独家 | CIKM AnalytiCup 2017冠军团队获胜经验分享(附PPT&视频)

清华大数据“赛事经验分享”系列讲座是清华-青岛数据科学研究院继“应用•创新”和“技术•前沿”系列后推出的又一学术品牌,旨在分享国内外大数据领域重要赛事获胜团队及个人的参赛历程及其获胜经验。本期我们邀请到CIKM AnalytiCup2017凭借“基于雷达图像预测未来降水”模型,以绝对优势排名第一的清华大学Marmot团队(姚易辰,李中杰),团队成员李中杰从赛题介绍、数据描述、赛题思考、解决方案等方面与听众进行了详实的分享和解读。
后台回复关键词“1129”,下载完整版PPT。
讲座视频:
(建议在wifi条件下观看)
以下是文字版实录:

清华大学热能系博士生李中杰
团队介绍
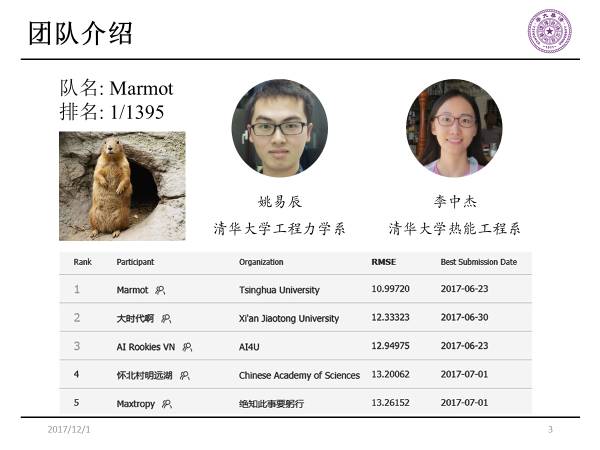
李中杰:我们的团队队名叫Marmot,中文是土拔鼠的意思,寓意是希望能够像土拔鼠一样擅长挖掘,挖掘数据的价值和意义。在这次比赛当中,我们的模型最终的误差是10.9972,以较大的优势在1395支队伍当中位列第一。
1. 赛事介绍

此次竞赛以“基于雷达图像的短期降水预报”为题。

雷达图像是通过气象多普勒雷达采集,左图是多普勒雷达,雷达采集的区域在深圳。

一般来说,反射率越大(图中越红的区域),云团的含水量就越大,这样就越有可能带来降水。
除了反射率因子,降水量还跟云团的整体空间结构、云团在时间方向上的运动规律有关。
2. 数据描述
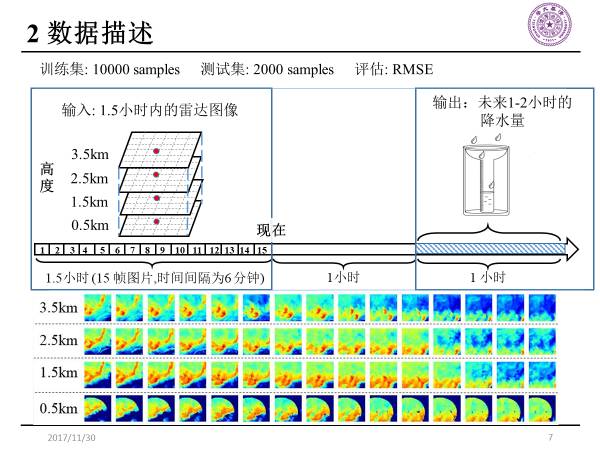
因为预测降水量属于回归问题,所以评估指标是RMSE(均方根误差)。
输入1.5小时内的雷达图像(60张),分布在4个不同的高度,每个高度15张,按时间方向排布,每两张雷达图像的时间间隔为6分钟,然后利用这60张图像预测未来1-2小时的降水量。
预测的地点是红色的点(目标站点)。从图中可以看到在最低层的高度,每个雷达图像都有一个明显的圆形,非常深颜色的蓝色,它并不是因为没有反射率,而是因为雷达覆盖范围不全,所以在模拟训练的时候,我们并没有使用最低层高度上的雷达图像。
3. 赛事思考
回顾图像类问题处理方法
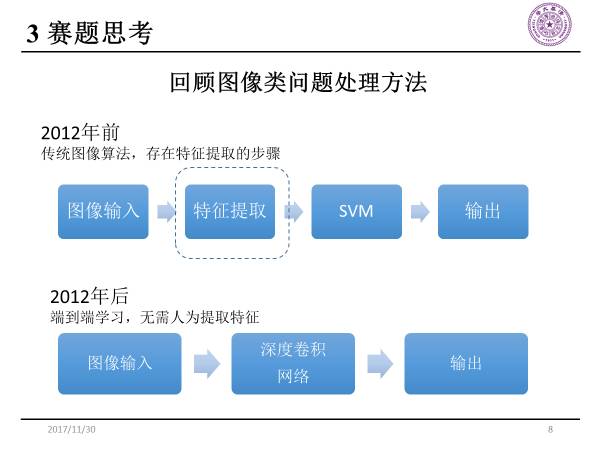
在2012年之前,图像类问题处理方法一般是传统图像算法。图像通过特征提取,再运用到一些经典的机器学习模型,然后再输出结果。
在2012年之后,端到端学习模型无需人为提取特征,图像输入到深度卷积神经网络中,就直接得到输出。
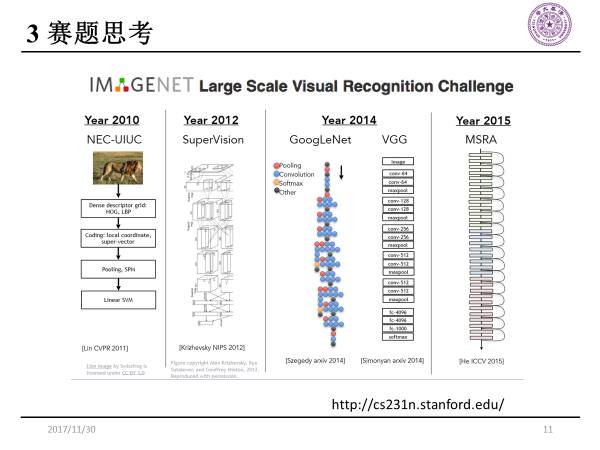
这是2010-2015年在imageNet上获胜的模型。2010年获胜的算法还是一些传统的图像处理方法,但从2012年之后,使用的模型都是深度卷积神经网络。
随着计算机性能的提升,网络的层数越来越深,2015年随着ResNet的问世,图像的层数达到了152层,甚至更多。
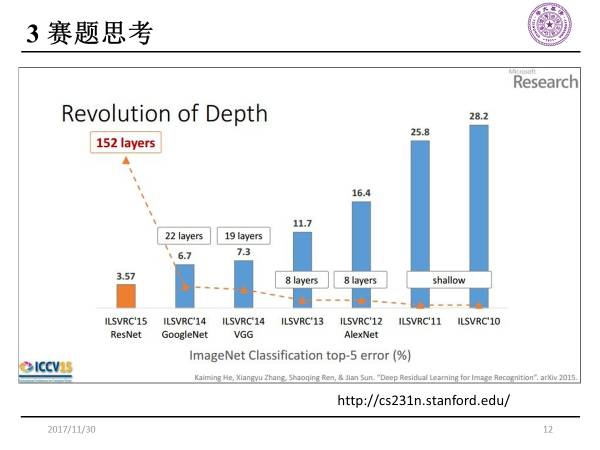
这是历年模型在ImageNet上的top-5分类误差结果。在使用了深度卷积神经网络之后,分类误差迅速下降,而且随着层数的增大,ResNet的分类误差已经降到了3.57%,超过了人眼的识别精度。
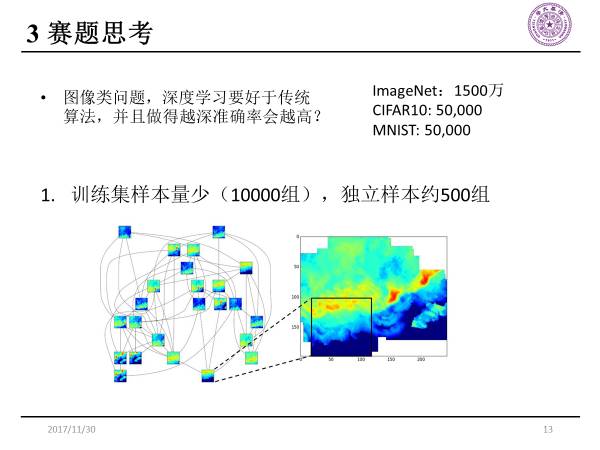
深度学习需要的样本数非常大,对于CIAR10和MNIST这样的数据集,它的样本数比较小,那么传统的图像算法的劣势也就没有那么明显。
左边这张图,它通过拼接可以得到右边这张更大的图像,最终独立样本少于10000组。
模型与样本数量的关系
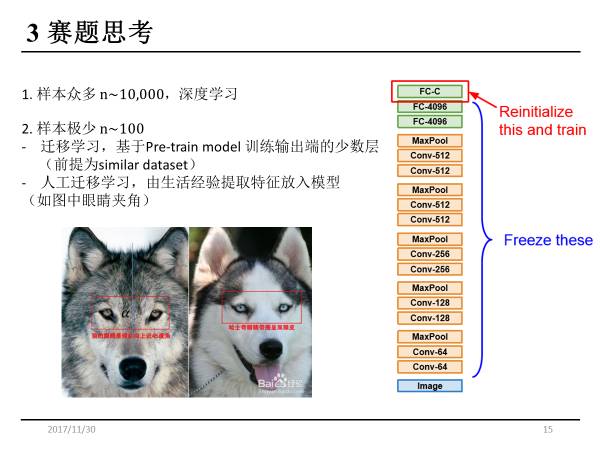
除了常规的迁徙学习,还可以做人工迁徙学习,将生活经验提取特征放入模型。即使样本数没有那么多,也能够获得比较好的结果。
当前问题
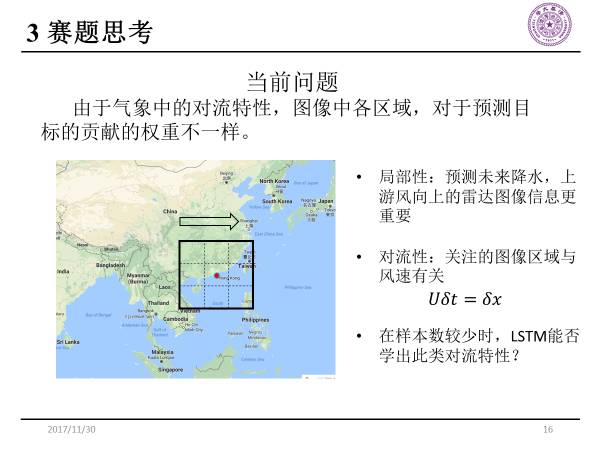
当地的对流速度乘以时间间隔,就等于云团在这个时间间隔内运动的位移X,通过对流性这样简单的公式,我们很轻易能想到;但是对于LSTM算法来说,在样本数较少时,它很难计算出此类对流性。
雷达反射率因子与降水量的关系

我们不能用改变数值(亮度)、图片的剪裁和翻转等等数据的增强方式来增加样本,这会破坏雷达图像它本身自带的物理属性。
4. 解决方案
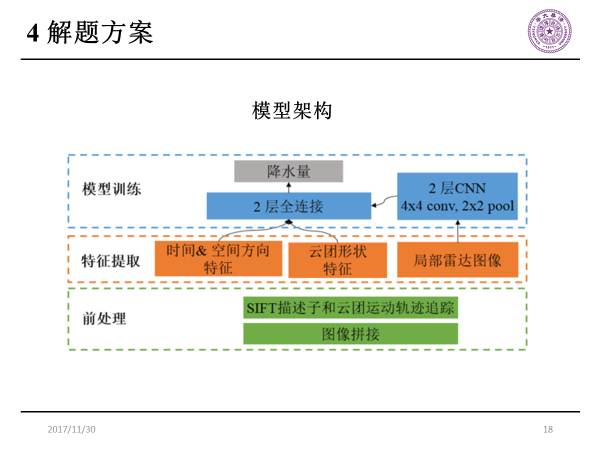
模型架构基于前面的赛题思考,我们形成了如下的模型架构:
前处理阶段:首先利用部分图像有重叠区域的特性,去做图像拼接,然后在拼接的图像上通过关键点的SIFT描述子去找时间方向的对应关系,再得出云团运动轨迹。
特征提取阶段:
第一类是时间&空间方向特征;
第二类是云团形状特征;
第三类是局部雷达图像。
模型训练阶段:首先将局部雷达图像输入到浅层的卷积神经网络,再经过两层卷积和池化拉平到一维向量,然后再与时间&空间方向特征、云团形状特征合并,共同输入到两层全连接神经网络去做最后的降水量预测。
5. 其他团队解题方案
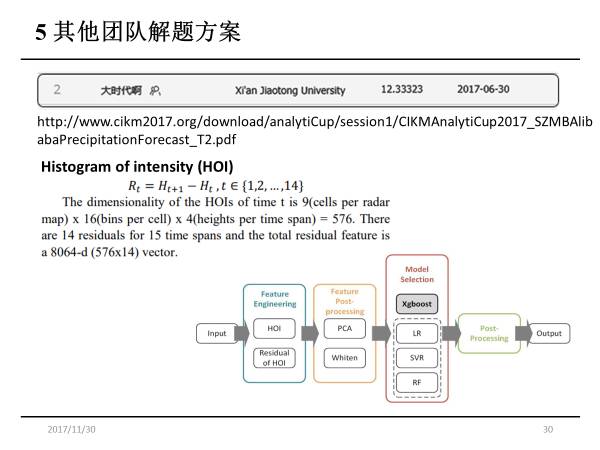
第二名的团队来自西安交大,他们使用的是传统的图像算法。他们先将图像分成3×3的子区域,在每个子区域都提取反射率直方图,以及这些直方图在时间方向上的残差,再做PC降维和去噪,输入到不同的机器学习模型,最后做模型的融合。
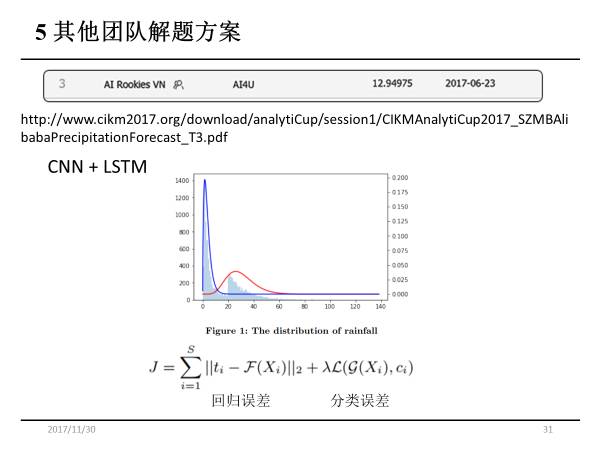
第三名的队伍来自越南,他们采用的是端到端学习模型,没有显式的特征提取步骤。他们首先分析降水量的分布,发现降水量的分布并不是高斯分布,而是出现两个峰值,所以他们把LOST拆成两部分:降水量的回归误差与不同降水类型的分类误差。
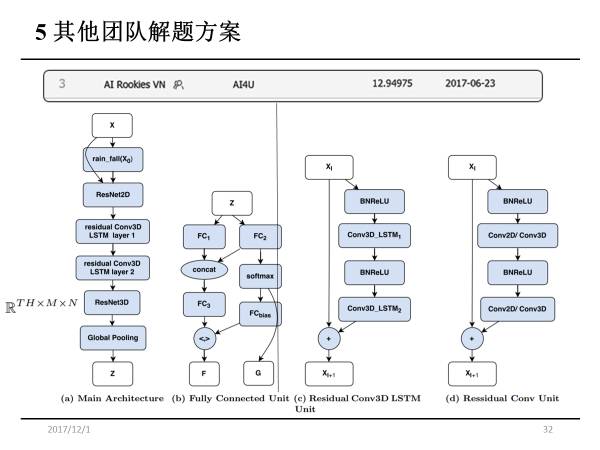
他们的模型是所有团队里面复杂度最大的,网络层数达到十层,但由于当前样本数较少,使用过于复杂的模型容易造成过拟合。
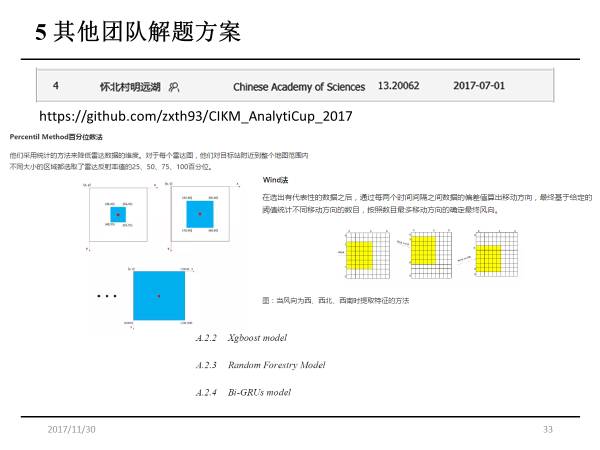
第四名的队伍来自中科院,他们在提取特征的时候也是用了传统的图像算法。提取的特征分成两类:
通过百分位数法提取局部不同大小区域的四个百分位点;
通过Wind法找到目标站点上游的图像区域作为输入,然后跟上一步提取出来的特征合并,再输入到三个不同模型当中,最后也做了模型的融合。
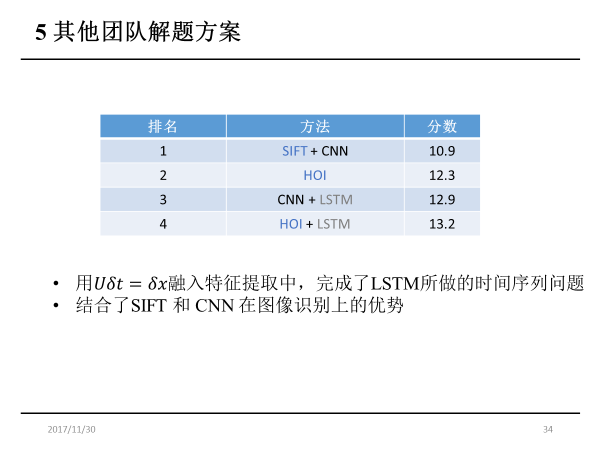
第三、第四名都用了LSTM,其实也是想去提取时间方向的特性,但是难度比较大,因为训练样本非常有限。我们团队的方法结合了SIFT和CNN在图像识别上的优势,同时基于对赛题涉及的物理问题的理解,寻找对应的表征量,最终在未做调参的情况下已能够大幅领先其他队伍。
6. 结论

本次竞赛代码及详细解题步骤:
https://github.com/yaoyichen/CIKM-Cup-2017
后台回复关键词“1129”,下载完整版PPT。

整理:陈龙
校对:朱江华峰
本期讲座的嘉宾姚易辰、李中杰同时也是数据派研究部的成员,想和他们成为小伙伴儿?点击文末“阅读原文”,加入数据派研究部吧!

姚易辰,数据派研究部成员,清华大学工程力学系博士生。天池大数据平台top10选手,曾获天池大数据IJCAI16口碑实体商户推荐赛冠军和菜鸟网络最后一公里极速配送冠军,擅长数据分析及图像处理。

李中杰,数据派研究部成员,清华热能系博士生。擅长数据分析处理及机器学习算法Python实现,对大数据技术充满热情,曾获天池大数据IJCAI16口碑实体商户推荐赛冠军和菜鸟网络最后一公里极速配送冠军。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:研究部的主力原创团队,成员在数据院的资源环境下通过打比赛(Kaggle、天池、SAS等)、做项目等实践手段提升自身技术素养并同时产出一问读懂、手把手教等系列文章;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目;
调研分析组:通过专访等方式调研大数据的应用场景,深入中国数据产业一线,探寻数据落地之路。
点击文末“阅读原文”,报名数据派研究部成员,总有一组适合你~
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。

点击“阅读原文”加入组织~


