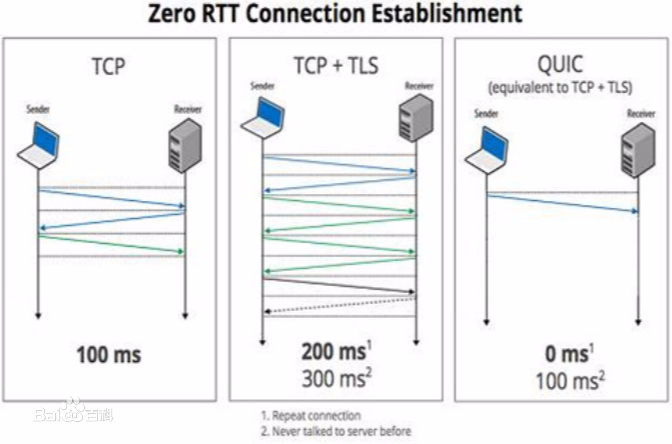
阿里淘系自研标准化协议库 XQUIC 首次公开:直播高峰期卡顿可降低 30%

XQUIC 为手机淘宝 APP 的用户带来丝般顺滑的网络体验:
在 RPC 请求场景,网络耗时降低 15% ;
在直播高峰期场景,卡顿率降低 30%、秒开率提升 2% ;
在短视频场景,卡顿率降低 20% 。
这是我们首次将这项新技术对外公开分享。
从以上提升效果可以看出,对 QUIC 的一个常见认知谬误:“QUIC 只对弱网场景有优化提升”是不准确的。实际上,QUIC 对于整体网络体验均有普遍提升,弱网场景由于基线较低、提升空间更显著。此外,在 5G 推广初期,基站部署不够密集的情况下,如何保证稳定有效带宽速率,是未来 2-3 年内手机视频应用将面临的重大挑战,而我们研发的 MPQUIC 将为这些挑战提供有效的解决方案。
本文将会重点介绍 XQUIC 的设计原理,面向业务场景的网络传输优化,以及面向 5G 的 Multipath QUIC 技术(多路径 QUIC)。
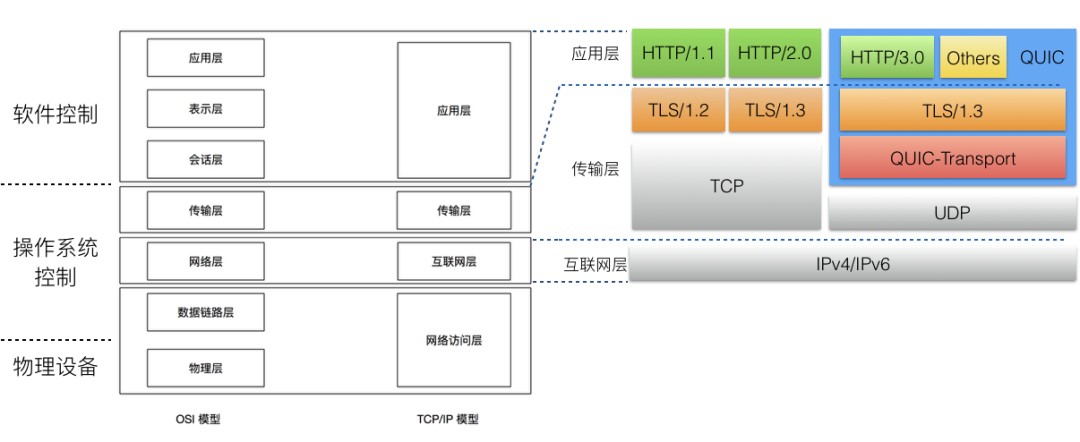
为了方便说明 QUIC 在网络通信协议栈中所处的位置及职能,我们简单回顾一下网络 OSI 模型(七层模型)和 TCP/IP 模型(四层模型)。从两套网络模型中可以看出,网络传输行为和策略主要由传输层来控制,而 TCP 作为过去 30 年最为流行和广泛使用的传输层协议,是由操作系统控制和实现的。
QUIC 是由 Google 从 2013 年开始研究的基于 UDP 的可靠传输协议,它最早的原型是 SPDY + QUIC-Crypto + Reliable UDP,后来经历了 SPDY [1] 转型为 2015 年 5 月 IETF 正式发布的 HTTP/2.0 [2] ,以及 2016 年 TLS/1.3 [3] 的正式发布。QUIC 在 IETF 的标准化工作组自 2016 年成立,考虑到 HTTP/2.0 和 TLS/1.3 的发布,它的核心协议族逐步进化为现在的 HTTP/3.0 + TLS/1.3 + QUIC-Transport 的组合。
众所周知,QUIC 具备多路复用 /0-RTT 握手 / 连接迁移等多种优点,然而在这些优势中,最关键的核心收益,当属 QUIC 将四 / 七层网络模型中控制传输行为的传输层,从内核态实现迁移到了用户态实现,由应用软件控制。这将带来 2 个巨大的优势:
(1) 迭代优化效率大大提升。以服务端角度而言,大型在线系统的内核升级成本往往是非常高的,考虑到稳定性等因素,升级周期从月到年为单位不等。以客户端角度而言,手机操作系统版本升级同样由厂商控制,升级周期同样难以把控。调整为用户态实现后,端到端的升级都非常方便,版本迭代周期以周为计(甚至更快)。
(2) 灵活适应不同业务场景的网络需求。在过去 4G 的飞速发展中,短视频、直播等新的业务场景随着基建提供的下行带宽增长开始出现,在流媒体传输对于稳定高带宽和低延迟的诉求下,TCP 纷纷被各类标准 / 私有 UDP 解决方案逐步替代,难以争得一席之地。背后的原因是,实现在内核态的 TCP,难以用一套拥塞控制算法 / 参数适应快速发展的各类业务场景。这一缺陷将在 5G 下变得更加显著。QUIC 则可将拥塞控制算法 / 参数调控到连接的粒度,针对同一个 APP 内的不同业务场景(例如 RPC/ 短视频 / 直播等)具备灵活适配 / 升级的能力。
在众多增强型 UDP 的选择中,QUIC 相较于其他方案最为通用,不仅具备对于 HTTP 系列的良好兼容性,同时其优秀的的分层设计,也使得它可以将传输层单独剥离作为 TCP 的替代方案,为其他应用层协议提供可靠 / 非可靠传输能力(是的,QUIC 也有非可靠传输草案设计)。
XQUIC 是阿里自研的 IETF QUIC 标准化实现,这个项目由淘系架构网关与基础网络团队发起和主导,当前有阿里云 CDN、达摩院 XG 实验室与 AIS 网络研究团队等多个团队参与其中。
现今 QUIC 有多家开源实现,为什么选择标准协议 + 自研实现的道路?我们从 14 年开始关注 Google 在 QUIC 上的实践(手机淘宝在 16 年全面应用 HTTP/2),从 17 年底开始跟进并尝试在电商场景落地 GQUIC [4] ,在 18 年底在手淘图片、短视频等场景落地 GQUIC 并拿到了一定的网络体验收益。然而在使用开源方案的过程中或多或少碰到了一些问题,Google 的实现是所有开源实现中最为成熟优秀的,然而由于 Chromium 复杂的运行环境和 C++ 实现的缘故,GQUIC 包大小在优化后仍然有 2.4M 左右,这使得我们在集成手淘时面临困难。在不影响互通性的前提下,我们进行了大量裁剪才勉强能够达到手淘集成的包大小要求,然而在版本升级的情况下难以持续迭代。其他的开源实现也有类似或其他的问题(例如依赖过多、无服务端实现、无稳定性保障等)。最终促使我们走上自研实现的道路。
为什么要选择 IETF QUIC [5] 标准化草案的协议版本?过去我们也尝试过自研私有协议,在端到端都由内部控制的场景下,私有协议的确是很方便的,但私有协议方案很难走出去建立一个生态圈 / 或者与其他的应用生态圈结合(遵循相同的标准化协议实现互联互通);从阿里作为云厂商的角度,私有协议也很难与外部客户打通;同时由于 IETF 开放讨论的工作模式,协议在安全性、扩展性上会有更全面充分的考量。
因此我们选择 IETF QUIC 标准化草案版本来落地。截止目前,IETF 工作组草案已经演化到 draft-29 版本(2020.6.10 发布),XQUIC 已经支持该版本,并能够与其他开源实现基于 draft-29 互通。
XQUIC 是 IETF QUIC 草案版本的一个 C 协议库实现,端到端的整体链路架构设计如下图所示。XQUIC 内部包含了 QUIC-Transport(传输层)、QUIC-TLS(加密层、与 TLS/1.3 对接)和 HTTP/3.0(应用层)的实现。在外部依赖方面,TLS/1.3 依赖了开源 boringssl 或 openssl 实现(两者 XQUIC 都做了支持、可用编译选项控制),除此之外无其他外部依赖。
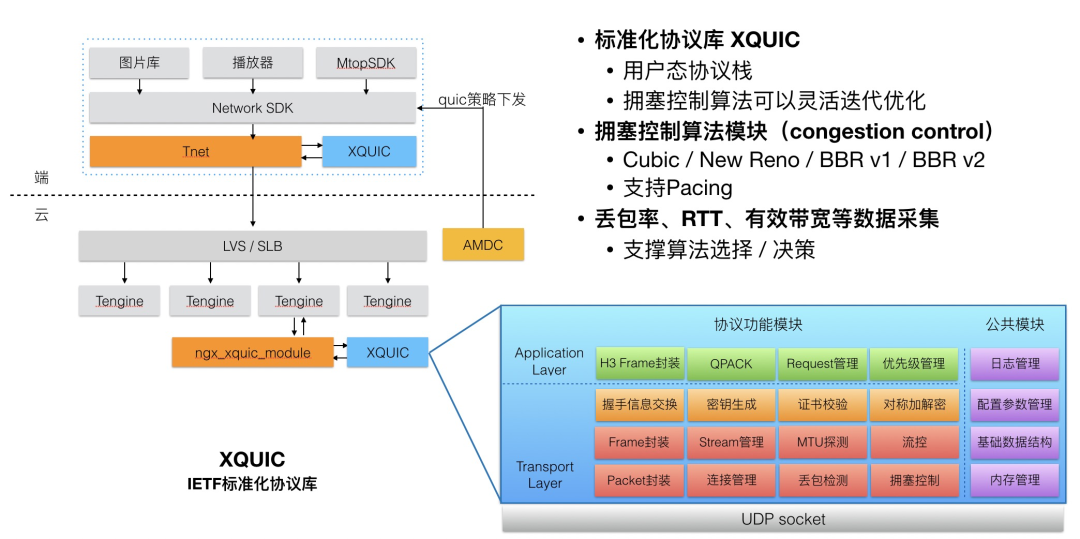
XQUIC 整体包大小在 900KB 左右(包含 boringssl 的情况下),对于客户端集成是较为轻量的(支持 Android/iOS)。服务端方面,由于阿里内部网关体系广泛使用 Tengine(Nginx 开源分支),我们开发了一个 ngx_xquic_module 用于适配 Tengine 服务端。协议的调度方面,由客户端网络库与调度服务 AMDC 配合完成,可以根据版本 / 地域 / 运营商 / 设备百分比进行协议调度。
XQUIC 传输层内部流程设计如下图,可以看到 XQUIC 内部的读写事件主流程。考虑到跨平台兼容性,UDP 收发接口由外部实现并注册回调接口。XQUIC 内部维护了每条连接的状态机、Stream 状态机,在 Stream 级别实现可靠传输(这也是根本上解决 TCP 头部阻塞的关键),并通过读事件通知的方式将数据投递给应用层。传输层 Stream 与应用层 HTTP/3 的 Request Stream 有一一映射关系,通过这样的方式解决 HTTP/2 over TCP 的头部阻塞问题。
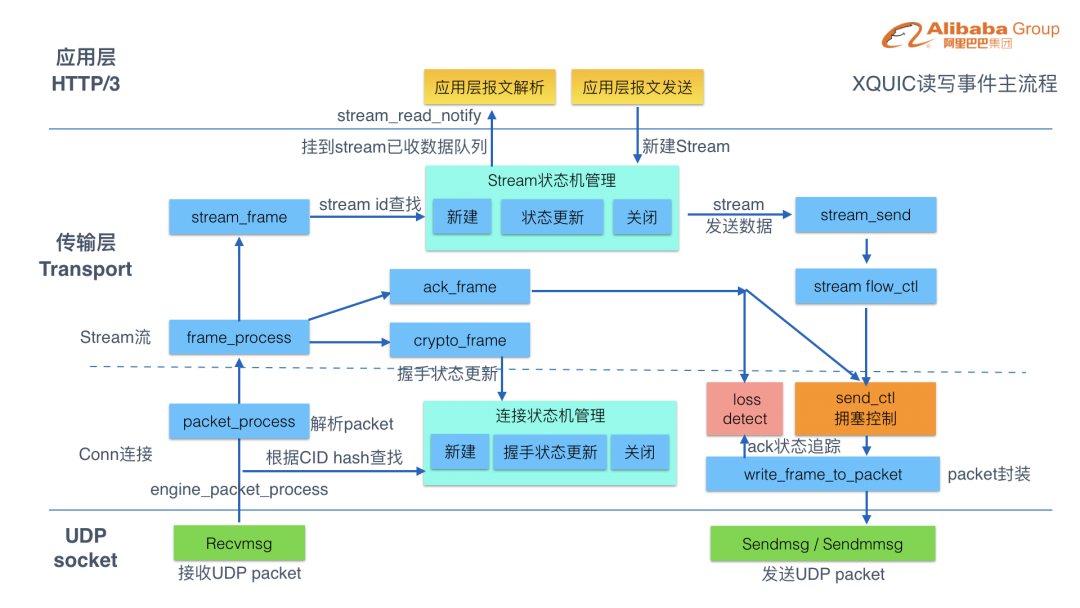
考虑到 IETF QUIC 传输层的设计可以独立剥离,并作为 TCP 的替代方案对接其他应用层协议,XQUIC 内部实现同样基于这样的分层方式,并对外提供两套原生接口:HTTP/3 请求应答接口 和 传输层独立接口(类似 TCP),使得例如 RTMP、上传协议等可以较为轻松地接入。

我们将 XQUIC 传输层的内部设计放大,其中拥塞控制算法模块,是决定传输行为和效率的核心模块之一。
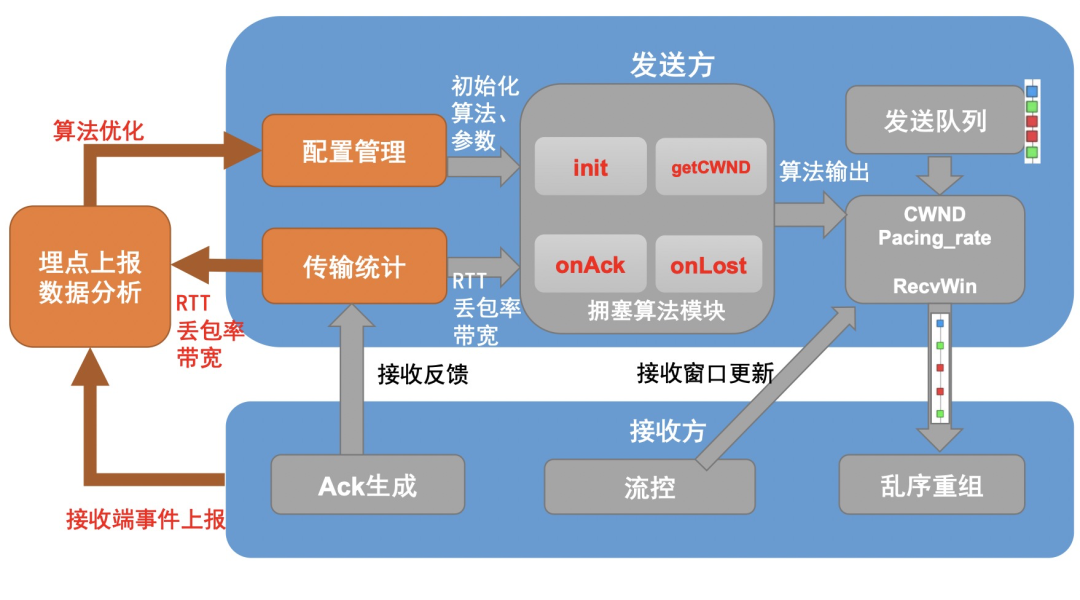
为了能够方便地实现多套拥塞控制算法,我们将拥塞控制算法流程抽象成 7 个回调接口,其中最核心的两个接口 onAck 和 onLost 用于让算法实现收到报文 ack 和检测到丢包时的处理逻辑。XQUIC 内部实现了多套拥塞控制算法,包括最常见的 Cubic、New Reno,以及音视频场景下比较流行的 BBR v1 和 v2,每种算法都只需要实现这 7 个回调接口即可实现完整算法逻辑。
为了方便用数据驱动网络体验优化,我们将连接的丢包率、RTT、带宽等信息通过埋点数据采样和分析的方式,结合每个版本的算法调整进行效果分析。同时在实验环境下模拟真实用户的网络环境分布,更好地预先评估算法调整对于网络体验的改进效果。
XQUIC 在 RPC 请求场景降低网络耗时 15%,在短视频场景下降低 20% 卡顿率,在直播场景高峰期降低 30% 卡顿率、提升 2% 秒开率(相对于 TCP)。以下基于当下非常火热的直播场景,介绍 XQUIC 如何面向业务场景优化网络体验。
部分用户网络环境比较差,存在直播拉流打开慢、卡顿问题。

这是 CDN 某节点上统计的丢包率和 RTT 分布数据,可以看到,有 5% 的连接丢包率超过 20%,0.5% 的连接 RTT 超过 500ms,如何优化网络较差用户的流媒体观看体验成为关键。
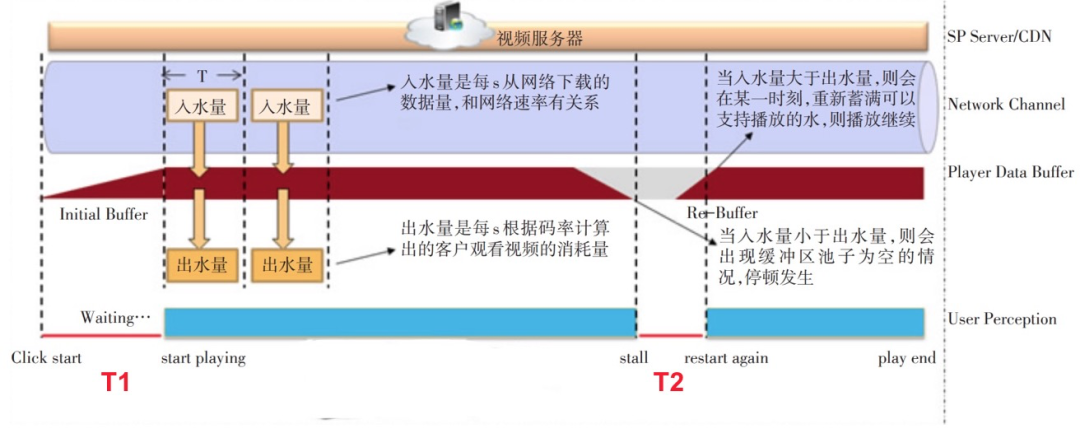
直播拉流可以理解为一个注水模型,上面是 CDN 服务器,中间是播放器缓冲区,可以理解成一个管道,下面是用户的体感,用户点击播放时,CDN 不断向管道里注水,当水量达到播放器初始 buffer 时,首帧画面出现,然后播放器以一定速率排水,当水被排完时,播放器画面出现停顿,当重新蓄满支持播放的水后,继续播放。
我们假设 Initial Buffer(首帧)为 100K(实际调整以真实情况为准),起播时间 T1 < 1s 记为秒开,停顿时间 T2 > 100ms 记为卡顿。
1. 优化目标
提升秒开:1s 内下载完 100K
降低卡顿:保持下载速率稳定,从而保持管道内始终有水
2. 核心思路
提升秒开核心 -- 快
高丢包率用户:加快重传
高延迟用户:减少往返次数
降低卡顿核心 -- 稳
优化拥塞算法机制,稳定高效地利用带宽
常见的拥塞算法可分为三类:
基于路径时延(如 Vegas、Westwood)
将路径时延上升作为发生拥塞的信号,在单一的网络环境下(所有连接都使用基于路径时延的拥塞算法)是可行的,但是在复杂的网络环境下,带宽容易被其他算法抢占,带宽利用率最低。
基于丢包(如 Cubic、NewReno)
将丢包作为发生拥塞的信号,其背后的逻辑是路由器、交换机的缓存都是有限的,拥塞会导致缓存用尽,进而队列中的一些报文会被丢弃。
拥塞会导致丢包,但是丢包却不一定拥塞导致的。事实上,丢包可以分为两类,一类是拥塞丢包,另一类是噪声丢包,特别是在无线网络环境中,数据以无线电的方式进行传递,无线路由器信号干扰、蜂窝信号不稳定等都会导致信号失真,最终数据链路层 CRC 校验失败将报文丢弃。
基于丢包的拥塞算法容易被噪声丢包干扰,在高丢包率高延迟的环境中带宽利用率较低。
基于带宽时延探测(如 BBR)
既然无法区分拥塞丢包和噪声丢包,那么就不以丢包作为拥塞信号,而是通过探测最大带宽和最小路径时延来确定路径的容量。抗丢包能力强,带宽利用率高。
三种类型的拥塞算法没有谁好谁坏,都是顺应当时的网络环境的产物,随着路由器、交换机缓存越来越大,无线网络的比例越来越高,基于路径时延和基于丢包的的拥塞算法就显得不合时宜了。对于流媒体、文件上传等对带宽需求比较大的场景,BBR 成为更优的选择。
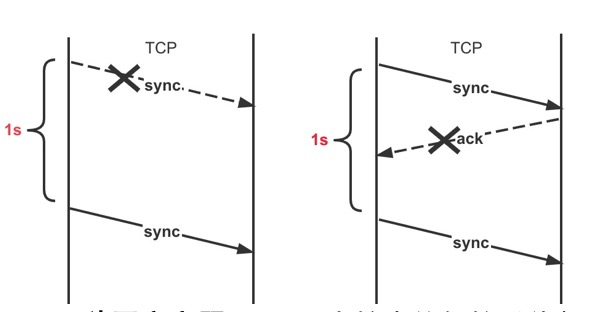
如图,TCP 在握手时,由于尚未收到对端的 ACK,无法计算路径 RTT,因此,RFC 定义了初始重传超时,当超过这个超时时间还未收到对端 ACK,就重发 sync 报文。
TCP 秒开率上限:Linux 内核中的初始重传超时为 1s (RFC6298, June 2011),3% 的丢包率意味着 TCP 秒开率理论上限为 97%,调低初始重传时间可以有效提升秒开率。
同理,如果你有一个 RPC 接口超时时间为 1s,那么在 3% 丢包率的环境下,接口成功率不会超过 97%。
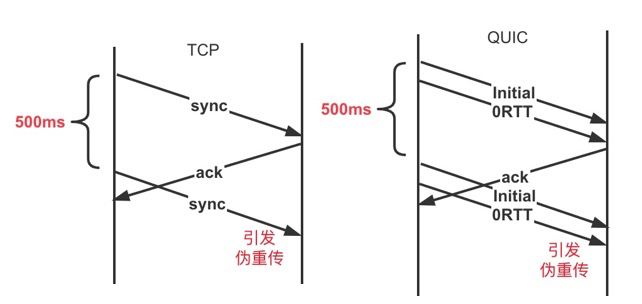
另一方面,调低初始重传超时会引发伪重传,需要根据用户 RTT 分布进行取舍,比如初始重传超时调低到 500ms,那么 RTT 大于 500ms 的用户在握手期间将会多发一个 sync 报文。
慢启动阶段 N 个 RTT 内的吞吐量(不考虑丢包):
T = init_cwnd * (2^N-1) * MSS, N = ⌊t / RTT ⌋
Linux 内核初始拥塞窗口 =10(RFC 6928,April 2013)
首帧 100KB,需要 4 个 RTT,如果 RTT>250ms,意味着必然无法秒开。在我们举的这个例子中,如果调整为 32,那么只需要 2 个 RTT。
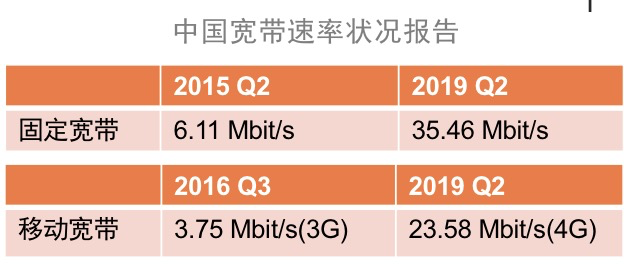
从 2015 到 2019,固定带宽翻了 4.8 倍。从 2016 到 2019,移动宽带翻了 5.3 倍。初始拥塞窗口从 10 调整为 32 在合理范围内。
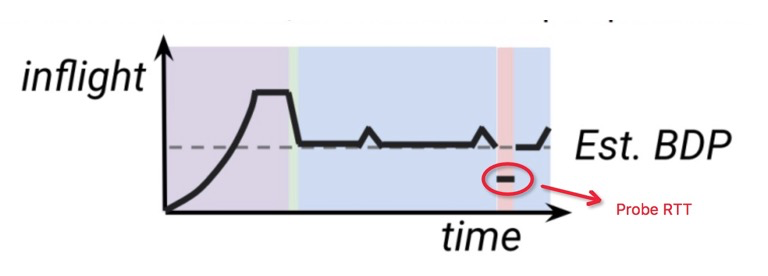
问题
BBR v1 的 ProbeRTT 阶段会把 inflight 降到 4*packet 并保持至少 200ms。会导致传输速率断崖式下跌,引起卡顿
10s 进入一次 ProbeRTT,无法适应 RTT 频繁变化的场景
优化方案
减少带宽突降:inflight 降到 4 * packet 改为降到 0.75 * Estimated_BDP
加快探测频率:ProbeRTT 进入频率 10s 改为 2.5s
推导过程
为什么是 0.75x?
Max Estimated_BDP = 1.25*realBDP
0.75 * Estimated_BDP = 0.75 * 1.25 * realBDP = 0.9375* realBDP
保证 inflight < realBDP, 确保 RTT 准确性。
为什么是 2.5s?
优化后 BBR 带宽利用率:(0.2s * 75% + 2.5s * 100%) / (0.2s+ 2.5s) = 98.1%
原生 BBR 带宽利用率:(0.2s * 0% + 10s * 100%) / (0.2s + 10s) = 98.0%
在整体带宽利用率不降低的情况下,调整到 2.5s 能达到更快感知网络变化的效果。
保证带宽利用率不低于原生 BBR 的前提下,使得发送更平滑,更快探测到 RTT 的变化。
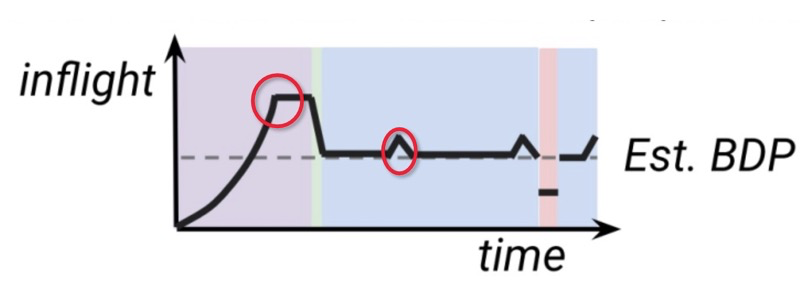
StartUp 阶段 2.89 和 ProbeBW 阶段 1.25 的增益系数导致拥塞丢包,引发卡顿和重传率升高(Cubic 重传率 3%, BBR 重传率 4%)重传导致带宽成本增加 1%。
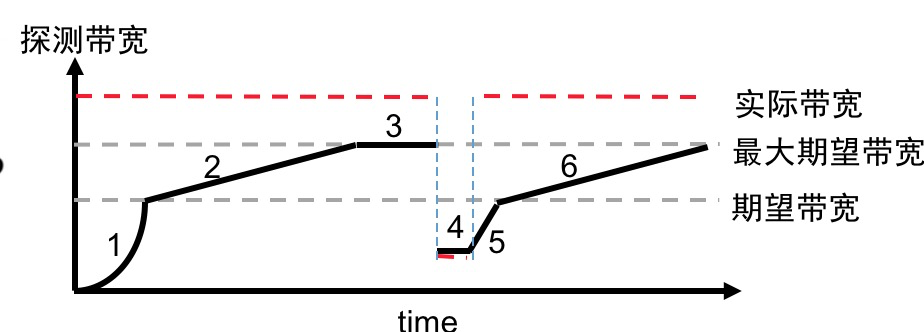
定义两个参数:
期望带宽:满足业务需要的最小带宽
最大期望带宽:能跑到的最大带宽
未达到期望带宽时采用较大的增益系数,较激进探测带宽。
达到期望带宽后采用较小的增益系数,较保守探测带宽。
成本角度:重传率由 4% 降到 3%,与 Cubic 一致,在不增加成本的前提下降低卡顿率。
另外,该策略可以推广到限速场景,如 5G 视频下载限速,避免浪费过多用户流量。
在直播拉流场景下与 TCP 相比较,高峰期卡顿率降低 30%+,秒开率提升 2%。
最后,我们看看 TCP 初始重传超时和初始拥塞窗口的发展历程:
初始重传时间
RFC1122 (October 1989) 为 3s
RFC6298 (June 2011) 改为 1s,理由为 97.5% 的连接 RTT<1s
初始拥塞窗口
RFC 3390 (October 2002) 为 min(4 * MSS, max(2 * MSS, 4380 bytes))(MSS=1460 时为 3)
RFC 6928 (April 2013) 改为 min (10 * MSS, max (2 * MSS, 14600))(MSS=1460 时为 10)—— 由 google 提出,理由为 90% of Google's search responses can fit in 10 segments (15KB).
首先 IETF RFC 是国际标准,需要考虑各个国家的网络情况,总会有一些网络较慢的地区。在 TCP 的 RFC 标准中,由于内核态实现不得不面临一刀切的参数选取方案,需要在考虑大盘分布的情况下兼顾长尾地区。
对比来看,QUIC 作为用户态协议栈,其灵活性相比内核态实现的 TCP 有很大优势。未来我们甚至有机会为每个用户训练出所在网络环境最合适的一套最优算法和参数,也许可以称之为千人千面的网络体验优化。
Multipath QUIC(多路径 QUIC)是当前 XQUIC 内部正在研究和尝试落地的一项新技术。
MPQUIC 可以同时利用 cellular 和 wifi 双通道进行数据传输,不仅提升了数据的下载和上传速度,同时也加强了应用对抗弱网的能力,从而进一步提高用户的端到端体验。此外,由于 5G 比 4G 的无线信号频率更高,5G 的信道衰落问题也会更严重。所以在 5G 部署初期,基站不够密集的情况下如何保证良好信号覆盖是未来 2-3 年内手机视频应用的重大挑战,而我们研发的 MPQUIC 将为这些挑战提供有效的解决方案。
Multipath QUIC 的前身是 MPTCP[6]。MPTCP 在 IETF 有相对成熟的一整套 RFC 标准,但同样由于其实现在内核态,导致落地成本高,规模化推广相对困难。业界也有对 MPTCP 的应用先例,例如苹果在 iOS 内核态实现了 MPTCP,并将其应用在 Siri、Apple Push Notification Service 和 Apple Music 中,用来保障消息的送达率、降低音乐播放的卡顿次数和卡顿时间。
我们在 18 年曾与手机厂商合作(MPTCP 同样需要厂商支持),并尝试搭建 demo 服务器验证端到端的优化效果,实验环境下测试对「收藏夹商品展示耗时」与「直播间首帧播放耗时」降低 12-50% 不等,然而最终由于落地成本太高并未规模化使用。由于 XQUIC 的用户态协议栈能够大大降低规模化落地的成本,现在我们重新尝试在 QUIC 的传输层实现多路径技术。
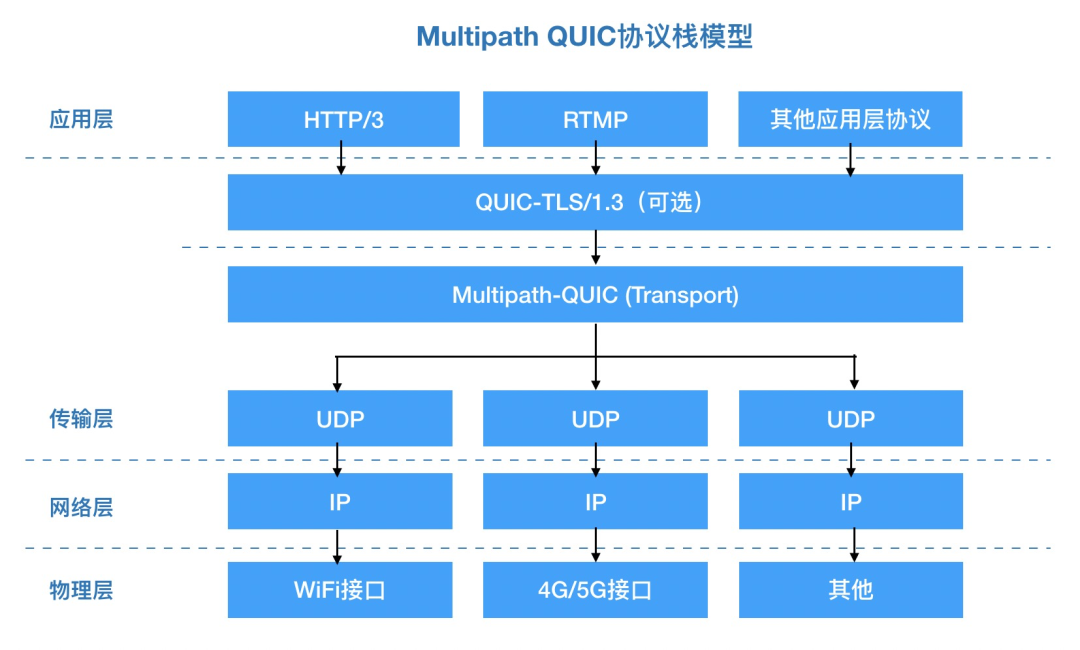
Multipath QUIC 对于移动端用户最核心的提升在于,通过在协议栈层面实现多通道技术,能够在移动端同时复用 Wi-Fi 和蜂窝移动网络,来达到突破单条物理链路带宽上限的效果;在单边网络信号强度弱的情况下,可以通过另一条通道补偿。适用的业务场景包括上传、短视频点播和直播,可以提升网络传输速率、降低文件传输耗时、提升视频的秒开和卡顿率。在 3GPP Release 17 标准中也有可能将 MPQUIC 引入作为 5G 标准的一部分 [7] 。
技术层面上,和 MPTCP 不同,我们自研的 MPQUIC 采取了全新的算法设计,这使得 MPQUIC 相比于 MPTCP 性能更加优化,解决了 slow path blocking 问题。在弱网中的性能比以往提升 30% 以上。


在推进 MPQUIC 技术落地的过程中,我们将会尝试在 IETF 工作组推进我们的方案作为 MPQUIC 草案的部分内容 [8] 。期望能够为 MPQUIC 的 RFC 标准制定和落地贡献一份力量。
我们论证了 QUIC 的核心优势在于用户态的传输层实现(面向业务场景具备灵活调优的能力),而非单一针对弱网的优化。在业务场景的扩展方面,除了 RPC、短视频、直播等场景外,XQUIC 还会对其他场景例如上传链路等进行优化。
在 5G 逐步开始普及的时代背景下,IETF QUIC 工作组预计也将在 2020 年底左右将 QUIC 草案发布为 RFC 标准,我们推测在 5G 大背景下 QUIC 的重要性将会进一步凸显。
对于 5G 下 eMBB(Enhanced Mobile Broadband)和 URLLC(Ultra Reliable Low Latency)带来的不同高带宽 / 低延迟业务场景,QUIC 将能够更好地发挥优势,贴合场景需求调整传输策略(拥塞控制算法、ACK/ 重传策略)。对于 5G 运营商提供的切片能力,QUIC 同样可以针对不同的切片适配合适的算法组合,使得基础设施提供的传输能力能够尽量达到最大化利用的效果。在 XQUIC 的传输层实现设计中,同样预留了所需的适配能力。
在 5G 推广期间,在基站部署不够密集的情况下,保障稳定的有效带宽将会是音视频类的应用场景面临的巨大挑战。Multipath QUIC 技术能够在用户态协议栈提供有效的解决方案,然而这项新技术仍然有很多难点需要攻克,同时 3GPP 标准化组织也在关注这一技术的发展情况。
阿里淘系技术架构团队计划在 2020 年底开源 XQUIC,期望能够帮助加速 IETF 标准化 QUIC 的推广,并期待更多的开源社区开发者参与到这个项目中来。
附录:参考文献
[1] SPDY - HTTP/2.0 原型,由 Google 主导的支持双工通信的应用层协议
[2] HTTP/2.0 - https://tools.ietf.org/html/rfc7540
[3] TLS/1.3 - https://tools.ietf.org/html/rfc8446
[4] GQUIC - 指 Google QUIC 版本,与 IETF QUIC 草案版本有一定差异
[5] IETF QUIC - 指 IETF QUIC 工作组正在推进的 QUIC 系列草案:https://datatracker.ietf.org/wg/quic/documents/,包括 QUIC-Transport、QUIC-TLS、QUIC-recovery、HTTP/3.0、QPACK 等一系列草案内容
[6] MPTCP - https://datatracker.ietf.org/wg/mptcp/documents/
[7] 3GPP 向 IETF 提出的需求说明 https://tools.ietf.org/html/draft-bonaventure-quic-atsss-overview-00
[8] MPQUIC - 我们正在尝试推进的草案 https://datatracker.ietf.org/doc/draft-an-multipath-quic-application-policy/
InfoQ 读者交流群上线啦!各位小伙伴可以扫描下方二维码,添加 InfoQ 小助手,回复关键字“进群”申请入群。大家可以和 InfoQ 读者一起畅所欲言,和编辑们零距离接触,超值的技术礼包等你领取,还有超值活动等你参加,快来加入我们吧!


点个在看少个 bug 👇