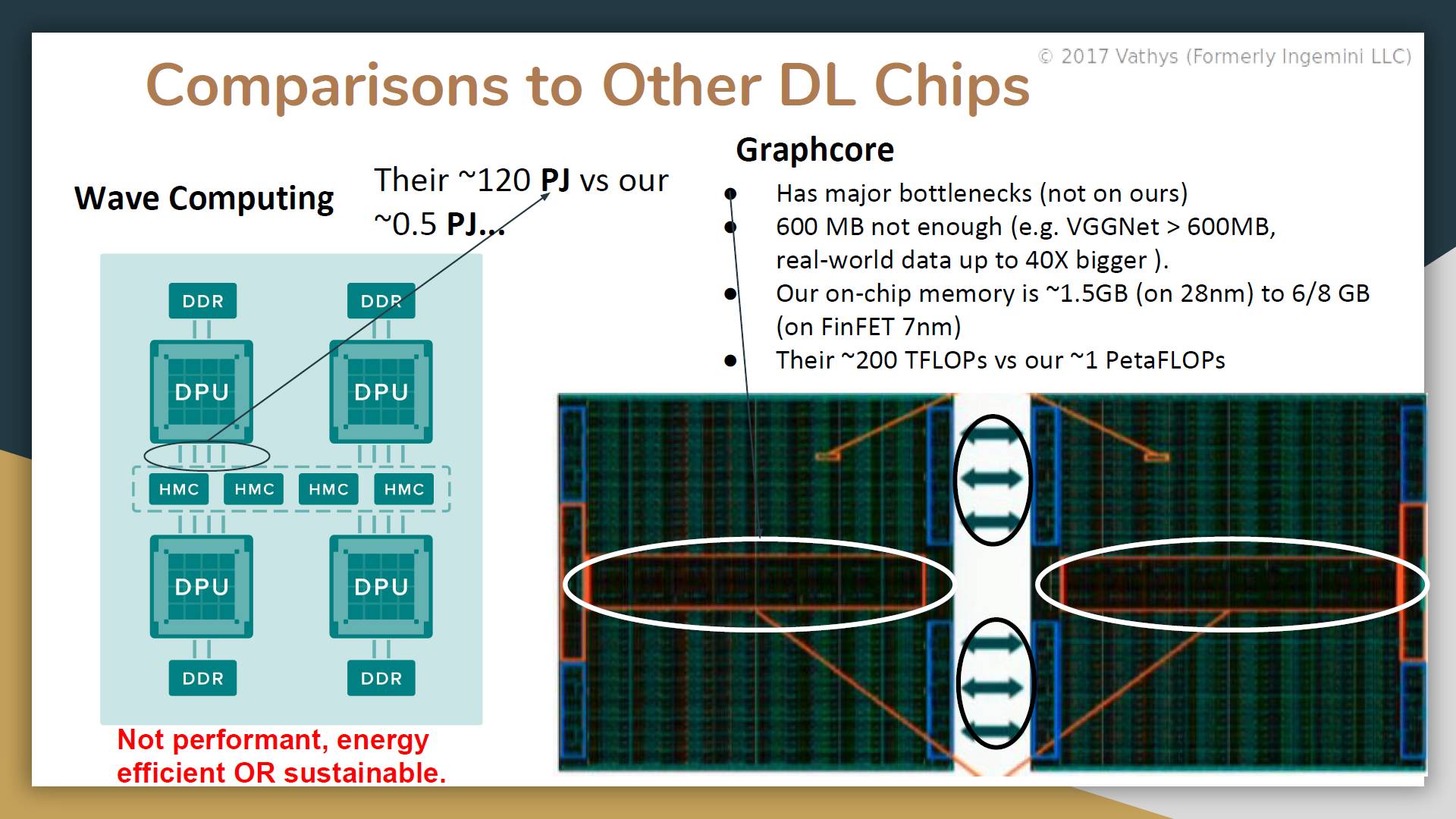
2. 除了架构级的工作,他们在电路级做了如下一些事情。其中的关键字是“True asynchronous logic”,结果是他们可以在28nm工艺下实现大约12GHz的“Clock”。还记得Wave Computing吗?他们也做了clockless的设计,达到的等效速率是6.7GHz(16nm)。

3. 第三个重要工作是片上的Memory Cell,看起来也非常厉害。可以实现比目前普通的SRAM高5或10倍的密度,也就意味着同样的面积可以实现更多的片上存储空间。按他们的说法是“Our on-chip memory is ~1.5GB (on 28nm) to 6/8 GB(on FinFET 7nm)”(相比之下Graphcore的300MB也是小儿科了)。在演讲中,他还强调了实现这样的密度可以只使用普通的CMOS工艺。

4. 最后一个重大工作是“Wireless 3D Stacking”。在讲演中也说了这项技术的诸多优势。如果大家熟悉这个领域,就可以了解如果能实现的话意味着什么。

•••
对比
当然,他们也把其它Deep Learning处理器拿出来“吊打”了一遍。我就一一贴出来了,只看看只看看Wave Computing和Graphcore的对比(Graphcore的信息还是比较新的,参考Graphcore AI芯片:更多分析)。简单结论就是:甩其它人几条街啊。
另外一个比较有意思的是和模拟设计的对比,倒是指出了目前模拟设计的一些问题。

•••
这真的可能吗?
我之前也算看过各种各样的Deep Learning处理器了。不过,看到Vathys的东西,我还是有一种WTF的感觉。于是我也请教了一下业界和学界的好几位专家的看法,大家总的来说持保留的态度。因为,Vathys所说的几件事情,Asynchronous Logic,High-density Memory,Wireless 3D stacking,任何一件都非常困难,之前没有看到过谁能把这几件事情做好,更别说一个初创公司同时能解决所有这些问题了。
不过,从另一个角度来看,他们提出的这几个技术确实可以说能够解决Deep Learning的痛点,如果能实现的话。。。有点不敢想象了。

好在他们还给出了具体的Timeline。所以,Vathys到底是靠谱项目?清奇脑洞?还是仅仅放个卫星?我们并不用等很久就可以知道答案了。

题图来自网络,版权归原作者所有
通过DARPA项目看看芯片世界的“远方”- 自动化工具和开源硬件




