![]()
在这里,小八不会正儿八经地讨论AI,只会不负责任地胡说八道,聊聊最近AI领域的值得注意的趋势和趣事。
同学们也可以在这里轻松一下,充充电,攒攒要看的paper。
所以请各位小伙伴们好好欣赏,且看且吐槽,且转且珍惜(懂的都懂)。
美术考试
小银摸了一整个学期的鱼,根本没有做过任何练习。但是他很自信地跟同学说,考试及格完全没问题,满分都有希望。然后,他趴在桌子上,开始打呼噜。
我拿着他的作品,说道:“很厉害啊,你和小乐都画的好像。”
小银诧异,对我说:“小八,小乐的作品拿给我看看。”
我拿来小乐的作品对小银说道:“你看,你和小乐都很会画胡子哈!”
后来,我才知道,他们都用了同一款AI应用——ArtLine,来自动生成速写画。我还是,太天真了。
我也向他们要到了GitHub地址,看看我的试用效果吧:
ArtLine地址:https://github.com/vijishmadhavan/ArtLine
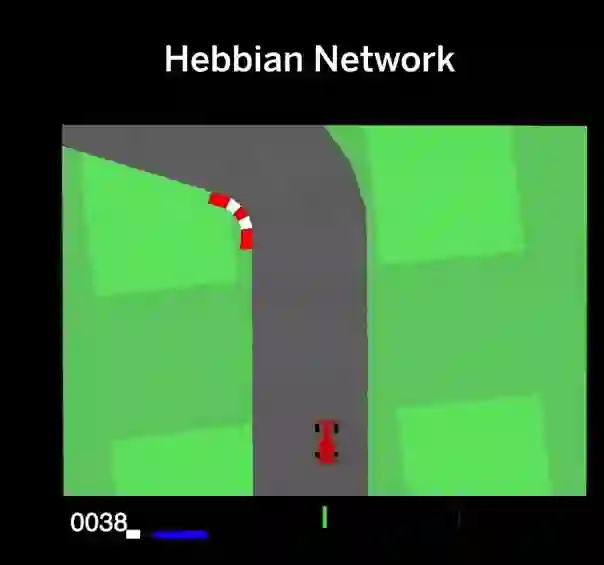
让机器人重新“振作”的秘密
瞧上面的两个机器人,是不是差别很大?这两个机器人的“大脑”都已经进化了300多代,相当于人类经历了7500年的历史。
现在,如果让它们迈开腿走,只有一个能成功,另一个则四脚朝天。
什么原因呢?这是一篇发表在NeurIPS 2020上的论文的研究发现,近期Science也写了相关的评论文章。
纽约客、Science等知名期刊的专栏作家Matthew Hutson在评论中写道:只有左侧的机器人才学会了适应新环境,所以它学会了用坏掉的脚行走。
没错,左侧的机器人用的是坏掉的脚。而它并没有在训练中用坏掉的脚来学习走路,而是在脚坏掉后完全靠自己重新学会了走路。
通常,神经网络一旦经过训练和部署,就不会再学习新事物。这个机器人用了什么魔法呢?
原来,研究人员使用了“ Hebbian规则”来训练机器人的网络。
在测试中,研究人员截断了两个机器人的左前腿,看它们怎么反应。最终,他们惊讶地发现:两个机器人起初都在挣扎,但Hebbian机器人最终行走了将近七倍的距离。
在另一项测试中,Hebbian网络驾驶的赛车在视频游戏上的表现,比非Hebbian网络赛车好约20%。
“Hebbian规则”源于加拿大著名生理心理学家Donald Hebb在1949年提出的赫布理论,简单来说就是:同时激发的神经元之间的突触连接会增强。该理论作为突触可塑性的基本原理,可以解释条件反射等现象,也成为了无监督学习的生物学基础。
论文地址:https://papers.nips.cc/paper/2020/file/ee23e7ad9b473ad072d57aaa9b2a5222-Paper.pdf
第一性原理助力深度学习飞跃?
Yoshua Bengio近期发表了新作,就是他与学生合作的论文“Inductive Biases for Deep Learning of Higher-Level Cognition”,哲学意味很浓,富有启发哦。
论文围绕“归纳偏置”概念,展开了对当下人工智能研究现状的讨论,并提出:不同的深度学习架构基于不同的归纳偏置,探索更大范畴的归纳偏置,是实现人工智能研究进步的关键。
啥意思?举例来说呢,就是:循环网络基于时间等变性的归纳偏置推导而出,软注意力基于排列等变性的归纳偏置推导而出。
Bengio把我们目前挖掘出来的归纳偏置称为低级认知的归纳偏置,这是否意味着:如果能挖掘出高级认知的归纳偏置,就相当于可以通过第一性原理发现高级认知功能需要的架构。结合过去已有的架构,实现通用人工智能指日可待...
以上只是胡言乱语,但小八确实带着这份期待,你呢,心动了吗?
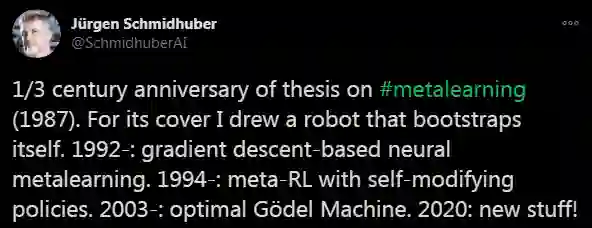
Jürgen Schmidhuber的本科毕业论文,是元学习啊~
最近,Jürgen Schmidhuber在推特上分享了个事情,说是元学习被提出1/3世纪纪念。也就是说,元学习是在1987年被提出的。
小八仔细去看了看,发现Schmidhuber说的这个标志性事件,指的是他在1987年发表的关于元学习的本科毕业论文。Schmidhuber表示这篇论文是“有关该主题的一系列研究中的第一篇论文。”
论文:Evolutionary Principles in Self—Referential Learning
论文地址:http://people.idsia.ch/~juergen/diploma1987ocr.pdf
对于这个问题,小八暂且放下不表。但是,有论文可以刷呀!
这篇论文讲了啥呢?简单来说呢,就是1987年Schmidhuber的团队发表了一篇论文“用于无限长代码的遗传编程”(Genetic Programming for code of unlimited size),Schmidhuber表示“这是第一篇以通用编程语言编写的无线长度进化程序的遗传编程。”
然后,他的本科毕业论文中,他将遗传编程用于自身,从而以递归方式开发更好的遗传编程方法。
好家伙,还有这种操作。元学习我们一般理解是在“数据-学习模型”(一个数据对应模型的一次推理)之上再构建一个层级,也就是“数据集-元学习模型”(一个数据集对应模型的一次推理,一次推理产生一个学习模型)。
Schmidhuber相当于用模型自身来构建更高的层级,有点像鸡生蛋蛋生鸡,而且鸡就是蛋,蛋就是鸡,鸡生的蛋再生的鸡不是鸡的孙子,而是鸡自己,但是这时的鸡已经不同于原来的鸡...别晕,也没啥,就是...f(f(f))...=f(不严谨,不负责)。
Schmidhuber还画了一张图来解释这种思想。哈,这明显违反物理定律嘛,但是在元学习的世界里,这就是存在的。
此外,Schmidhuber也写了一篇博客来介绍他们团队的研究历史,也就是自1990年以来的元学习相关工作,来看看都有啥:
通过自我修改策略进行元强化学习(1994);
在人工神经网络中基于梯度下降的元学习(1992);
用于课程学习的渐近最佳元学习(2002);
通过自参考哥德尔机的数学上最佳的元学习(2003);
Meta-RL与人工好奇心、内部驱动力相结合(1990/1997);
2020年的工作。
博客地址:http://people.idsia.ch/~juergen/metalearning.html
不止是MuZero
DeepMind 最近又发Nature了,他们开发出了AlphaZero的进化版本,不仅能玩围棋、国际象棋和日本将棋,还能玩Atari游戏。
一些读者可能会想,不就是增加了一款游戏嘛,这跟我学会玩《只狼》后再去玩《赛博朋克2077》有啥区别呢?
当然不一样,按照FAIR研究科学家Noam Brown的评价,MuZero学会了对复杂世界的准确建模。
Atari的游戏环境,相比围棋、国际象棋、日本将棋而言,其规则与动态变化未知且复杂。就是说,这三种棋类游戏都有明确的、用很少描述就能总结的规则,游戏动态就是不同离散方格的组合。但是Atari的规则描述起来就长得多,游戏动态几乎就是连续的。
如果要硬比较的话,那应该就是相当于玩《只狼》跟做现实中的只狼的区别(有夸张,不负责),别指望靠抖刀就能所向无敌。
然后,小八又注意到了这篇论文“MASTERING ATARI WITH DISCRETE WORLD MODELS”,由谷歌大脑和DeepMind合作完成,也是基于对复杂世界建模而实现了更高性能的Atari。相比于MuZero而言,这篇论文就显得低调许多。
他们开发了名为DreamerV2的强化学习智能体,可以纯粹从世界模型的紧凑型潜在空间中的预测中学习行为。世界模型使用离散表示,并且与策略分开进行训练。
据研究人员表示,DreamerV2首次通过学习在单独训练的世界模型中的行为,而在Atari基准测试55个任务上达到人类级性能。
DreamerV2与MuZero结合食用,估计更香。
论文:MASTERING ATARI WITH DISCRETE WORLD MODELS
论文地址:https://arxiv.org/pdf/2010.02193v2.pdf
![]()
点击阅读原文,直达AAAI小组!
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。