360首席科学家颜水成:人工智能杂谈 | 北大AI公开课笔记
主讲人:颜水成 | 360首席科学家
整理:俞晶翔 伦敦
量子位 出品 | 公众号 QbitAI
4月25日周三晚,北京大学“人工智能前沿与产业趋势”第九讲,本期360首席科学家颜水成,分享了人工智能的理想与现实,深度学习的模型与应用,也为大家介绍了人工智能与安全的关系。
讲解内容清晰透彻,量子位作为独家合作媒体,为大家带来详细课程笔记一份。
课程导师:雷鸣,天使投资人,百度创始七剑客之一,酷我音乐创始人,北京大学信科人工智能创新中心主任,2000年获得北京大学计算机硕士学位,2005年获得斯坦福商学院MBA学位,同时也是“千人计划”特聘专家。
主讲嘉宾:颜水成,360集团副总裁、人工智能研究院院长,千人计划特聘专家,IEEE Fellow, IAPR Fellow 及 ACM 杰出科学家。他的主要研究领域是计算机视觉、机器学习与多媒体分析,发表了500+篇高质量学术论文,2014、2015、 2016 三次入选全球高引用学者 ( TR Highly-cited researchers )。
他领导的团队是计算机视觉领域两个核心竞赛Pascal VOC 2012收官之战和ImageNet 2017收官之战的双料冠军团队,曾取得多媒体领域核心会议 ACM MM 最佳论文奖,最佳学生论文奖,最佳技术演示奖的大满贯。
人工智能理想与现实
今天我更多是作为北大校友,分享自己从学生到老师,从学术界到工业界,在AI上趟过的一些坑,并不是一场深度的学术讨论,其中大部分内容已在过去两年的行业会议上分享过。以下是今天的topics:

人工智能的理想
人的天性会追求成功。对于AI从业者来说,不同的角色成功的标准是什么呢?一帮朋友和我有过这样的讨论:
1、AI的PHD,如果毕业前能有第一作者单篇引用过百的论文,基本可以说是一个非常成功的PHD毕业生;
2、AI 的研究者,比如说研究所或者高校的教授,如果有第一作者单篇引用过千的论文,那么基本可以说是AI领域非常不错的研究者。
3、AI的创业者,假如说要做APP相关的产品,如果有一款产品的DAU能达到五千万的话,在中国就算非常成功了。
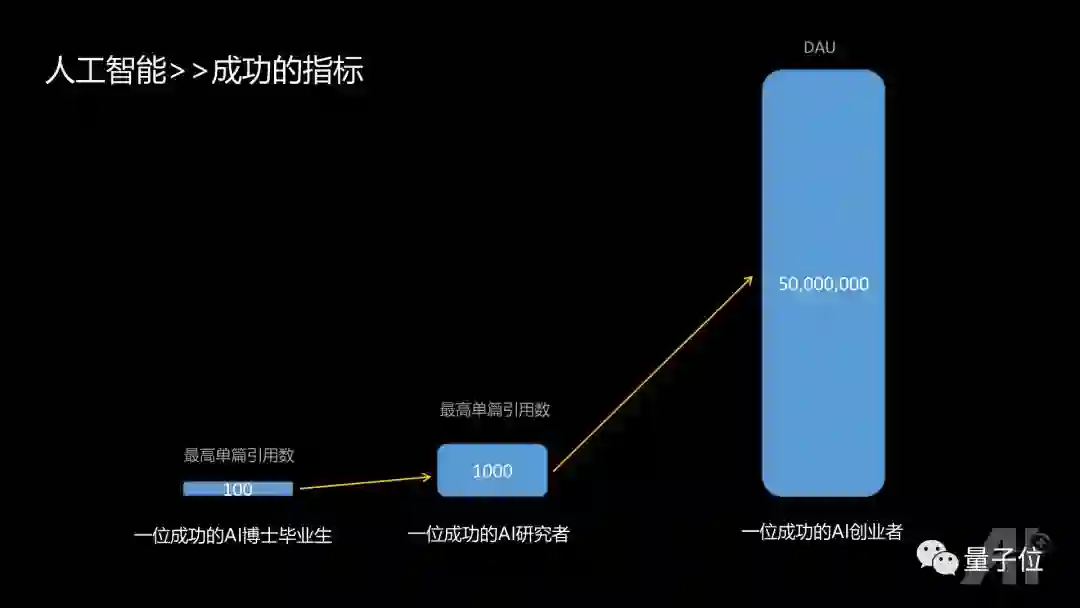
价值在于稀缺性,现在每年AI相关论文有四千多篇被接收。因为不稀缺,所以量已经不那么重要,单篇影响力反而更重要。
AI表面上看起来风头正盛,但是现实其实还非常的骨感。

比如说在自动驾驶方面,在2016年,特斯拉就因为没有识别出大货车,直接撞上导致了交通事故;今年Uber在路测中,撞上了横穿马路的人。对于自动驾驶,一些公司有些过于乐观,而当前技术其实并没有达到期望水平,前面的路还很长。
记得有位前辈说过一个很有趣的假设:假如发生了一场灾难,地上的车道线都没有了,旁边的参照物也都没有,你会愿意把你的生命交托给自动驾驶车辆,还是希望这辆车有一个方向盘由自己来把控?短期内,我们不要太期望路上跑的车都是自动驾驶的。
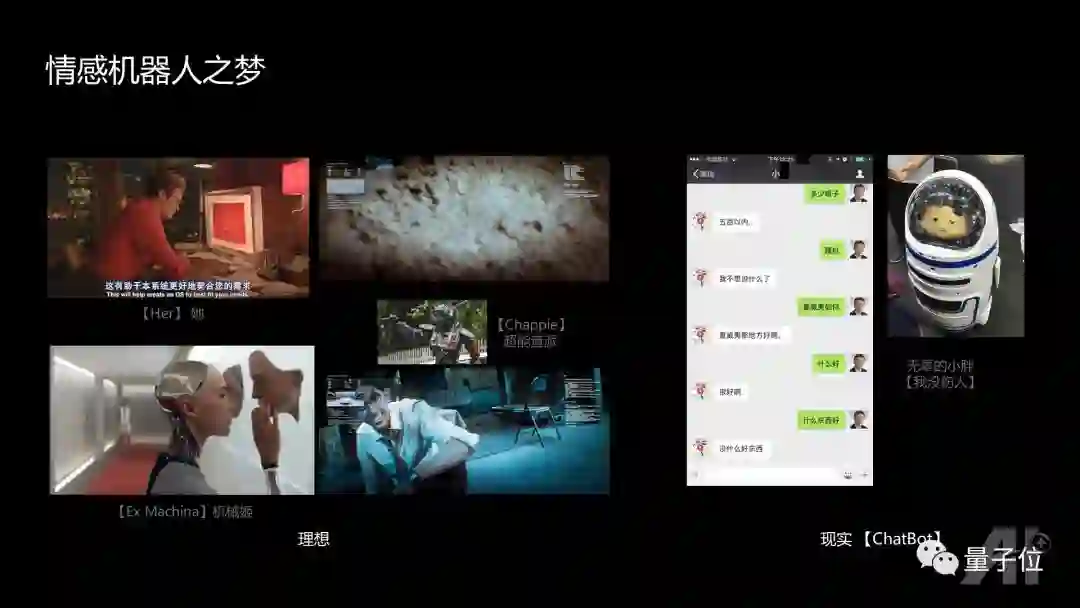
而对于情感机器人,大家都有一个梦想:可以通过语音与虚拟角色进行情感交流。电影《超能查派》中的机器人,我觉得是未来情感机器人最可能的样子:机器人在一开始具备一些基本的能力,能够在路上行走,进行简单交流,他的智能是通过和周围环境里面的人进行交互,以及机器人自己在家里看一些影视材料,去逐步提升的,最后具备接近小朋友水平的智能。
然而现在的现实是什么呢?这是我跟一个已经非常成功的聊天机器人聊天的过程:
“我想出去旅游” “泰国吧”
“多少银子?” “五百以内…”
“瞎扯”“我不想说什么了”
“夏威夷如何”“夏威夷那地方好啊。”
“什么好”“很好啊。”
“什么东西好”“没什么好东西。”
开始还不错,到后面就和上下文完全无关了。核心的原因在于聊天机器人的整个原理主要还是参考搜索技术,和人的沟通机理是完全不同的。
此外,人类一直担心机器人的安全性。去年在深圳的高交会上,机器人砸了玻璃伤到了人,无论当时具体情况是怎样的,反映出人类对机器人的安全性一直处在惊弓之鸟状态。
人工智能的现实
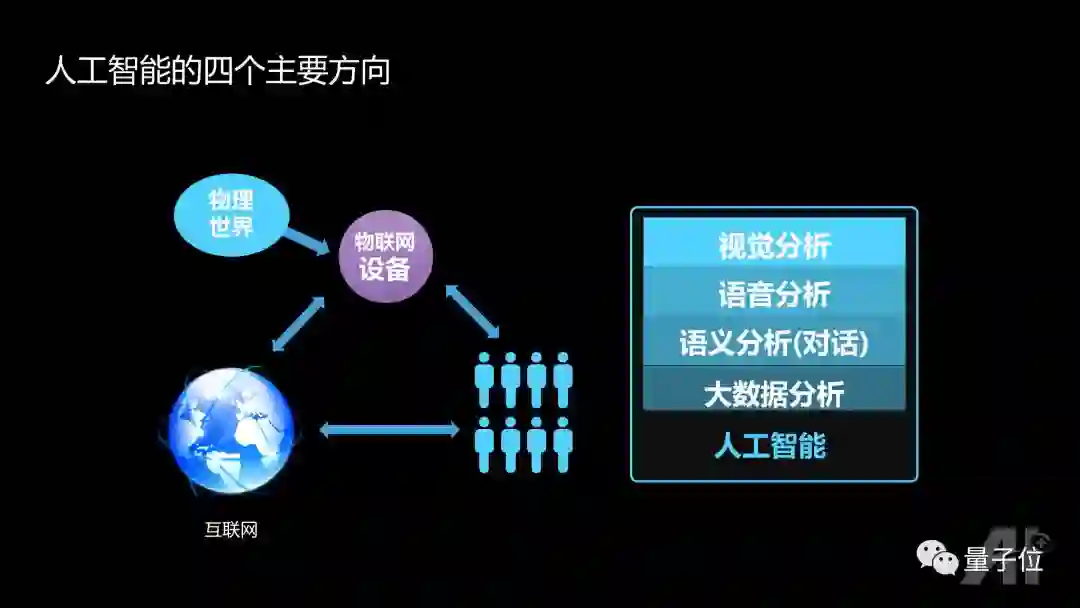
人工智能具体在干些什么呢?从交互的角度来说,主要处理人、互联网、物联设备、物理世界这四者的关系,涉及到的数据包括视觉、语音、语义、大数据。

人工智能研发有三种不同的状态:
初创公司,专注于某一产品或者某一领域,所有研发者都非常聚焦。 百亿美金级公司,比如Pre-IPO的公司,公司内部往往有一个AI实验室/平台部门,对这个公司所有的AI需求作全方位的支持。千亿级美金的公司,每个事业部有各自的有侧重点的人工智能团队,当公司准备启动一个AI的新产品,不同的团队可以提供不同的方案,胜出者则主导这个产品,对于大公司来说这对于保障成功性很有意义。
对于AI研究者,应提前清楚自己喜欢的风格,然后确定自己进哪种公司发展。

人工智能解决两类不同的问题:一类问题是soft-tasks,只要有一点点进展,就能带来很及时的效益,比如说广告推荐技术,每提高一个百分点,都具有非常大的价值。另一类是hard-tasks,很长一段时间是默默无闻的,要等技术积累到一定水平,性能达到一定阈值,才能快速推动商业化。
你是想做一个时刻都被关注的人,还是想先默默无闻,最后爆发,在选择公司和业务的时候也需要做一个提前的考虑。
人工智能的四元分析
接下来用四元分析的方法来跟大家介绍在学术界和工业界做人工智能的差别。
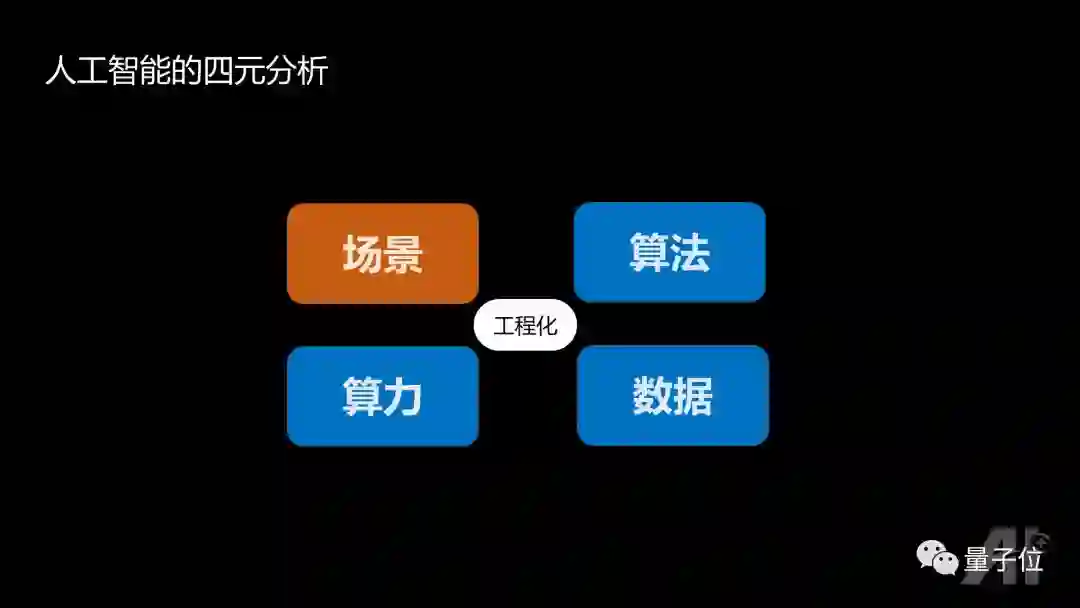
2016年大家都在讨论,人工智能具有三要素:算法、算力、数据;而在2017年,大家开始重视场景,能落地的AI才有价值。
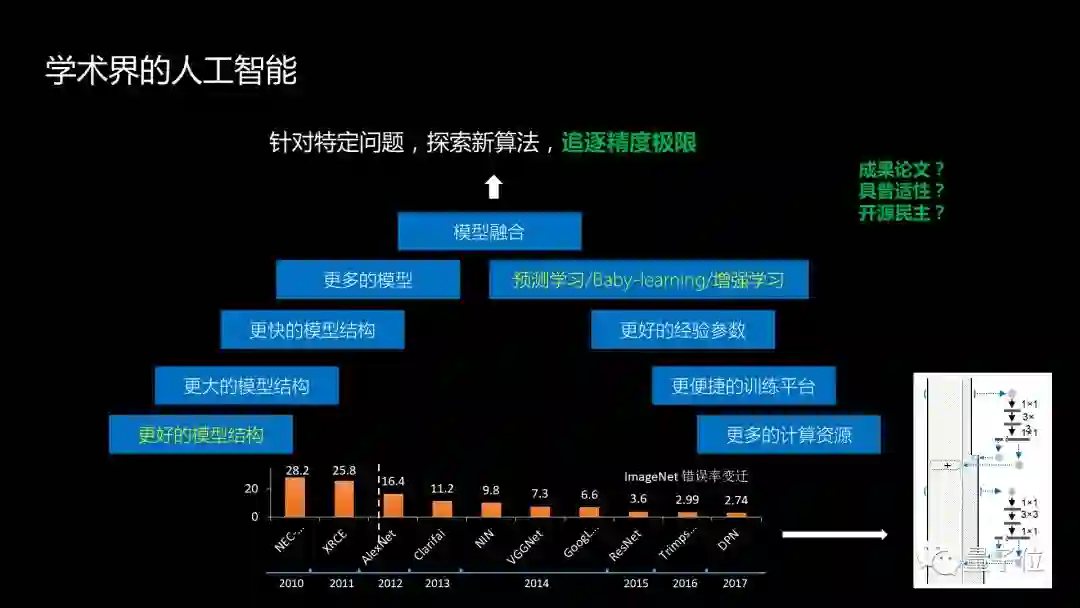
在学术界,比如说在深度学习领域,往往导师会先把问题定义好,学生们要做的事情就是想尽一切办法,让这个问题求解的精度达到一个新的极限。比如说用更好、更大、更快的模型,更多的模型融合,同时希望有更多的计算机资源,有更便捷的训练平台,更好的经验参数,最终追求的是精度,发表有价值的学习论文,同时希望些方法具有普适性,可以帮助其他问题的求解。其次也希望做出来的东西能开源,社会上大大小小的公司都可以充分利用你的开源来提升自己的商业化能力。
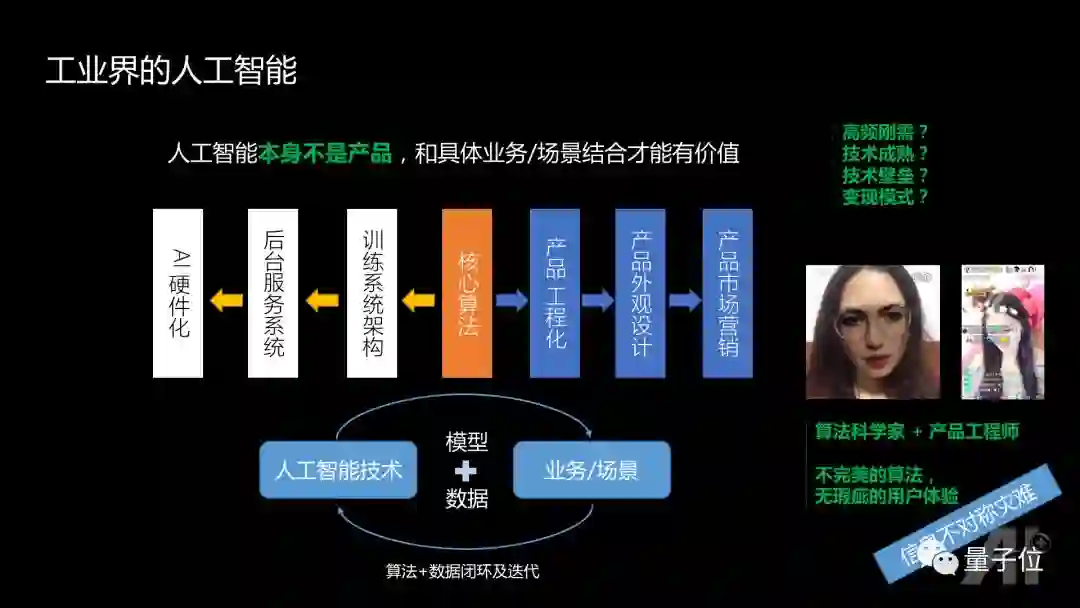
在工业界,大家清楚AI只是一种技术,并不是最终产品,这是从学术界进入到工业界会面临的一个很大的挑战。可能在学术界很成功,进入工业界的时候,会发现纯粹的技术能起到的价值,有百分之三十,或者百分之四十,就已经非常不错了。
要达到一个好的产品体验,有后端的因素,比如训练平台的架构,后台服务系统,如何保障几千万DAU运作的时候系统不会崩溃。未来在特定场景下,可能还希望AI硬件化;涉及到前端的算法工程化,产品的外观设计,产品的市场营销等,都是非常重要的。
AI的价值,必须跟具体的业务场景相融合,业务场景为人工智能提供有壁垒的数据,然后再训练出更好的模型,用到场景里继续产生新的更有价值的数据,不停地迭代才能发挥好的价值。
同时,作为算法科学家进入工业界,需要明白:没有完美的算法,需要产品等其他工程师一起把不完美的算法打造出没有瑕疵的用户体验。很多时候算法工程师和产品工程师无法做出完美产品的原因是信息不对称。
比如人脸的技术用于娱乐这个应用,更换人脸,技术是不完美的,一定会有抖动,不可能产生满意的用户体验;而如果不是换人脸,只是加一个花环,或者其他的装饰,即使技术不完美,但从用户体验来说,带来的这种愉悦感是没有问题的。这就是典型的算法+产品,尽管算法不完美,但用户体验不受影响。
另外工业界做一个基于AI的产品,需要考虑四个维度:
1、在学校时有一个想法,做一个demo,写一篇论文就行;但在工业界一定要能满足人的高频刚需,这个产品才可能是成功的产品。
2、技术要成熟。如果现在要追求像《her》那样的情感交流,技术不可能。
3、要有技术壁垒。现在这个时代很容易被竞争对手,或者大的公司,通过砸钱的方式直接毙掉了。无论是工程开发,还是后台的稳定性,以及投入的金钱,都是没法跟大公司PK的。
4、商业变现模式。在学校思考得非常少,但工业界一定要做思考。没有商业变现模式的公司迟早要遇到瓶颈和问题。
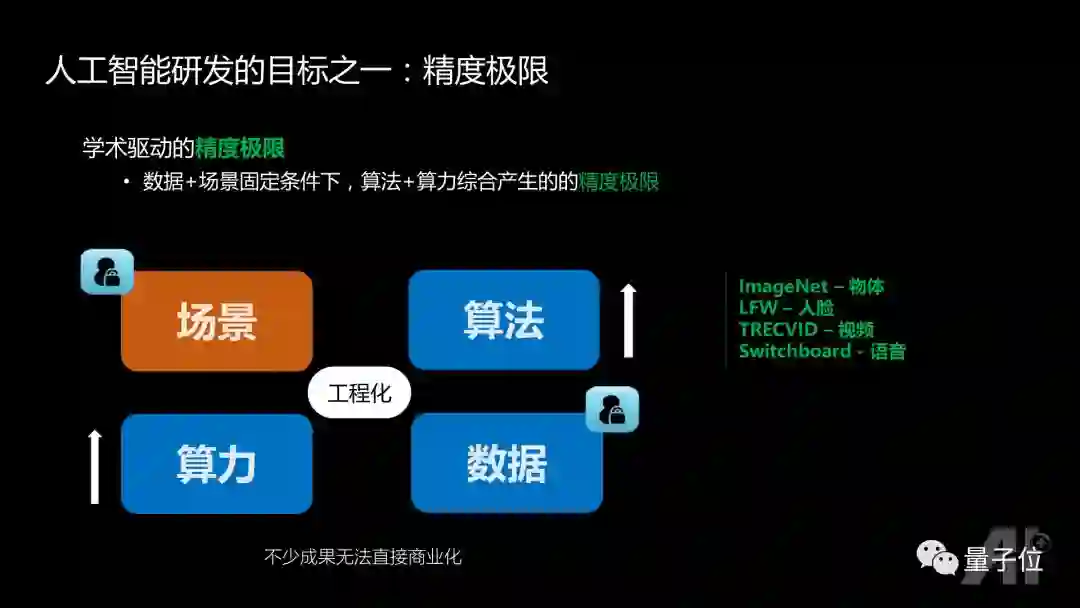
由上面的分析可以看到,人工智能研发的目标之一是学术界追求的精度极限,把场景和数据固定,在算力没有约束的情况下,通过算法改良达到精度极限。
根据四元分析,其场景和数据是固定,通过提升算力和算法来达到精度极限,比如大家经常参加的ImageNet竞赛,LFW-人脸的竞赛,TRECVID-视频的竞赛, Switchboard-语音竞赛,基本上都属于这个范畴。
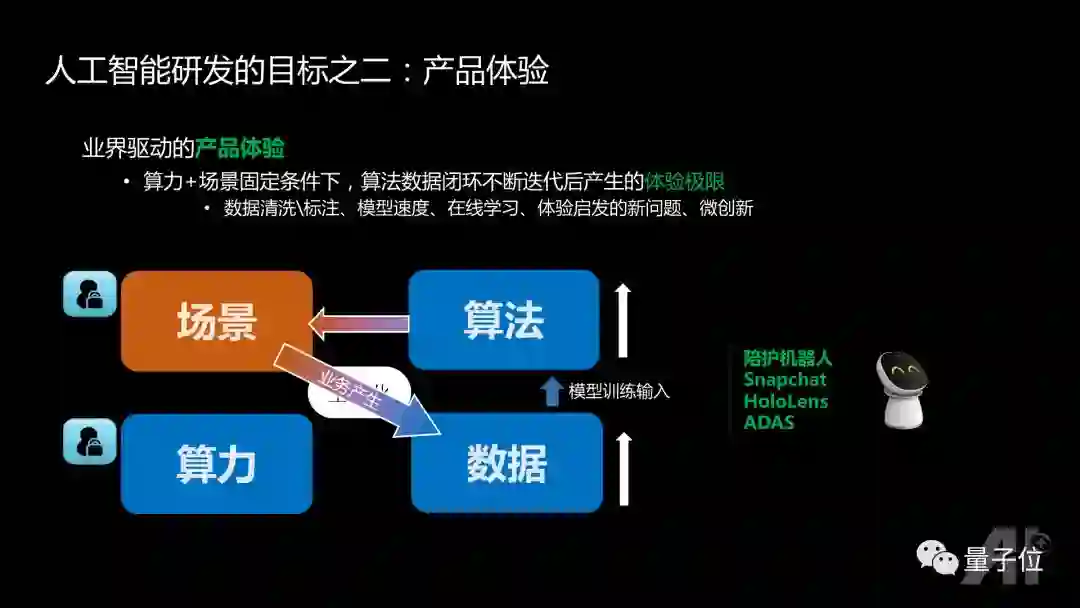
而由工业界驱动的产品体验极限追求,则把场景、算力固定。在这种情况下,不断提升在特定场景情况下的数据积累,并提升算法,最后数据、算法、场景形成闭环,不停的迭代,最终达到产品的用户体验极限。
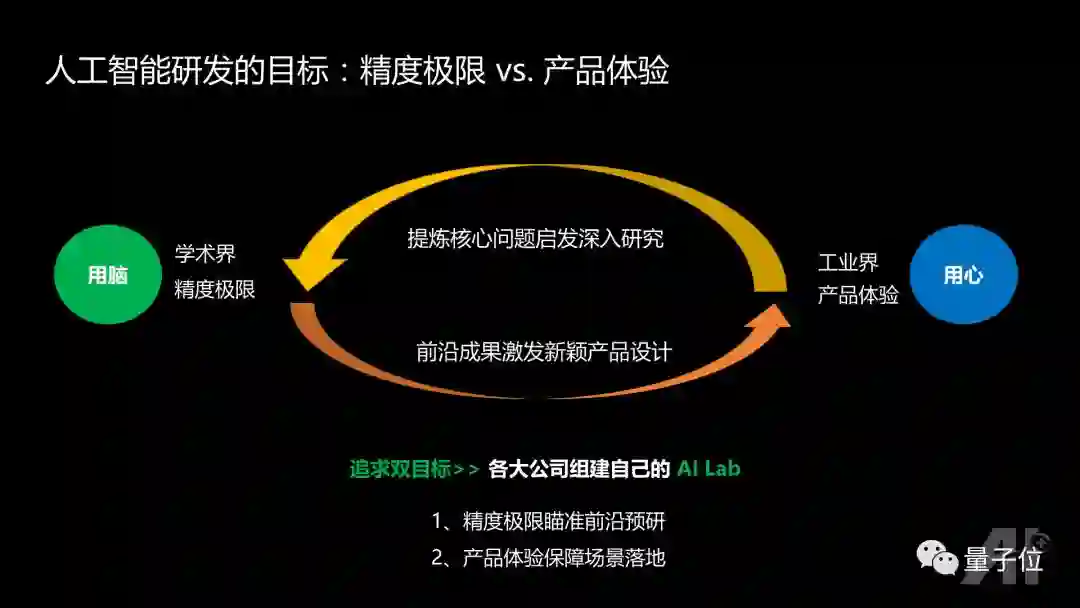
学术界和工业界各有侧重。学术界更看重算法极限,更多的是“用脑“,而工业界则更多考虑如何让用户有最佳的体验,更多的是”用心“。很多公司觉得这两个方向都非常重要,于是开始组建自己的AI Lab:精度极限瞄准前沿,瞄准可能是半年以后,或者一年以后公司的战略方向,而产品体验则保障在当前具体场景的技术落地。
深度学习模型发展
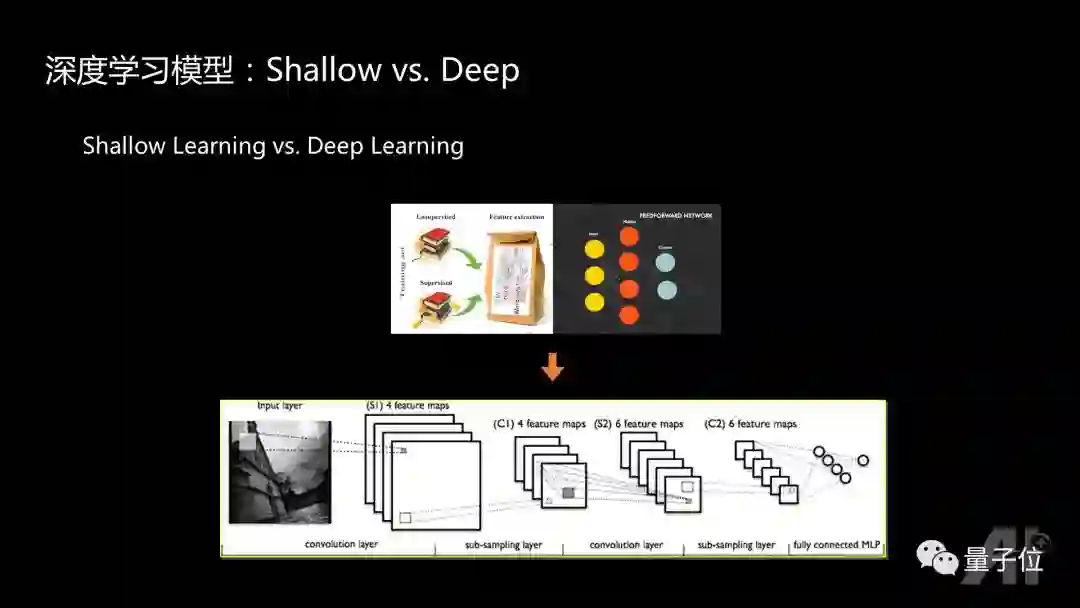
接下来跟大家回顾一下深度学习模型近年的发展历程,哪些方向是大家要注意的。
PASCAL VOC竞赛总共举行了八年,ImageNet竞赛也举行了八年,我带领的团队一共也参加了八年的竞赛。早期比赛的时候,使用的主要是shallow learning的模型,利用人工方法设计出新的feature,这些feature再输入到主要是SVM的分类器做训练。而深度学习则是将特征学习、分类器的学习融合到一个统一框架,基本从2012年开始就变成主要的参赛算法。
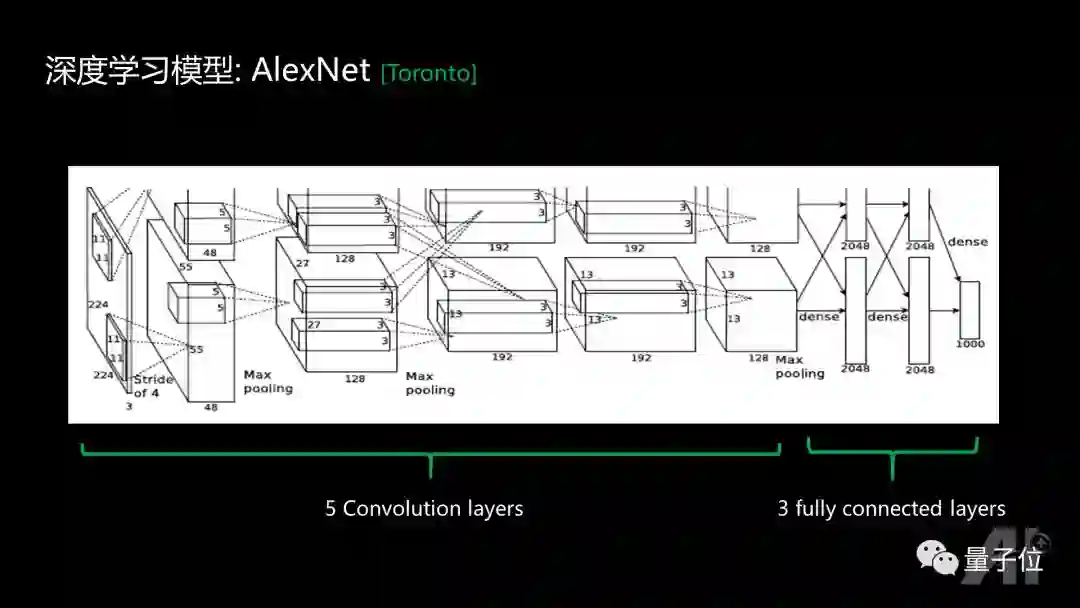
2012年提出的最早的AlexNet模型,是一个5+3的结构,前面五层是卷积层,后面三层是全连接层。当时效果非常好,但是这个模型实在太大了,现实生活中没办法到手机上去部署。
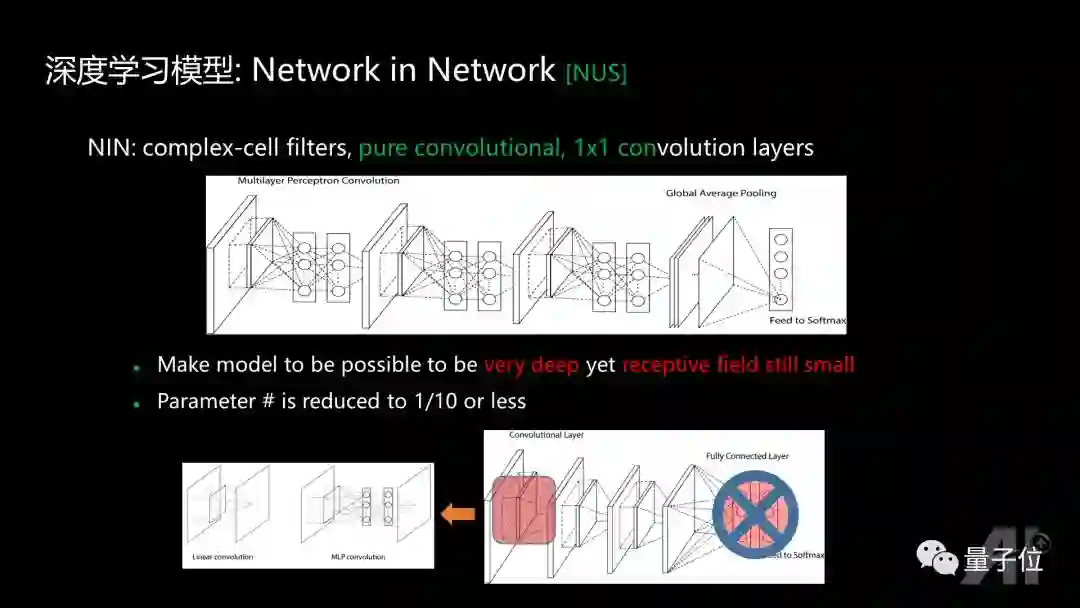
后续一个比较有价值的进展,是一个叫Lin Min的小伙子(我的PhD学生, 现在跟Bengio在做博士后)提出来的Network in Network。当初的想法是人的神经元具备非常复杂的结构,卷积外加非线性操作很难模拟它的功能,应该用一个更加复杂的结构来替代,这个结构可以是任意的网络结构;如果这个网络是一个多层感知机的话,那么这种网络就变成了在通常的3×3,5×5卷积的基础上,增加1×1卷积,从而提出一个1×1卷积的概念。
同时后面的全连接参数太多,容易overfitting,可以扔掉。既然前面有了比较复杂的子网络,后面则只要用Global average pooling,就可以得到我需要的feature。
1x1卷积对这个领域产生的价值是:可以让深度学习模型训练得非常非常的深。举一个最简单的例子,如果要训练一个一千层的网络,如果都用3X3的卷积,每往上一层,receptive field就会增加2;那么训练了1000层,第1000层的一点对应到原图至少是一个2000×2000的receptive field。而1x1卷积没有改变receptive field,所以他能保证最后一层的每个点,还有机会能够对应原图里面一个比较小的receptive field,这是1X1卷积起到的最主要的价值。
因为去掉了全连接层,网络的参数就变得非常少,由原来几百兆的模型,当时可以减少到几十兆,跟Alexnet还能有相当的性能。
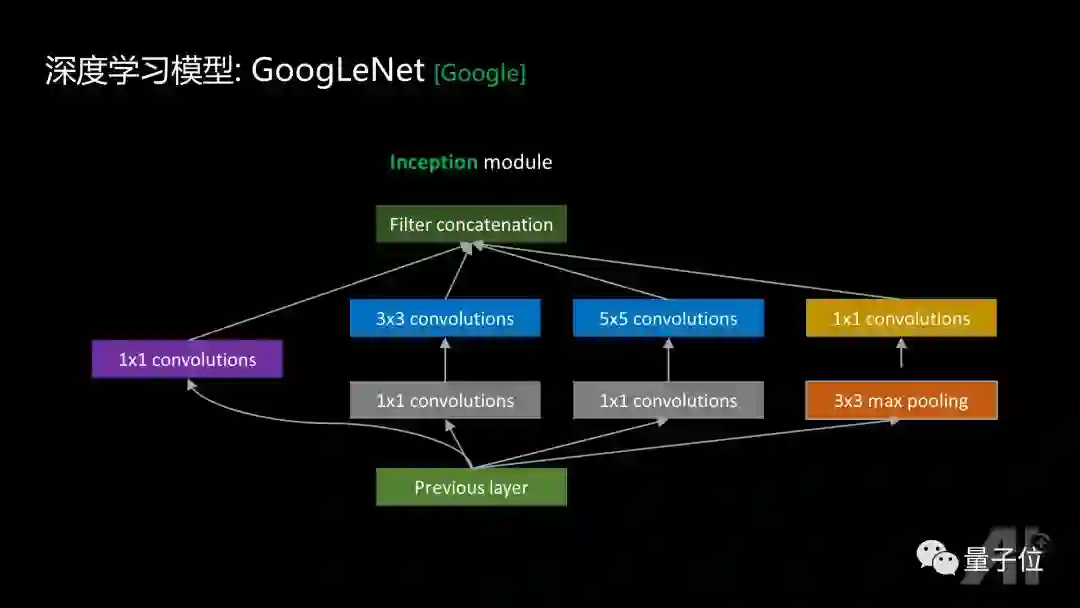
深度学习模型GoogleNet
GoogleNet借鉴了Network in Network的子网络和1x1卷积的思想,子网络设计得更加复杂并且非常合理,每个子网络拥有多通道,既有1×1的卷积,也有1×1,3×3的叠加,1×1,5×5叠加,或3×3 max pooling,1×1的叠加,可以实现多种尺度上的perception。 GoogleNet把自己的网络结构也叫做network in a network in a network。
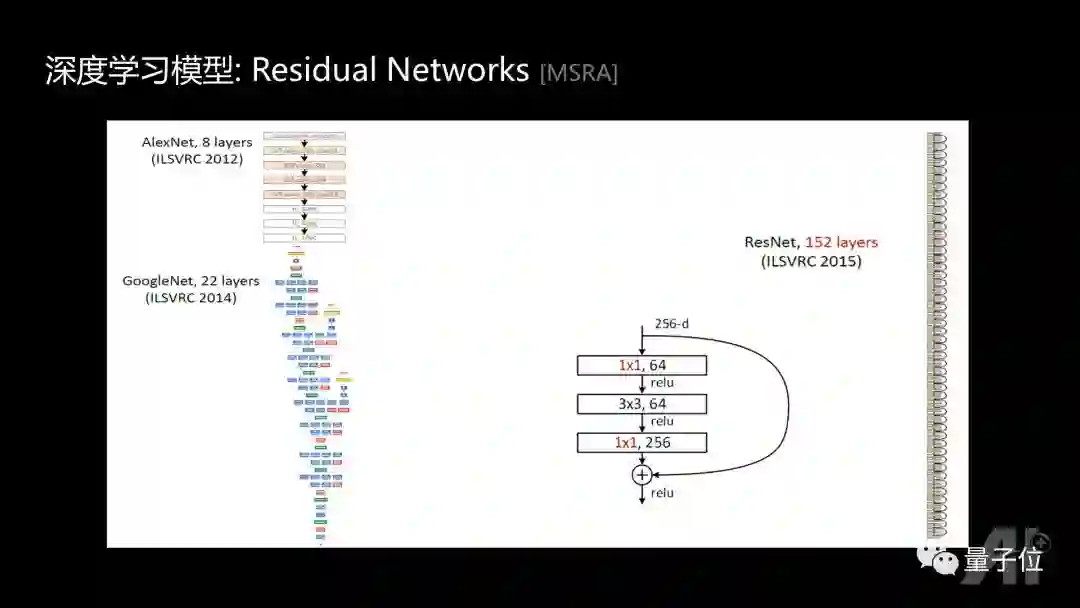
Residual Networks
大家知道Residual Networks起到了里程碑式的作用。可以看到1×1的卷积变成大部分后续新的网络结构 (Residual Networks, Densely Connected Neural Networks, Dual-path Networks, …) 中不可或缺的子模块。在Residual Networks中,1x1的卷积把256个channel变成64个,然后做3x3卷积,再用1x1的卷积升维到256,从而起到加速和减少参数的作用。

深度学习模型:GAN
最近两年,最让人exciting的进展应该是GAN,生成对抗网络模型。准确的说是一种模型学习方法,不是模型结构进展。
它的基本思想是要学习数据生成模型。利用生成模型来合成图像,同时学习一个判别模型,使其尽量区别生成模型合成的图像和真实的图像,最后完全不可分的时候,从理论上说生成图像分布和真实的图像分布则是一样的,这样就可以得到各种各样非常真实的生成图像。

Cycle-GAN
Cycle-GAN则是GAN令人exciting的进一步拓展。
它有两个域,目标把一个域的图像转换到另外一个域的图像,但是没有任何1-1对应的图像。一张图片从一个域变到另一个域,一方面满足生成图片的真实性,同时生成图像转换回原来的域,需要跟原来图像尽量相似。这种思想可以把任何一种自然图像变成梵高的风格,把真实图像和画的图像互换,把没有景深的图像变成有景深的图像等等。

STAR-GAN
STAR-GAN则在Cycle-GAN的基础上具备以下特点:
1、通过Adversarial Loss约束生成图像的真实性。
2、通过Domain Classification Loss约束生成图像的标签满足。
3、通过Cycle Reconstruction Loss约束生成图像与输入图像的相关性。
4、通过多库联合训练方式提升图像生成质量。
Star-GAN的结果是非常令人exciting的,给定任意一个头像,可以换发型,性别、年龄,加上粉底,甚至可以把原来的表情换成生气、开心、害怕等等,图像都非常真实。

深度学习应用
ImageNet竞赛是第一个海量图片数据库,开启了deep learning的时代,在其上精度的提升也是有目共睹的。这个比赛是深度学习研究的最大推动者。
在具体垂直领域,深度学习取得了非常好的效果。比如说人脸检测,最新的成果在FDDB数据库上是人脸总误检数为100的情况下,检测正确率达到了97.8%。最终检测不到的都是一些非常模糊的人脸或者是被遮挡的人脸。
人脸特征点定位,最新的成果在300-W数据库上是平均误差率只有4.38%。
另外图像“翻译”成自然语言也非常有前途,但是目前做的还不是非常好。5G的发展,实时的视频流会非常多,如果有算法可以由视频生成caption,做推荐和搜索都会更容易,但是现在的算法,还无法生成令人满意的个性化的caption。
此外还有语音、语义、大数据等应用。语音、语义部分前面大家已听过其他讲者的分享,今天就不介绍了。大数据这一块很有意思,大家都在想:深度学习会不会给大数据领域发生天翻地覆的变化。我们以及很多朋友的经验发现,早期的时候数据清洗的重要性远比模型要重要,当数据这个维度达到极致后,算法才能发挥大的价值,产生核心竞争力。
360的AI:研发与应用

360是一家以安全为使命的公司,其业务场景既有网络空间上的360安全保护,也有对应物理世界安全的产品包括儿童手表,摄像头,机器人,行车记录仪等。上述安全保护软件则帮助推动内容服务的产品,例如360搜索。
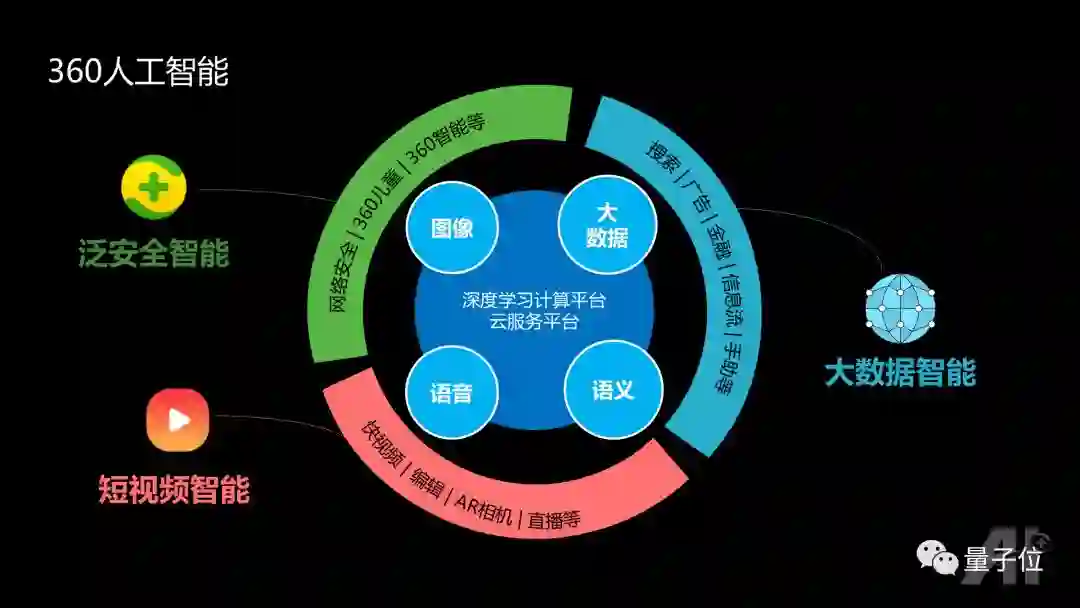
360人工智能有三大方向:泛安全智能,短视频智能,大数据智能。这些能力的保障包含两部分,一是深度学习计算平台,保证图像、语音、大数据分析能力的大规模GPU平台能快速训练;二是在线云服务的平台,可以在大用户访问量的情况下不崩溃。
人工智能:AI vs. 安全
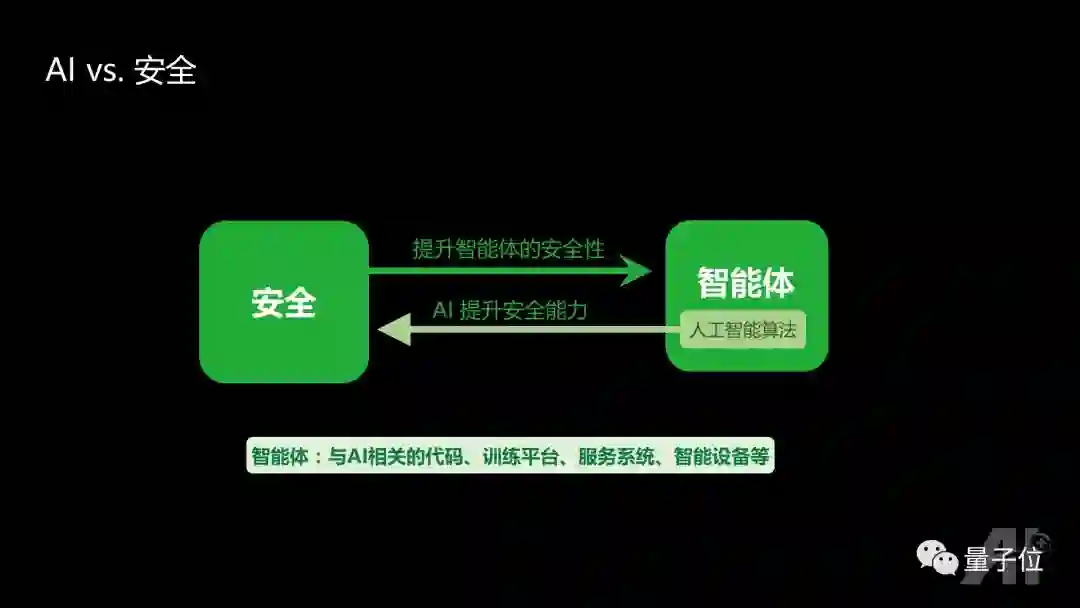
针对安全和智能的交叉,我们提出“智能体”的概念。智能体,泛指与AI相关的代码、训练平台、服务系统、智能设备等。
一方面,AI可以提高综合安全的能力,既包括网络空间的攻防能力,也包括物理世界人身安全的防护能力。
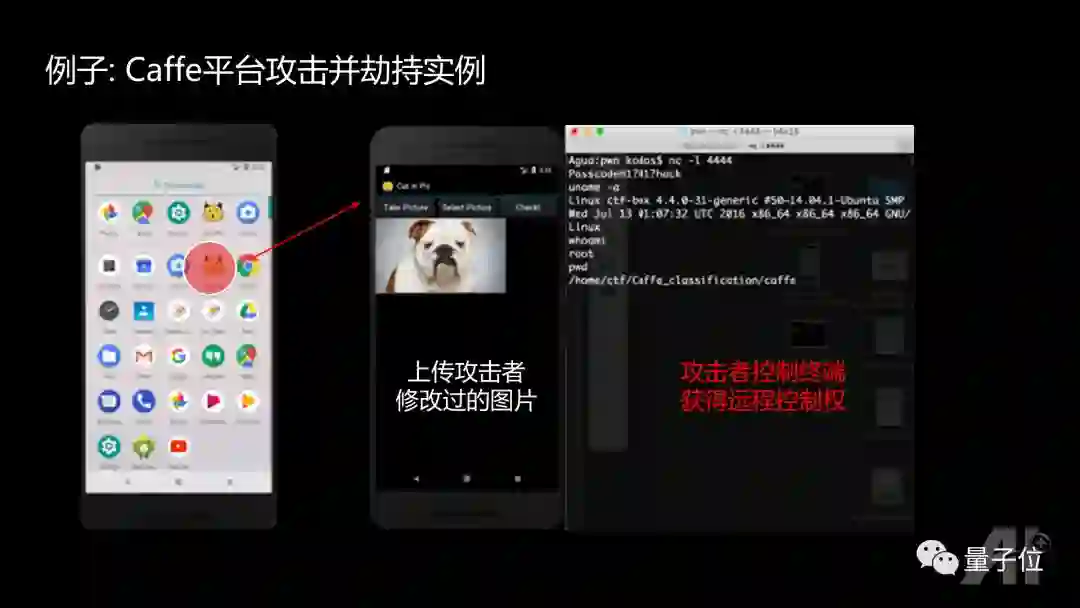
另一方面,安全的能力可以帮助检测智能体存在的安全隐患。比如AI传感器/数据安全,AI软件安全,智能硬件安全。比如摄像头存在失效或被误导的可能性,像Mobileye的摄像头在激光笔的光束下,很容易致盲;假的车道线也可能误导自动驾驶系统。
而Tensorflow、Caffe框架的依赖库中存在bug,一些研究者(360的李康教授团队)发现可以通过这些bug,攻击AI服务系统,达到劫持服务器的目的。智能硬件也容易被攻击,因为硬件往往需要联网,而一旦联网就会产生网络空间的攻击,带来物理世界的安全问题,比如特斯拉、比亚迪等汽车都有被黑客控制劫持的案例,这种安全问题已成为车联网产业发展的重大瓶颈。
人工智能:产业杂谈

由于时间限制,我们仅稍微讨论一个产业场景。
AI+区块链
今年区块链的火爆程度甚至高于AI,那么区块链和AI是否有合力的空间呢?
我们发现有3家公司在该领域有不错的进展,分别是Ocean,Cortex以及Raven PROTOCOL。Ocean是关于数据交易和共享的,走的是利用区块链进行数据共享和交换的商业模式。 Cortex是关于在线inference的,目标是将AI模型融入智能合约以产生更大型的商业场景。而Raven PROTOCAL则瞄准利用闲置资源进行分布式计算的商业模式。
最后抛出一个问题,如果没有ICO运转,我们如何找到高频刚需来很好地结合AI和区块链?
雷鸣对话颜水成
在AI+视频研究上,你认为未来几年会有一些巨大的突破吗?
现在做视频分析研究,一方面存在标注数据的限制,与图像数据库不同,视频数据具体应该标注什么有些时候也不清楚。另一方面,即便知道标注的内容,标注的代价也很大。
最近几年,基于图像特征、motion特征的双网络来做视频分析效果很不错,后面的进展不是很大,现在无法预言哪种技术最优,我们只能由最终的效果来判断哪个好。
要推动视频分析的发展,更重要的在于现在的产业公司,他们如果能够由国家统一起来建立起很大的数据库,那么所有人就可以在这个数据库基础上去攻克技术问题,然后就会自然而然地在技术路线上进行推动。
视频分析的核心当前还是归结于图像部分,在图像单帧分析的基础上,将图像时序融合表示成视频的特征。目前能想到的方案不是很多,个人觉得图像分析的基础模型还会是推动视频分析的关键点。
另一方面,图像分析目前的复杂度就很高,视频分析中,除了提高精度的模型研究要往前推进的同时,还要思考如何降低计算的复杂度。降低计算复杂度有助于我们迎接5G时代大规模高清直播视频爆发的到来。
你对于AR的未来发展的观点是什么?比如未来会以一种什么形态发展?还有就是你对AR和AI关系的看法?
AR眼镜的必然性:从PC到手机,用户可使用场景和时长提升了非常之多。而对于手机,其最大的瓶颈是必须用手拿着,要继续增加使用场景和提升使用时长,最好的方式就是将手机的功能转移到眼镜上,保证24小时所有场景均可在线。
商业方面,无干扰实时智能增强是AR眼镜最吸引人的地方,可以用在生活的方方面面,在各种场景上提供帮助与互动,弥补一些手机无法做到的辅助功能,例如记录曾遇到的人,实时见人识名。在AR眼镜上,很多以前信息与人交流的方式会变得不一样,类似从PC到手机的变化,这些变化将产生更多新的商业机会,诞生更多新的百亿美金公司。但当前,AR眼镜确实还存在有很多问题,比如光学系统,电池,内容生态等等,然后这些不影响AR眼镜一定会是未来。
AR眼镜具备和人几乎一样的视角,听觉位置,平常使用的语音识别,TTS,语义理解,实时在端上的基于视觉的理解,都是对AR眼镜至关重要的能力。视觉分成两个维度,一个维度是物理感知,感知深度信息,包括3D重建,SLAM等。另一个维度是语义感知,具体知道是什么东西。AR眼镜需要物理感知和语义感知相融合,才能提供高质量的服务。
你从科研界到产业界的转变过程中有没有遇到一些挑战和困难,包括你在科研上定目标和管理,当在业界之后科研和研发团队的不同点?
工业界的AI研究,更多时间需要思考AI怎么在场景中能更有效率,从研发的角度需要从精度往速度上偏移。
从学术界到工业界,开始不要想着能解决所有问题,先从公司的一个重要场景出发,把算法和数据相互融合,开始不要一味追求模型精度的提升,因为开始的时候数据分析带来的价值更大。算法的攻坚更适合在商业逻辑完善,数据流程清晰之后。
下期预告
本周三放假,大家好好休息~ 5月9日(下周三)继续学习~
感兴趣的小伙伴可以添加量子位小助手6:qbitbot6,备注“北大”,通过后可进入课程活动群,获取每期课程信息,与其他小伙伴互动交流。
祝大家听课愉快~
学习资料
在量子位微信公众号(QbitAI)界面回复:“北大AI公开课”,可获取本次讲座的视频回放,以及前八讲的相关学习资料~
— 完 —
加入社群
量子位AI社群16群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot6入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot6,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




