快速准确的人脸检测&识别新框架(进阶)(文末附源码)

人脸技术
上一期“计算机视觉战队”已经和大家分享了相关的人脸检测、识别和验证背景及现状的发展状况,今天我们继续说说人脸领域的一些相关技术以及新框架的人脸检测识别系统。


多任务学习的人脸分析
多任务学习是一个问题的多个部分同时处理的设置,通常使用相同的特性。MTL(Multi-Task Learning)背后的理念是,不同的任务可以相互受益。第一次使用MTL框架,并由Caruana[R. Caruana, “Multitask learning,” in Learning to learn. Springer, 1998, pp. 95–133]进行分析。朱等人[X. Zhu and D. Ramanan, “Face detection, pose estimation, and landmark localization in the wild,” in IEEE Conference on Computer Vision and Pattern Recognition, June 2012, pp. 2879–2886]提出了一种同时进行人脸检测、关键点定位和头部姿势估计的多任务方法。MTL通过利用来自不同监督来源的信息来提高所涉及的任务的性能。例如,JointCascade[D. Chen, S. Ren, Y. Wei, X. Cao, and J. Sun, “Joint cascade face detection and alignment,” in European Conference on Computer Vision, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds., 2014, vol. 8694, pp. 109–122]通过在训练期间在人脸检测中添加关键点定位来提高人脸检测性能。
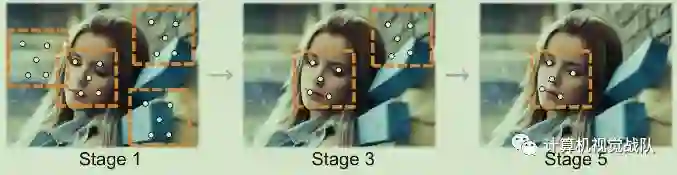
但是,由于上述方法使用了人工制作的特征,所以将这些方法扩展到新任务是困难的。不同的任务需要不同类型的专门人工制作特征。例如,人脸检测通常使用直方图面向定向的梯度(HOG),而人脸识别通常使用局部二进制模式(LBP)。结合这些实现人脸检测和识别是困难的。然而,从DCNNs获得的特征可以编码各种性质,可视的数据。与手工设计的特征相反,有可能为能够完成多个任务的单个DCNN进行训练作为人脸检测、关键点定位、属性预测、年龄估计、人脸识别等。共享深度特征有助于挖掘不同任务之间的关系。使用MTL可以被认为是一个额外的正则化用于CNN。
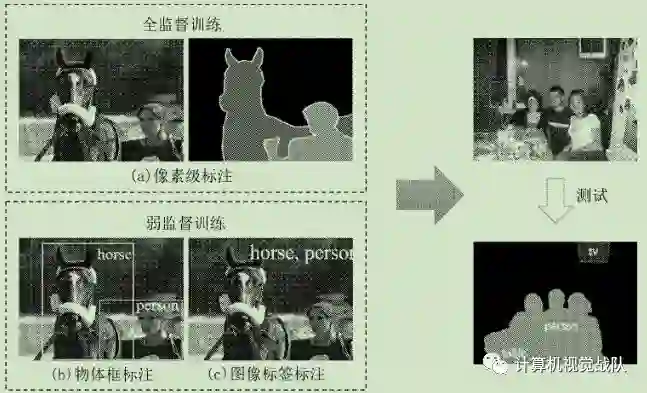
HyperFace[R. Ranjan, V. Patel, and R. Chellappa, “Hyperface: A deep multitask learning framework for face detection, landmark localization, pose estimation, and gender recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017]是第一个多任务方法之一的人脸分析。设计用于同时人脸检测、关键点定位、头部姿态估计和性别分类。它通过从CNN和语义的下层共享位置,来自较高层的丰富特征利用各种任务之间的协同作用生成特定的特征,这有助于改善每个任务性能。同样,TCDCN[Z. Zhang, P. Luo, C. Loy, and X. Tang, “Facial landmark detection by deep multi-task learning,” in European Conference on Computer Vision, 2014, pp. 94–108]增加了头部偏向估计、性别识别、微笑和眼镜检测到关键点定位的任务。这些辅助任务得到了改进关键点定位的表现。All-in-One Face通过添加更多任务和训练来扩展网络扩展人脸数据。
新人脸检测&识别框架
先进的人脸验证和识别
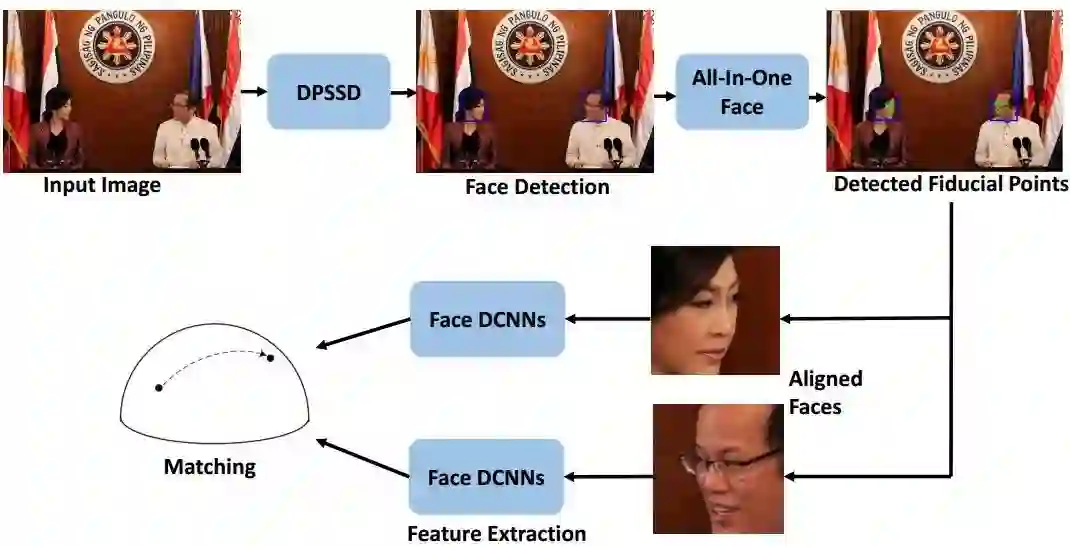
下图给出了新框架流水线的概述。接下来我们首先介绍了提出的DPSSD人脸检测器。然后,简要总结了人脸对齐方法使用单独MTL方法。最后描述了提取身份特征并将其用于人脸识别和验证的方法。
Deep Pyramid Single Shot Face Detector
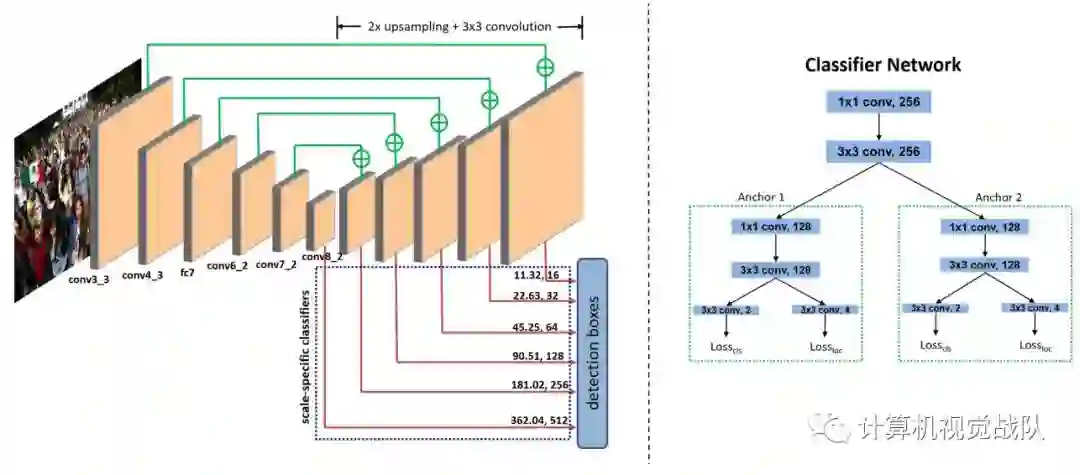
新框架提出了一种新的基于DCNN的人脸检测器,称为深度金字塔单镜头人脸检测器(DPSSD),速度快,能够检测各种尺度上的人脸。它是特别擅长检测微小的人脸。因为人脸检测是一个目标检测的特殊情况,许多研究人员都有使用现成的目标检测器,并对其进行微调进行人脸检测[H. Jiang and E. Learned-Miller, “Face detection with the faster r-cnn,” arXiv preprint arXiv:1606.03473, 2016]。然而,为了设计有效的人脸检测器,必须解决人脸和目标检测任务之间的以下差异。
首先,人脸相比于在图像中的更低的比例/尺寸,一般的目标。典型地,目标检测器不被设计为以这样的低分辨率来检测任务所需的低分辨率人脸检测。第二,人脸的纵横比的变化是与在典型物体中的物体相比要少得多。与目标相比,面临的风险较小,结构变形不需要任何包含在目标检测算法中的附加处理以处理多个纵横比。新框架设计的人脸检测器解决这些问题。
Face Alignment using All-In-One Face
候选的人脸识别和验证系统使用的系统用于关键点定位。All-in-OneFaces是一个最近的方法,该方法同时执行人脸检测、关键点定位、头部姿势估计、微笑和性别分类、年龄估计的任务人脸识别和验证。该模型是联合训练的在MTL框架中,为所有这些任务建立起协同作用,这有助于提高各个任务的性能。
由于缺少包含注释的单个数据集对于每个任务,通过不同的子网络来训练不同的子网络。这些子网在它们之间共享参数,这确保共享参数适用于所有任务。这些子网络被融合到单个中。
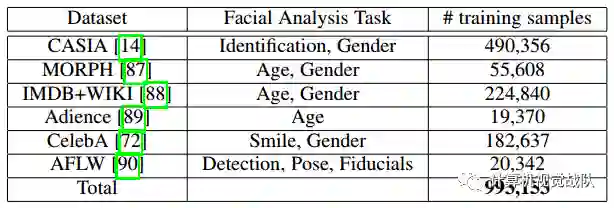
上表给出了一些细节,用于训练All-in-One Face CNN的数据集。完成使用任务特定的损失对网络进行端到端训练。下图显示了All-in-One Face的一些代表性输出CNN。

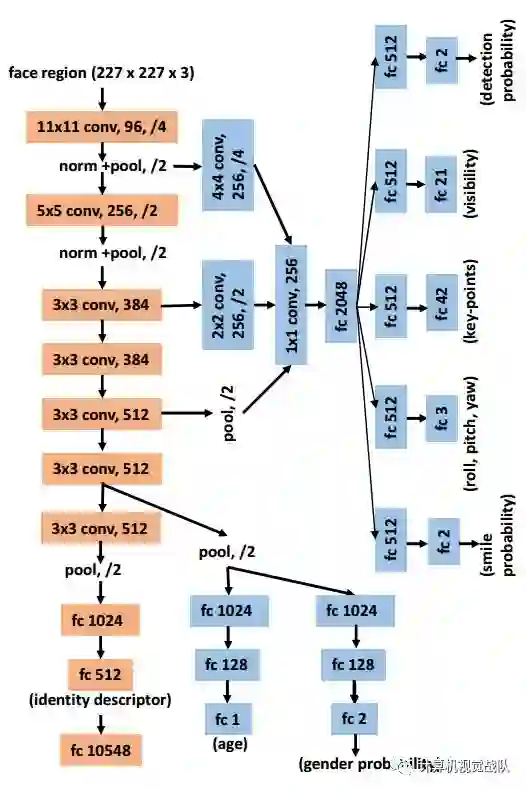
All-in-One Face网络架构使用预训练验证网络Sankararanayanan[25],包含七个卷积层,之后是三个全连接层。该网络被用作人脸部进行训练的主干识别任务。来自前6个卷积的参数此网络的层在其他面相关中共享任务如下图所示。针对人脸识别任务的CNN预训练提供了对通用人脸分析任务的更好的初始化,因为过滤器保留了区别人脸信息。
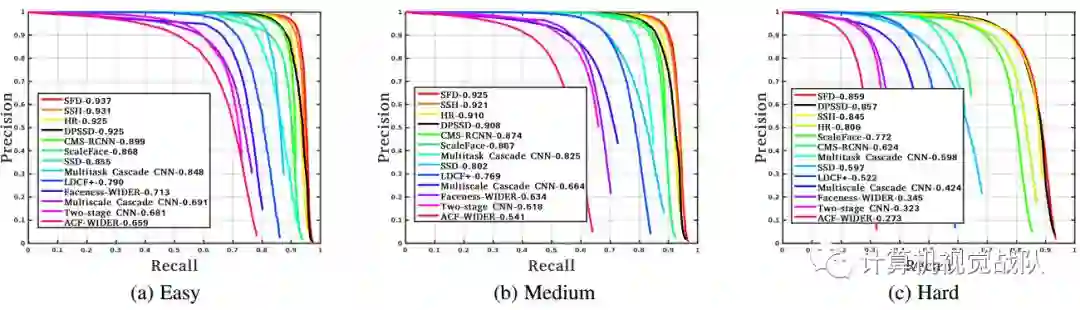
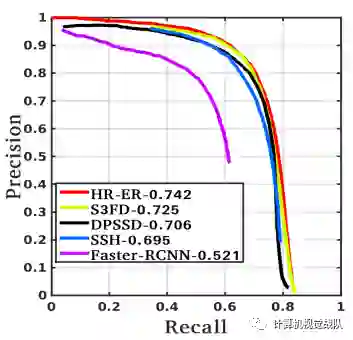
人脸检测、识别和验证实验
实验结果
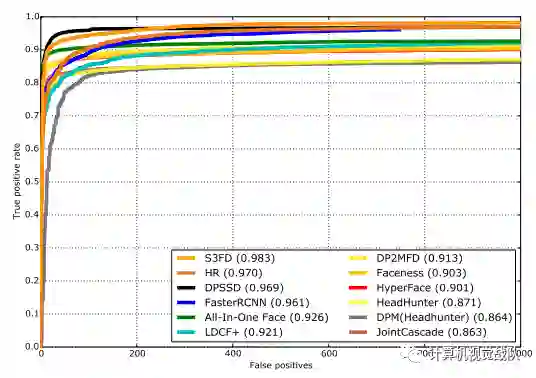
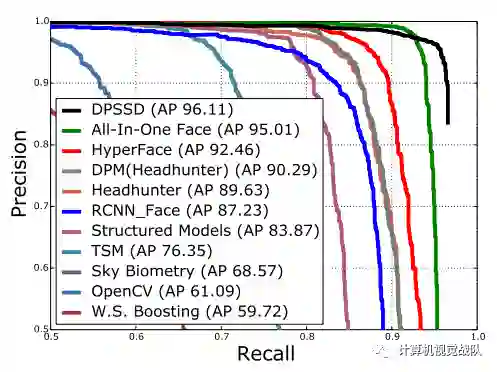
END
源码:http://ankan.umiacs.io/projects.html
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。


