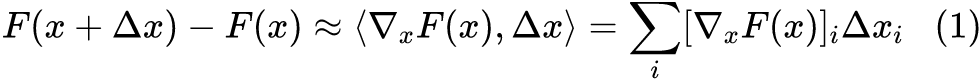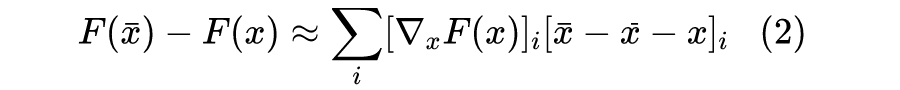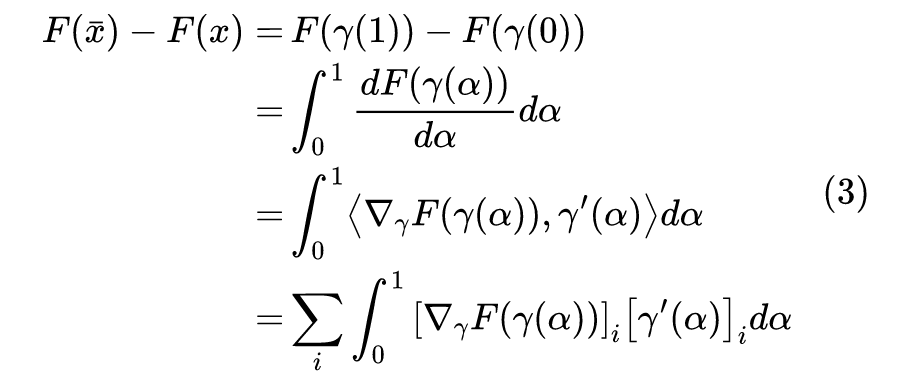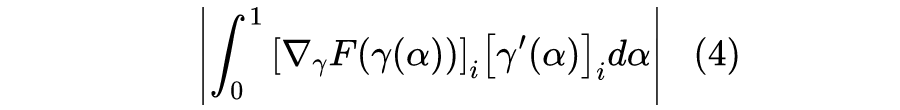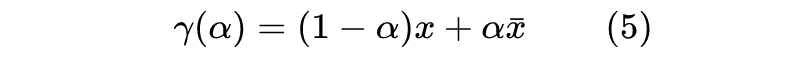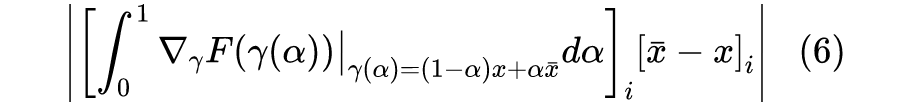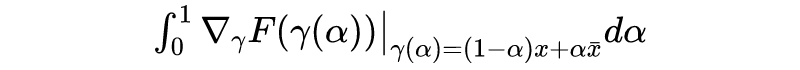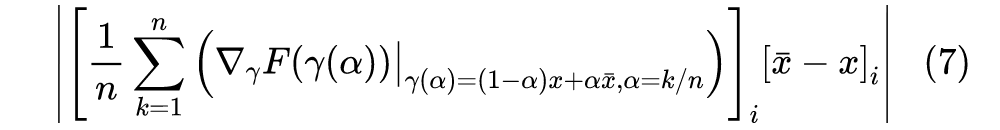本文介绍一种神经网络的可视化方法:积分梯度(Integrated Gradients),它首先在论文 Gradients of Counterfactuals [1] 中提出,后来 Axiomatic Attribution for Deep Networks[2] 再次介绍了它,两篇论文作者都是一样的,内容也大体上相同,后一篇相对来说更易懂一些,如果要读原论文的话,建议大家优先读后一篇。
所谓可视化,简单来说就是对于给定的输入 x 以及模型 F(x),我们想办法指出 x 的哪些分量对模型的决策有重要影响,或者说对 x 各个分量的重要性做个排序,用专业的话术来说那就是“归因”。一个朴素的思路是直接使用梯度 来作为 x 各个分量的重要性指标,而积分梯度是对它的改进。然而,笔者认为,很多介绍积分梯度方法的文章(包括原论文),都过于“生硬”(形式化),没有很好地突出积分梯度能比朴素梯度更有效的本质原因。本文试图用自己的思路介绍一下积分梯度方法。
朴素梯度首先,我们来学习一下基于梯度的方法,其实它就是基于泰勒展开:
我们知道 是大小跟 x 一样的向量,这里 为它的第 i 个分量,那么对于同样大小的 的绝对值越大,那么 相对于 的变化就越大,也就是说: 衡量了模型对输入的第 i 个分量的敏感程度,所以我们用 作为第 i 个分量的重要性指标。这种思路比较简单直接,在论文 How to Explain Individual Classification Decisions[3] 和 Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps[4] 都有描述,在很多时候它确实也可以成功解释一些预测结果,但它也有明显的缺点。很多文章提到了饱和区的情况,也就是一旦进入到了饱和区(典型的就是 的负半轴),梯度就为 0 了,那就揭示不出什么有效信息了。从实践角度看,这种理解是合理的,但是笔者认为还不够深刻。从之前的文章对抗训练浅谈:意义、方法和思考(附 Keras 实现)可以看出,对抗训练的目标可以理解为就是在推动着 ,这也就可以理解为,梯度是可以被“操控”的,哪怕不影响模型的预测准确率的情况下,我们都可以让梯度尽可能接近于0。所以,回到本文的主题,那就是: 确实衡量了模型对输入的第 i 个分量的敏感程度,但敏感程度不足以作为重要性的良好度量。
积分梯度鉴于直接使用梯度的上述缺点,一些新的改进相继被提出来,如 LRP [5]、DeepLift [6] 等,不过相对而言,笔者还是觉得积分梯度的改进更为简洁漂亮。2.1 参照背景首先,我们需要换个角度来理解原始问题:我们的目的是找出比较重要的分量,但是这个重要性不应该是绝对的,而应该是相对的。比如,我们要找出近来比较热门的流行词,我们就不能单根据词频来找,不然找出来肯定是“的”、“了”之类的停用词,我们应当准备一个平衡语料统计出来的“参照”词频表,然后对比词频差异而不是绝对值。这就告诉我们,为了衡量 x 各个分量的重要性,我们也需要有一个“参照背景” 。当然,很多场景下我们可以简单地让 ,但这未必是最优的,比如我们还可以选择 为所有训练样本的均值。我们期望 应当给一个比较平凡的预测结果,比如分类模型的话, 的预测结果应该是每个类的概率都很均衡。于是我们去考虑 ,我们可以想象为这是从 x 移动到 的成本。如果还是用近似展开(1),那么我们将得到:
对于上式,我们就可以有一种新的理解:
从 x 移动到 的总成本为 ,它是每个分量的成本之和,而每个分量的成本近似为 ,所以我们可以用 作为第i个分量的重要性指标。当然,不管是 还是 ,它们的缺陷在数学上都是一样的(梯度消失),但是对应的解释却并不一样。前面说了, 的缺陷源于“敏感程度不足以作为重要性的良好度量”,而纵观这一小节的推理过程, 的缺陷则只是因为“等式(2)仅仅是近似成立的”,但整个逻辑推理是没毛病的。2.2 积分恒等很多时候一种新的解释能带给我们新的视角,继而启发我们做出新的改进。比如前面对缺陷的分析,说白了就是说“ 不够好是因为式(2)不够精确”,那如果我们直接能找到一个精确相等的类似表达式,那么就可以解决这个问题了。积分梯度正是找到了这样的一个表达式:设 代表连接 x 和 的一条参数曲线,其中 ,那么我们有: