3行代码3分钟,搞定NLP模型开发!只要你会中文就行
![]()
新智元报道
【新智元导读】中文NLP从未如此简单!
想做一个多任务自然语言处理模型,需要会什么技能?


举个栗子
举个栗子
新闻分类(classify)
Input:
新闻分类:
今天(3日)稍早,中时新闻网、联合新闻网等台媒消息称,佩洛西3日上午抵台“立法院”,台湾新党一早8时就到台“立法院”外抗议,高喊:“佩洛西,滚蛋!”台媒报道称,新党主席吴成典表示,佩洛西来台一点道理都没有,“平常都说来者是客,但这次来的是祸!是来祸害台湾的。”他说,佩洛西给台湾带来祸害,“到底还要欢迎什么”。
选项:财经,法律,国际,军事
答案:
Model output:
国际
意图分类(classify)
Input:
意图分类:
帮我定一个周日上海浦东的房间
选项:闹钟,文学,酒店,艺术,体育,健康,天气,其他
答案:
Model output:
酒店
情感分析(classify)
Input:
情感分析:
这个看上去还可以,但其实我不喜欢
选项:积极,消极
答案:
Model output:
消极
推理(generate)
Input:
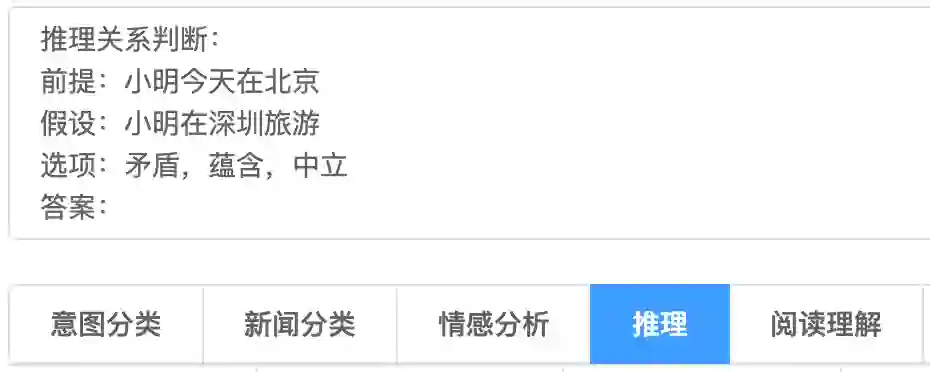
推理关系判断:
前提:小明今天在北京
假设:小明在深圳旅游
选项:矛盾,蕴含,中立
答案:
Model output:
矛盾
阅读理解(generate)
Input:
阅读理解:
段落:海外网8月2日电据美国《国会山报》8月1日报道,三名美国众议院议员日前致信美国政府问责局(GAO),要求审查联邦政府应对猴痘疫情的措施是否充分。
在信中,三名众议员称美国的公共卫生系统“严重受损”,联邦政府应对猴痘疫情行动迟缓,分发试剂和疫苗的工作出现延误,影响了遏制疫情传播的能力,而数百万剂的猴痘疫苗历经数月才获得批准,从一家丹麦工厂发往美国。
议员们还要求美国政府问责局审查美疾病控制和预防中心、食品和药物管理局、国土安全部,查明这些联邦机构是否为应对猴痘疫情做出了充分准备,是否借鉴了应对新冠疫情的经验教训。
美媒称,几个星期以来,美国国会议员频频就猴痘疫情应对措施向联邦政府施压,呼吁政府宣布进入公共卫生紧急状态。截至目前,美国疾病控制与预防中心已经确认了5000多例猴痘病例。考虑到仍有许多民众无法进行猴痘病毒检测,当前的病例数可能被低估。
问题:联邦政府应对疫情有什么问题?
答案:
Model output:
联邦政府应对猴痘疫情行动迟缓,分发试剂和疫苗的工作出现延误,影响了遏制疫情传播的能力
阅读理解-自由式(generate)
Input:
阅读以下对话并回答问题。
男:今天怎么这么晚才来上班啊?女:昨天工作到很晚,而且我还感冒了。男:那你回去休息吧,我帮你请假。女:谢谢你。
问题:女的怎么样?
选项:正在工作,感冒了,在打电话,要出差。
答案:
Model output:
感冒了
摘要(generate)
Input:
为下面的文章生成摘要:
北京时间9月5日12时52分,四川甘孜藏族自治州泸定县发生6.8级地震。地震发生后,领导高度重视并作出重要指示,要求把抢救生命作为首要任务,全力救援受灾群众,最大限度减少人员伤亡
答案:
Model output:
四川甘孜州泸定县发生6.8级地震
翻译-中英(generate)
Input:
翻译成英文:
议长去了台湾,中国人民很愤怒。
答案:
Model output:
The Speaker went to Taiwan, and the Chinese people were angry.
翻译-英中(generate)
Input:
翻译成中文:
This is a dialogue robot that can talk to people.
答案:
Model output:
这是一个能与人对话的机器人。
通用信息抽取(generate)
Input:
信息抽取:
据新华社电广东省清远市清城区政府昨日对外发布信息称,日前被实名举报涉嫌勒索企业、说“分分钟可以搞垮一间厂”的清城区环保局局长陈柏,已被免去清城区区委委员
问题:机构名,人名,职位
答案:
Model output:
机构名:新华社,清城区环保局,清城区区委
人名:陈柏
职位:局长
简历信息抽取(generate)
Input:
阅读文本抽取关键信息:
张玄武2000年出生中国国籍无境外居留权博士学历现任杭州线锁科技技术总监。
问题:机构,人名,职位,籍贯,专业,国籍,学历,种族
答案:
Model output:
机构:杭州线锁科技
人名:张玄武
职位:技术总监
国籍:中国国籍
学历:博士学历
医疗信息抽取(generate)
Input:
找出指定的信息:
我今天胃不舒服,手有点麻木,浑身不舒服,前几天去医院医生说我有胃炎
问题:症状,治疗,检查,身体部位,疾病
答案:
Model output:
症状:胃不舒服,麻木,浑身不舒服,胃炎
电商客户需求分析(classify)
Input:
电商客户诉求分类:
收到但不太合身,可以退换吗
选项:买家咨询商品是否支持花呗付款,买家表示收藏关注店铺,买家咨询退换货规则,买家需要商品推荐
答案:
Model output:
买家咨询退换货规则
医疗语义相似度(classify)
Input:
下面句子是否表示了相同的语义:
文本1:糖尿病腿麻木怎么办?
文本2:糖尿病怎样控制生活方式
选项:相似,不相似
答案:
Model output:
不相似
问题生成(generate)
Input:
问题生成:
中新网2022年9月22日电 22日,商务部召开例行新闻发布会,商务部新闻发言人束珏婷表示,今年1-8月,中国实际使用外资1384亿美元,增长20.2%;其中,欧盟对华投资增长123.7%(含通过自由港投资数据)。这充分表明,包括欧盟在内的外国投资者持续看好中国市场,希望继续深化对华投资合作。
答案:
Model output:
1、今年1-8月,中国实际使用外资增长了多少? 2、欧盟对华投资增长了多少?
指代消解(generate)
Input:
代词指向哪个名词短语:
段落:
当地时间9月21日,英国首相特拉斯在纽约会见了美国总统拜登。随后她便在推特上发文强调,英美是坚定盟友。推文下方还配上了她(代词)与拜登会面的视频。
问题:代词“她”指代的是?
答案:
Model output:
特拉斯
关键词抽取(generate)
Input:
抽取关键词:
当地时间21日,美国联邦储备委员会宣布加息75个基点,将联邦基金利率目标区间上调到3.00%至3.25%之间,符合市场预期。这是美联储今年以来第五次加息,也是连续第三次加息,创自1981年以来的最大密集加息幅度。
关键词:
Model output:
美联储,加息75个基点,加息幅度
情感倾向(classify)
Input:
文字中包含了怎样的情感:
超可爱的帅哥,爱了。。。
选项:厌恶,喜欢,开心,悲伤,惊讶,生气,害怕
答案:
Model output:
喜欢
自定义(generate)
Input:XXXX:YYYY
模型简介
当调用clueai的API时,我们为用例指定默认模型。默认模型非常适合开始使用,但是在生产环境中,我们建议通过model_name参数自己指定特定模型。
返回结果
对于不同的任务返回相对应的clueai对象(例如,对于分类,将是“Classification”)。
一键安装
一键安装
ClueAI支持通过pip安装Python软件包,以简化在python3中与clueai API的接口。
pip install --upgrade clueai
也可以通过源码安装
python setup.py install
如果暂时不想在本地安装,也可以在Colab中一键运行使用。
链接:https://colab.research.google.com/drive/1H5J03ek3kpKschQ32mhX-y0JyRo1mIXN#scrollTo=zMSp1naSL8X9
使用时也很方便,如果是基础模型直接运行即可,尝试大模型需要在ClueAI官方网站获取api-key才能使用。
代码接口针对文本分类和文本生成任务分别设计。
文本分类
python代码如下:
import clueaifrom clueai.classify import Examplecl = clueai.Client("", check_api_key=False)response = cl.classify(model_name='clueai-base',task_name='产品分类',inputs=["强大图片处理器,展现自然美丽的你,,修复部分小错误,提升整体稳定性。", "求闲置买卖,精品购物,上畅易无忧闲置商城,安全可信,优质商品有保障"],labels = ["美颜", "二手", "外卖", "办公", "求职"])print('prediction: {}'.format(response.classifications))
也可以用curl命令访问api
curl --location --request POST 'modelfun.cn/modelfun/ap' \--header 'Content-Type: application/json' \--header 'Model-name: clueai-base' \--data '{"task_type": "classify","task_name": "产品分类","input_data": ["强大图片处理器,展现自然美丽的你,,修复部分小错误,提升整体稳定性。", "求闲置买卖,精品购物,上畅易无忧闲置商城,安全可信,优质商品有保障"],"labels": ["美颜", "二手", "外卖", "办公", "求职"]}'
文本生成
import clueai
# initialize Clueai Client with an API Key
cl=clueai.Client("",check_api_key=False)
prompt= '''
摘要:
本文总结了十个可穿戴产品的设计原则,而这些原则,同样也是笔者认为是这个行业最吸引人的地方:1.为人们解决重复性问题;2.从人开始,而不是从机器开始;3.要引起注意,但不要刻意;4.提升用户能力,而不是取代人
答案:
'''
# generate a prediction for a prompt
prediction = cl.generate(
model_name='clueai-base',
prompt=prompt)
# print the predicted text
print('prediction: {}'.format(prediction.generations[0].text))
curl --location --request POST 'modelfun.cn/modelfun/ap' \
--header 'Content-Type: application/json' \
--header 'Model-name: clueai-base' \
--data '{
"task_type": "generate",
"task_name": "摘要",
"input_data": ["摘要:\n本文总结了十个可穿戴产品的设计原则,而这些原则,同样也是笔者认为是这个行业最吸引人的地方:1.为人们解决重复性问题;2.从人开始,而不是从机器开始;3.要引起注意,但不要刻意;4.提升用户能力,而不是取代人\n答案:"]
}'
点击「阅读原文了解更多」~
参考资料:
https://mp.weixin.qq.com/s/wkHItMnttReKpLd5nFmwDw





